




在英特爾最近的 DCAI 網絡研討會上,公司執行副總裁 Sandra Rivera 透露了英特爾第五代至強可擴展處理器 Emerald Rapids 的外觀。英特爾已決定通過僅使用 2 個大die設計 Emerald Rapids (EMR) 來回溯一代小芯片(chiplet)。
它的前一代產品 Sapphire Rapids (SPR) 有 4 個較小的die。與直覺相反,英特爾將其最高核心數配置中的小芯片數量從 4 個減少到 2 個。這會讓大多數人摸不着頭腦,因爲包括英特爾在內的每個人都在談論使用更小的die來分解小芯片以提高產量和擴展性能。
本文中,我們將更深入地了解英特爾對 Emerald Rapids (EMR) 所做的具體更改。我們將查看我們創建的平面圖,詳細說明工作負載性能、成本比較以及與 AMD 的競爭環境。此外,我們將詳細介紹 Sapphire Rapids 發生的巨大變化,但大多數人都忽視了這一變化。
Emerald Rapids的變化
英特爾這一代產品最大的變體 EMR-XCC,將核心數從 SPR 上的 60 個增加到 64 個。然而,封裝上共有 66 個物理內核,它們被分類以提高良率。英特爾並不打算像他們對 60 核 SPR 所做的那樣,將完全啓用的 66 核 EMR SKU 產品化。EMR 結合了兩個 33 核die,而 SPR 使用四個 15 核die。
另一個主要變化是英特爾顯著增加了共享 L3 緩存,從 SPR 上的每個內核 1.875MB 到 EMR 上高達 5MB 的每個內核!這意味着高端 SKU 在所有內核中都配備了 320MB 的共享 L3 緩存,是 SPR 提供的最大值的 2.84 倍。Local Snoop Filters 和 Remote Snoop Filters 也相應增加,以適應大型 L3 緩存的增加(LSF – 3.75MB/核心,RSF – 1MB/核心)。
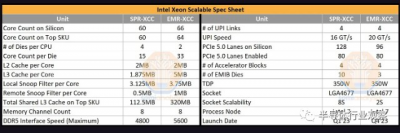
DDR5 內存支持已從 4800 MT/s 增加到 5600 MT/s。插槽間通信(inter-socket)的 UPI 速度已從 16 GT/s 升級到 20 GT/s。奇怪的是,盡管插槽間速度更高,但支持的插槽總數從 8 個減少到 2 個。這樣做可能是爲了加快上市時間,因爲它只影響 AMD 無論如何都沒有參與競爭的一小部分市場。所有這些都與同一 LGA 4677 Socket E1 上的現有“Eagle Stream”平台直接兼容。PCIe 通道數保持不變,盡管最終添加了 CXL 分叉支持,這對 Sapphire Rapids 來說是一個痛處。
仔細觀察封裝,我們注意到英特爾能夠將更多內核和更多緩存塞入比 SPR 更小的區域!包括劃线(scribe lines)在內,兩個 763.03 平方毫米的裸片總面積爲 1,526.05 平方毫米,而 SPR 使用四個 393.88 平方毫米的裸片,總面積爲 1,575.52 平方毫米。EMR 縮小了 3.14%,但印刷內核(printed cores )增加了 10%,L3 緩存增加了 2.84 倍。這一令人印象深刻的壯舉部分是通過減少小芯片的數量實現的。當然,還有其他因素在起作用,有助於減少 EMR 的面積。
在爲 EMR 畫平面圖模型時,我們發現不可能將必要的功能塞進一個足夠小的區域以匹配 Intel 所揭示的內容。我們使用 SPR 中的組件作爲參考,但它最終變得太大了。這是因爲英特爾優化了其物理設計,使一些功能更加緊湊和面積效率更高,從而進一步縮小面積。更重要的是,這不是英特爾第一次改變物理設計以節省面積。
Sapphire Rapids的die微縮
盡管沒有太多公开討論,英特爾還在生產 E5 步進過程中最黑暗的日子裏對 Sapphire Rapids 進行了徹底的重新設計。信不信由你,Sapphire Rapids 小芯片有兩種不同的物理設計和芯片尺寸。

Raja Koduri 在 2021 年架構日展示了更大、更早的 SPR 版本,並且還出現在第三方拆解的早期工程樣本的第中。更小、更新的SPR變體在 Vision 2022 上展示,它被最終生產 SKU 使用。
英特爾展示了兩個版本的 SPR 的晶圓。較早的修訂版每個晶圓有 137 個裸片,而最終版本有 148 個。這需要一直回到芯片的平面規劃和物理設計。一個主要的好處是,它通過在每個晶圓上多制造 8% 的裸片,改善了 Sapphire Rapids 的成本結構。
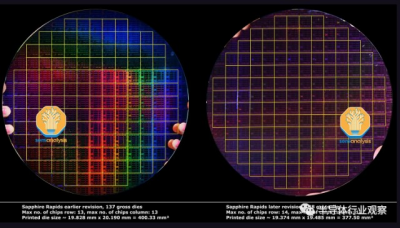
在長期提出期間所做的大量硅修改中,我們發現英特爾改變了核心和外圍的物理設計和布局,以實現 5.7% 的面積減少。I/O 區域(North Cap)已重新實現,die高度減少了 0.46 毫米。I/O 塊之間的水平間距也得到了優化,die寬度節省了 0.46 毫米。容納 CPU 核心、高速緩存和內存控制器的網狀區塊區域也必須縮小 3.43% 的面積以適應更緊湊的布局規劃,同時調整減少 CPU 核心寬度和tile間距。

