



來源:內容由半導體行業觀察編譯自nextplatform,謝謝。
在過去幾面,我們一直在談論硅光子學,以至於我們可能和你們中的許多人一樣,對它還沒有普及感到沮喪。但好消息是隨着電信號的進步,我們可能現在不得不轉向光芯片尋找幫助。
由於組件之間的電氣互連成本要低得多,這對價格/性能等式的價格分子部分來說是一個福音,盡管硅光子學在該等式的分母性能部分具有優勢。隨着時間的推移,隨着帶寬的增加,電信號變得越來越短,而且噪音也越來越大。這一天將不可避免地到來,我們將從電子轉向光子作爲電磁信號方法,從銅轉向光纖玻璃作爲信號介質。
這條曲线來自 Nvidia 首席科學家 Bill Dally 在 3 月份的光纖通信會議上發表的演講,很好地說明了這一點:
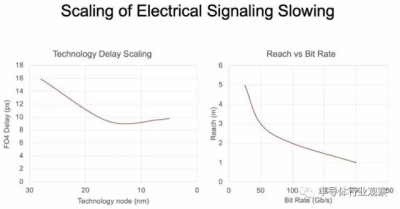
這些曲线沒有爭議,盡管你可以用材料科學魔法稍微彎曲它們。
幾周前,英偉達與 Ayar Labs 籤署了研發合作協議,我們坐下來與這家硅光子初創公司的首席執行官 Charlie Wuischpard 進行了交談,討論了兩人將开展的工作。Nvidia 參與了 Ayar Labs 今年早些時候進行的 C 輪融資,當時它籌集了 1.3 億美元來开發其帶外激光器和硅光子互連。Hewlett Packard Enterprise也在今年 2 月與 Ayar Labs 籤署了一項協議。爲了弄清楚如何將硅光子學引入 Slingshot 互連,他也是今年 4 月那輪融資的投資者。Ayar Labs 也得到了英特爾的早期支持,盡管英特爾希望將激光器嵌入芯片內部,而不是像 Ayar Labs 那樣從芯片外部泵入激光信號。(如果現在有什么是真的,那就是英特爾現在不能做錯任何事。所以英特爾用硅光子對衝它的賭注是件好事。)
在 4 月份的融資時,我們與 Wuischpard 詳細討論了硅光子學適合現代系統的地方——以及它尚不適合的地方,最近,我們得到了一些關於 Nvidia 可能專門开發的東西的提示。
我們隨後了解到 Dally 在 OFC 2022 上所做的上述演示,該演示非常具體地概述了使用密集波分復用 (DWDM:dense wave division multiplexing) 的共同封裝光學器件的目標,以及如何將硅光子學用作交叉連接機架的傳輸和機架的 GPU 計算引擎。
該演示文稿展示了一個未命名的概念機器,例如Dally 的團隊早在 2010 年开發的“Echelon”概念百億億次系統,我們在 2012 年就聽說了。該機器有特殊的數學引擎——不是 GPU——它們之間具有高基數電氣切換和 Cray “Aries” 機器機架之間的光學互連。而且那台 Echelon 機器顯然從未商業化,而 Nvidia 取而代之的是 Dally 在 Nvidia Research 研究的 NVSwitch 內存互連,並提早將其投入生產,以制造本質上由fat多端口 InfiniBand 互連的大型iron NUMA GPU 處理器復合體代替pipes。
在最初的基於 NVSwitch 的 DGX 系統中,Nvidia 只能使用“Volta”V100 GPU 加速器在單個圖像中擴展到 16 個 GPU,而使用“Ampere”A100 GPU 加速器時,Nvidia 不得不將每個 GPU 的帶寬加倍,因此必須將 NVSwitch 的基數減少兩倍,因此只能將八個 GPU 組合成一個圖像。借助今年早些時候宣布的 NVSwitches 的leaf/spine 網絡以及將於今年晚些時候發貨的“Hopper”H100 GPU 加速器,Nvidia 可以將 256 個 GPU 組合成一個內存結構,這是一個巨大的改進因素。
但歸根結底,作爲 DGX H100 SuperPOD 核心的 NVSwitch 結構本質上仍然是一種創建放大 NUMA 機器的方法,而且它絕對受到電纜布线的限制。而且 NVSwitch 的規模,即使是 Hopper 一代,也比不上超大規模生產商爲運行最大的 AI 工作負載而捆綁在一起的數萬個 GPU。
