




新華三智算中心全棧解決方案能力
新華三基於對AIGC全流程技術需求的深刻理解,推出了智算中心全棧解決方案,依靠MLOps、數據管理、版本化管理以及彈性架構等優勢,可爲廣大互聯網用戶提供業界最全最細致的AI支撐能力。
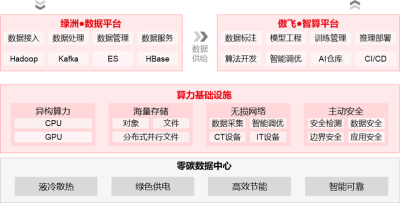
一、基於綠洲數據平台可以提供數據全流水线管理能力,配合傲飛智算平台可以支持從訓練到推理的全生命周期流水线,提供精細化的自動化數據處理以及精細化的模型性能監控調優。
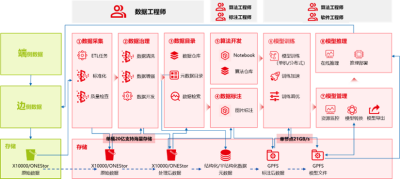
整個AI集群的運轉過程可以大致用上圖概括:數據採集→數據治理→數據目錄→數據標注→算法开發→模型訓練→模型管理→模型推理。其中是由數據平台提供相應能力,後續的一系列流程則需要智算平台進行支撐。值得一提的是,傲飛智算平台可以通過相關性能指標(模型准確率/GPU內存佔用/模型大小/量/延時)進行模型量化:解釋在模型調優過程中,數據的變化以及算法的變化,從而使得AI任務端到端可視化。
二、算力基礎設施層作爲整個AI集群的執行點,需要GPU計算、網絡以及存儲等產品的全方位支撐,結合AI集群的運轉流程,其整體架構如下所示:
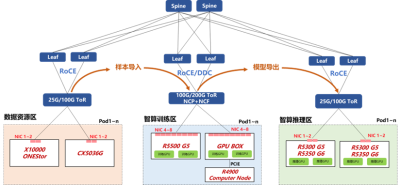
該架構整體上分爲3個區域:數據資源區、智算訓練區以及智算推理區。從數據採集到數據標注均在數據資源完成,而模型訓練、模型管理以及模型推理則在另外兩個區域完成。數據資源區與智算訓練區需要用高性能網絡作FullMesh互聯,智算訓練區的不同GPU節點同樣需要FullMesh互聯。接下來我們依次看下新華三全面的基礎設施能力:
智算訓練集群
組建訓練集群的服務器大多使用搭載專用GPU模組的標准機,如H3C UniServer R5500 G5。H3C UniServer R5500 G5支持Intel Whitley平台和AMD Milan雙平台,最多可以提供128個CPU核心,可最大程度滿足訓練集群的CPU算力需求。
訓練集群將預訓練數據集拉取到本地後需要先存儲到NVMe SSD裏,基於GDS(GDS, GPU Direct Storage),可以通過PCIe Switch將NVMe SSD裏的數據直接讀取到GPU顯存裏。
GPU在訓練過程中會進行頻繁通信,包括P2P通信(1對1)和Collective通信(1對多或多對多)。在節點內,GPU之間的通信互聯帶寬可達400GB/s。在節點之間,GPU通信使用RDMA網絡,通過GDR(GDR, GPU Direct RDMA)技術支持, RDMA網卡可以繞過CPU、內存,直接從遠端節點讀取數據到GPU顯存。
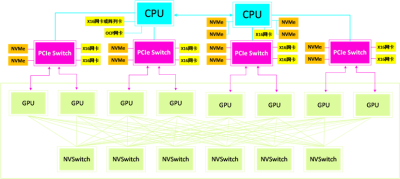
根據數據集、模型大小的不同,會產生多種訓練方式,比如數據並行、模型並行、流水线並行、混合並行等。根據訓練方式的不同,訓練集群的GPU節點也會進行對應的拆分、組合。爲了最大程度復用訓練集群資源,在選型時需要保證拓撲均衡的服務器系統架構,一般NVMe硬盤:PCIe Switch:RDMA網卡需要滿足4:4:4或8:4:8的配比關系;此外,在集群組網時,推薦使用FullMesh的網絡架構。
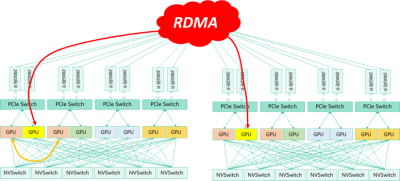
H3C UniServer R5500 G5最大支持12個U.2 NVMe SSD(8個支持GDS)、10個X16網卡(8個支持GDR),可靈活支持4張NVMe SSD/網卡或8張NVMe SSD/網卡的配置,當前均有方案在客戶側落地。
一些大型互聯網公司還會使用自研GPU Box搭配計算節點的方式組建訓練集群,GPU Box裏面會搭載專用GPU模組或其他廠商的OAM模組。OAM(OAM, OCP Accelerator Module)是开源的GPU模塊,由OCP社區服務器項目組下的OAI(OAI, Open Accelerator Infrastructure)小組开發並制定標准。
OAM包括GPU和UBB,UBB(UBB, Universal Baseboard)是承載GPU的基板,可以在服務器整機中兼容不同廠家的GPU。新華三是OAI 2.0規範制定的重要參與者,並計劃後續在R5500 G6上开發可支持不同廠家GPU的OAM模組。
在2023年初,新華三發布了新一代GPU機型R5500 G6,支持Intel Eagle Stream和AMD Genoa平台,PCIe 5.0及400GE網絡的加持,相信會給客戶帶來更高的算力提升。
智算推理集群
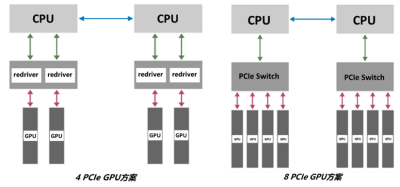