一般來說,設計團隊在發布前爲同一產品制作 2 種不同布局和裸片尺寸的情況很少見,因爲上市時間至關重要。也許 Sapphire Rapids 的多次延誤給了他們足夠的時間來尋求額外的面積節省。如果它是按照最初的 2021 年目標推出的,我們可能不會看到這個較小的修訂版,至少在最初是這樣。
同樣,英特爾對 EMR 應用了相同的布局優化原則,特別是在容納巨大的 L3 時。在這裏,我們展示了對核心和mesh tile進行更改的模型,包括在核心上方明顯更高的 SRAM 部分,以容納額外的 L3 緩存和 Snoop Filters。這樣一來,每個核心tile的面積增加了 11.8%。得益於 SRAM 物理設計的優化,英特爾能夠容納 3200 KB 以上的 L3 緩存以及更大的 LSF,並通過僅增加 1.41 mm 來將 RSF 翻倍。

Emerald Rapids 的平面圖
以下是 EMR-XCC 的平面布置圖。在兩個die中,66 核加上 I/O 部分在 7x14 網狀互連網絡上捆綁在一起。

在中間,網狀網絡在 EMIB 上跨越片外邊界(off-chip boundary) 7 次。這與 SPR 上跨四個芯片的 8x12 網格和 20 個芯片外交叉點形成對比。此拓撲更改的影響將在下面的性能部分中介紹。
從上面顯示的布局中,我們可以看出,盡管這兩個小芯片非常相似,但它們實際上使用了不同的流片和掩模組,英特爾再次像 SPR 那樣使用鏡像芯片。使用旋轉 180 度的相同裸片將使掩模組要求減半,但會使跨 EMIB 的多裸片結構 IO 復雜化。

說到 EMIB,硅橋( silicon bridges)的數量從 10 個大幅減少到 3 個,中間的硅橋更寬以適應 3 個網格柱。奇數個網格列也出現在單片版本的 SPR上,這也可能是他們必須對die進行鏡像的部分原因,因爲旋轉會幹擾對齊並使導线交叉復雜化。
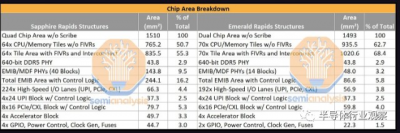
通過這種新布局,我們可以看到小芯片重新聚合的真正好處。用於小芯片接口的總面積百分比從 SPR 上的總die面積的 16.2% 變爲 EMR 上的僅 5.8%。或者,我們可以查看核心區域利用率,即總die面積中有多少用於計算核心和緩存。這從 SPR 的50.67% 上升到 EMR 的好得多的 62.65%。這一收益的部分原因還在於 EMR 上較少的物理 IO,因爲 SPR 具有更多的 PCIe 通道,這些通道僅在單插槽工作站段上啓用。
如果您的良率很好,爲什么在可以使用更少、更大的裸片時浪費冗余 IO 和小芯片互連的面積?英特爾傳奇的 10nm 工藝從 2017 年的以來已經走了很長一段路,現在在其更名後的intel 7 形式中取得了相當不錯的成績。
成本,不是你想的那樣
所有這些關於布局優化和在更小的總硅面積中塞入更多內核和緩存的討論會讓您相信 EMR 的制造成本低於 SPR。事實並非如此。
從根本上說,大矩形不能整齊地放在圓形晶圓上。回到每個晶圓的裸片總數,我們估計 EMR-XCC 晶圓布局與 SPR-MCC 相匹配,這意味着每個晶圓有 68 個裸片。假設完美的良率和芯片可回收性,EMR 只能在每個晶圓上制造 34 個 CPU,低於每個 SPR 晶圓上的 37 個 CPU。一旦將完美良率以外的任何因素考慮在內,EMR 的情況就會變得更糟,這表明使用更大die的劣勢。
盡管每個 CPU 使用的硅面積較少,但 EMR 實際上的生產成本高於 SPR。
公平地說,如果我們要將布局更改的好處與成本隔離开來,我們應該將 EMR 與每核 5MB L3 的假設 SPR 進行比較。對於這個 4 小芯片變體,根據這個更高的理論芯片的面積估計導致每個晶圓有 136 個總die或每個晶圓有 34 個 CPU,使其與實際的 2 小芯片設計相同。此外,將 EMIB 芯片的數量從 10 個減少到 3 個肯定會提高 2-chiplet 解決方案的封裝成本和產量。

那么,如果布局變化和小芯片減少對降低成本沒有幫助,那么 EMR 的主要驅動因素是什么?
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:英特爾,如何玩轉Chiplet?
地址:https://www.breakthing.com/post/56122.html