“我不能談太多細節,”Wuischpard 笑着告訴The Next Platform。“你知道,我們是一個物理層解決方案,在軟件和 GPU、內存和 CPU 之間的編排方面,還有很多東西要超越它。我們不參與任何這些事情。因此,我想你可以將我們視爲未來的物理支持。這是一種多階段的方法。這不僅僅是一個踢輪胎的練習。但我們必須在一些參數範圍內證明自己,我們必須達到一些裏程碑。”
我們希望這能澄清這一點。
無論如何,現在讓我們轉向 Dally 在 OFC 2022 上的演講,該演講跳到了未來的 GPU 加速系統與硅光子互連的樣子。在我們开始討論之前,讓我們看看 GPU 或交換機之間的帶寬和功率限制、它們連接的印刷電路板以及它們可能被匯集到的機櫃,這爲硅光子互連奠定了基礎:
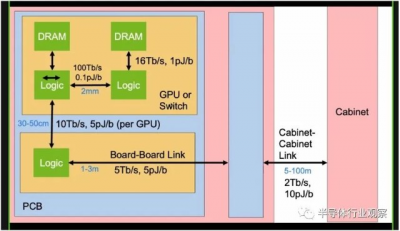
規則很簡單,鏈路越短,帶寬就越高,移位所消耗的功耗就越低。下表列出了中介層、印刷電路板、共封裝光學器件、電纜和有源光纜的相對功率、成本、密度和每一個,所有這些都是構成現代系統不同層次的電线。
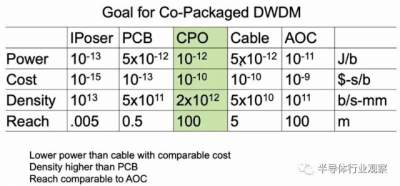
使用 DWDM 的共同封裝光學器件的目標是具有比電纜更低的功耗,但成本相似,具有與有源電纜相當的範圍,並提供與印刷電路板相當的信號密度。
以下是 Dally 對 DWDM 信號的示意圖:
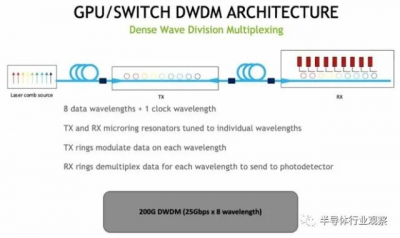
下面是 GPU 和 NVSwitch 如何使用光學引擎將電信號轉換爲光學信號以創建 GPU 的 NVSwitch 網絡的框圖:
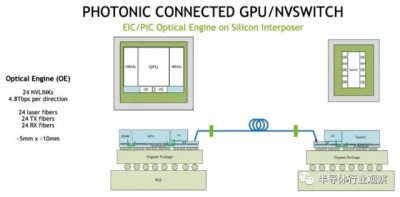
每個光學引擎有 24 根光纖,它們最初將以 200 Gb/秒的信號速率運行,總帶寬爲 4.8 Tb/秒。每個 GPU 都有一對這樣的設備,可以爲其提供進出 NVSwitch 結構的雙向帶寬。因此,具有六個光學引擎的 NVSwitch 的原始速率爲 28.8 Tb/秒,去除編碼开銷後爲 25.6 Tb/秒。
以下是 Nvidia 硅光子概念機中設備組件之間各種障礙的能耗如何計算:
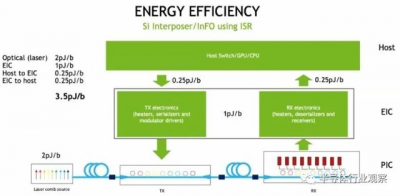
在 GPU 和交換機之間移入和移出數據的每比特 3.5 皮焦耳與 Dally 在上表中設定的目標完全一致。我們懷疑成本仍然必須降低才能使計算引擎可以接受共同封裝的光學器件,但是這裏正在進行大量工作,每個人都非常積極。
當前 DGX-A100 系統上的嵌入式 NVSwitch 結構上使用的電信號傳輸範圍約爲 300 釐米,並以每比特 8 皮焦耳的速度傳輸數據。目標是硅光子學以一半的能量做到這一點,並將設備之間的距離提高到 100 米。
發生這種情況時,您可以分解架構中的 GPU 和交換機——雖然 Nvidia 的概念機沒有顯示這一點,但 CPU 也可以具有光學引擎,並且它們也可以分解。
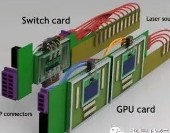
以下是帶有共同封裝光學器件的 GPU 和交換機的外觀:
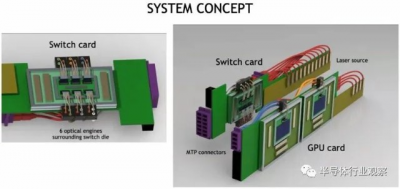
以下是具有 CPO 鏈接的 GPU 和 NVSwitch 的聚合方式:
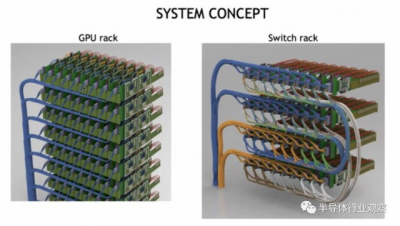
外部激光源佔用了大量空間,但這也意味着機架的密度可以大大降低,因爲設備之間的連接可以更長。這將使冷卻更容易,並且激光器也可以更換。如果所有這些東西都運行得更冷,激光也會更好地工作。密度被高估了,並且在許多情況下,例如 DGX 系統,機器最終會變得非常熱,以至於您無論如何只能安裝一半的機架,因爲功率密度和冷卻需求超出了大多數數據中心的處理能力。
您會注意到,上面的 GPU 和开關行是垂直放置的,這有助於冷卻。而且它們也沒有安裝在帶有 sockets的巨型印刷電路板上,這將有助於降低整體系統成本,以幫助支付使用光學互連的費用。
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:硅光芯片如何連接到GPU?英偉達是這樣看的!
地址:https://www.breakthing.com/post/14697.html