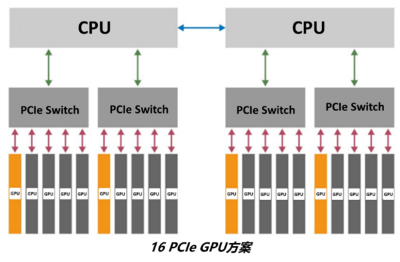
GPU推理集群的規模主要取決於業務預期的並發請求,一般會多機多卡多實例部署。針對大規模推理場景,H3C UniServer R5300 G5支持多種類型的GPU方案,包括4 PCIe GPU方案、8 PCIe GPU方案和16 PCIe GPU方案,以應對不同客戶不同算力的推理集群搭建需求。
方案
優勢
4 PCIe GPU方案
支持最多4個雙寬GPU
CPU to GPU帶寬大,成本更優
散熱和功耗比2U方案要低
8 PCIe GPU方案
支持最多8個雙寬GPU
P2P性能好,延時低
16 PCIe GPU方案
支持最多20個單寬GPU
適合密集型推理場景
在2022年11月份,新華三發布了基於AMD Genoa平台的GPU服務器R5350 G6,可實現90%的CPU性能提升和50%的內核數量提升;多種類型人工智能加速卡的支持,可應對人工智能不同場景下對異構算力的需求。此外,在2023年上半年,新華三還會發布基於Intel Eagle Stream平台的GPU服務器R5300 G6,請大家拭目以待。
高性能存儲
高性能存儲一般採用分布式並行文件存儲,如新華三CX系列存儲。新華三 CX系列存儲採用全對稱分布式架構,結合IBM Spectrum Scale(原名GPFS, General Parallel File System),可提供高帶寬、低延時的存儲服務。
高性能網絡
新華三提供了多種可選的高性能網絡方案,以供各用戶不同業務場景應用。
1
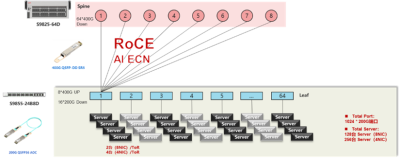
2級Clos TH4+TD4組網方案,最大提供1024個200G端口接入能力
2
2級Clos TH4+TH4組網方案,最大提供4096個200G端口接入能力
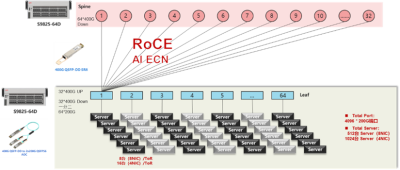
以上兩種方案均採用了以太網交換機RoCE組網方案,可以配合新華三自主研發的AI-ECN調優手段進行快速和精確部署。AI-ECN調優算法模型具有效率高、計算量小的特點,同時支持控制器集中式調優和網絡設備分布式本地調優兩種模式。例如,在集中式調優模式下,不需要專用的AI芯片,使用搭載Intel XEON-SP服務器的管控析集群,就可在較大規模網絡管理下,开啓ECN水线調優;在本地模式下,搭載Intel XEON-D 和 ATOM的新華三網絡交換機,僅以較小的CPU开銷就可以完成調優。
RoCE方案是業界常用的AI高性能組網方案,除此之外,有些用戶還會考慮採用集中式框式設備實現小規模的AI組網:
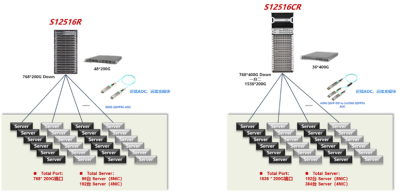
這種組網的優勢在於無需部署復雜的無損以太網(PFC/ECN)功能,僅通過一台設備便可以實現1536個200G端口接入能力。新華三S125R/CR系列採用正交CLOS無中板設計,業務板與交換板之間採用信元轉發,完美得解決了擁塞問題。實際應用場景中,在和時延等方面表現良好。但是這種組網由於單機框槽位問題,組網規模受限。
爲了優化這個問題,新華三繼而推出了DDC(Distributed Disaggregated Chassis,分布式分解結構)解決方案。
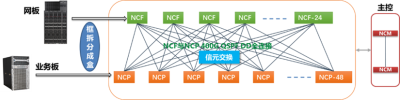
簡單介紹DDC其實就是將框式交換機拆分形成盒式組網,但是盒式交換機之間依舊採用信元交換,採用JR2C+雙芯片方案最大可支持3456個200G端口接入能力。DDC對比RoCE在網絡性能和網絡收斂方面提升明顯:ALL2ALL測試場景中,DDC完成時間可提高20-30%;無論UP/DOWN還是手工插拔測試方式,DDC的收斂時間縮短了幾百到上千倍。
隨着大模型訓練所需網絡帶寬的不斷提升,網絡主芯片性能也會迅速增加,當800G/1.6T時代來臨時,CPO/NPO交換機將會登上互聯網舞台,而新華三也早已有所布局:

S9825-32D32DO交換機,4U高度內可同時支持32個400G光模塊接口和32個400G光引擎接口,後續可以平滑升級至51.2T平台。
結語
以ChatGPT爲代表的AIGC已經成爲當下互聯網行業的風口,歷史經驗表明,善於抓住風口的企業最終都會站上時代之巔。在AIGC領域新華三已經與諸多頭部互聯網客戶達成深度合作,新華三希望成爲互聯網客戶緊密的合作夥伴,通過全棧的智算中心解決方案能力助力廣大用戶的AIGC相關研發和推進!
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:中國算力無人比
地址:https://www.breakthing.com/post/63593.html