




$天娛數科(SZ002354)$
谷歌“狂飆”在生成式AI賽道 最新模型可憑文字、圖片“創作”音樂
- 相關股票/基金:
- 谷歌-A +1.90%
- 谷歌-C +1.56%
在生成式AI模型的賽道上,谷歌正一路“狂飆”。繼文字生成AI模型Wordcraft、視頻生成工具Imagen Video之後,谷歌將生成式AI的應用場景擴展到了音樂圈。
當地時間1月27日,谷歌發布了新的AI模型——MusicLM,該模型可以從文本甚至圖像中生成高保真音樂,也就是說可以把一段文字、一幅畫轉化爲歌曲,且曲風多樣。
谷歌在相關論文中展示了大量案例,如輸入字幕“雷鬼和電子舞曲的融合,帶有空曠的、超凡脫俗的聲音,引發迷失在太空中的體驗,音樂的設計旨在喚起一種驚奇和敬畏的感覺,同時又適合跳舞”,MusicLM便生成了30秒的電子音樂。

又如以世界名畫《跨越阿爾卑斯山聖伯納隘口的拿破侖》爲“題”,MusicLM生成的音樂莊重典雅,將冬日的凌厲肅殺和英雄主義色彩體現地淋漓盡致。寫實油畫之外,《舞蹈》《吶喊》《格爾尼卡》《星空》等抽象派畫作均可爲題。
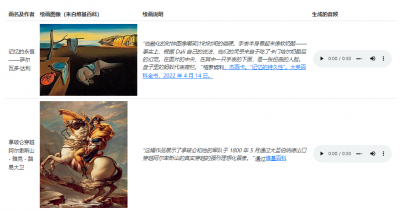
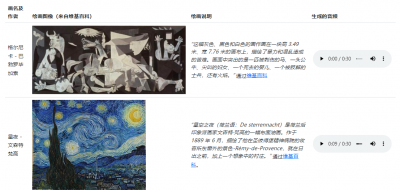
MusicLM甚至來個音樂串燒,在故事模式下將不同風格的曲子混雜在一起。即便要求生成5分鐘時長的音樂,MusicLM也不在話下。
另外,MusicLM具備強大的輔助功能,可以規定具體的樂器、地點、流派、年代、音樂家演奏水平等,對生成的音樂質量進行調整,從而讓一段曲子幻化出多個版本。
MusicLM並非第一個生成歌曲的AI模型,同類型產品包括Riffusion、Dance Diffusion等,谷歌自己也發布過AudioML,時下最熱門的聊天機器人“ChatGPT”的研發者OpenAI則推出過Jukebox。
MusicLM有何獨到之處?
它其實是一個分層的序列到序列(Sequence-to-Sequence)模型。根據人工智能科學家Keunwoo Choi的說法,MusicLM結合了MuLan+AudioLM和MuLan+w2b-Bert+Soundstream等多個模型,可謂集大成者。
其中,AudioLM模型可視作MusicLM的前身,MusicLM就是利用了AudioLM的多階段自回歸建模作爲生成條件,可以通過文本描述,以24kHz的頻率生成音樂,並在幾分鐘內保持這個頻率。
相較而言,MusicLM的訓練數據更多。研究團隊引入了首個專門爲文本-音樂生成任務評估數據MusicCaps來解決任務缺乏評估數據的問題。MusicCaps由專業人士共建,涵蓋5500個音樂-文本對。
基於此,谷歌用280000小時的音樂數據集訓練出了MusicLM。
谷歌的實驗表明,MusicLM在音頻質量和對文本描述的遵守方面都優於以前的模型。
不過,MusicLM也有着所有生成式AI共同的風險——技術不完善、素材侵權、道德爭議等。
對於技術問題,比方說當要求MusicLM生成人聲時,技術上可行,但效果不佳,歌詞亂七八糟、意義不明的情況時有發生。MusicLM也會“偷懶”——起生成的音樂中,約有1%直接從訓練集的歌曲中復制。
另外,由AI系統生成的音樂到底算不算原創作品?可以受到版權保護嗎?能不能和“人造音樂”同台競技?相關爭議始終未有一致見解。
這些都是谷歌沒有對外發布MusicLM的原因。“我們承認該模型有盜用創意內容的潛在風險,我們強調,需要在未來开展更多工作來應對這些與音樂生成相關的風險。”谷歌發布的論文寫道。
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:谷歌“狂飆”在生成式AI賽道 最新模型可憑文字、圖片“創作”音樂
地址:https://www.breakthing.com/post/43068.html