




來源:內容由半導體行業觀察轉自軟硬件融合,謝謝。
編者按
隨着ChatGPT的火爆,AGI(Artificial General Intelligence,通用人工智能)逐漸看到了爆發的曙光。短短一個月的時間,所有的巨頭都快速反應,在AGI領域“重金投入,不計代價”。
AGI是基於大模型的通用智能;相對的,之前的各種基於中小模型的、用於特定應用場景的智能可以稱之爲專用智能。
那么,我們可以回歸到一個大家經常討論的話題:向左(專用)還是向右(通用)?在芯片領域,大家針對特定的場景开發了很多專用的芯片。是否可以類似AGI的發展,开發足夠通用的芯片,既能夠覆蓋幾乎所有場景,還能夠功能和性能極度強大?
1.AGI發展綜述
1.1 AGI的概念
AGI通用人工智能,也稱強人工智能(Strong AI),指的是具備與人類同等甚至超越人類的智能,能表現出正常人類所具有的所有智能行爲。
ChatGPT是大模型發展量變到質變的結果,ChatGPT具備了一定的AGI能力。隨着ChatGPT的成功,AGI已經成爲全球競爭的焦點。
與基於大模型發展的AGI對應的,傳統的基於中小模型的人工智能,也可以稱爲弱人工智能。它聚焦某個相對具體的業務方面,採用相對中小參數規模的模型,中小規模的數據集,然後實現相對確定、相對簡單的人工智能場景應用。
1.2 AGI特徵之一:湧現“湧現”,並不是一個新概念。凱文·凱利在他的《失控》中就提到了“湧現”,這裏的“湧現”,指的是衆多個體的集合會湧現出超越個體特徵的某些更高級的特徵。
在大模型領域,“湧現”指的是,當模型參數突破某個規模時,性能顯著提升,並且表現出讓人驚豔的、意想不到的能力,比如語言理解能力、生成能力、邏輯推理能力等等。
對外行(比如作者自己)來說,湧現能力,可以簡單的用“量變引起質變”來解釋:隨着模型參數的不斷增加,終於突破了某個臨界值,從而引起了質的變化,讓大模型產生了許多更加強大的、新的能力。
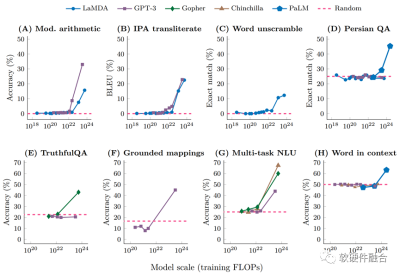
如果想詳細了解大模型“湧現”能力的詳細分析,可以參閱谷歌的論文《Emergent Abilities of Large Language Models》。
當然,目前,大模型發展還是非常新的領域,對“湧現”能力的看法,也有不同的聲音。例如斯坦福大學的研究者對大語言模型“湧現”能力的說法提出了質疑,認爲其是人爲選擇度量方式的結果。詳見論文《Are Emergent Abilities of Large Language Models a Mirage?》。
1.3 AGI特徵之二:多模態每一種信息的來源或者形式,都可以稱爲一種模態。例如,人有觸覺、聽覺、視覺等;信息的媒介有文字、圖像、語音、視頻等;各種類型的傳感器,如攝像頭、雷達、激光雷達等。多模態,顧名思義,即從多個模態表達或感知事物。而多模態機器學習,指的是從多種模態的數據中學習並且提升自身的算法。
傳統的中小規模AI模型,基本都是單模態的。比如專門研究語言識別、視頻分析、圖形識別以及文本分析等單個模態的算法模型。
基於Transformer的chatGPT出現之後,之後的AI大模型基本上都逐漸實現了對多模態的支持:
首先,可以通過文本、圖像、語音、視頻等多模態的數據學習;
並且,基於其中一個模態學習到的能力,可以應用在另一個模態的推理;
此外,不同模態數據學習到的能力還會融合,形成一些超出單個模態學習能力的新的能力。
多模態的劃分是我們人爲進行劃分的,多種模態的數據裏包含的信息,都可以被AGI統一理解,並轉換成模型的能力。在中小模型中,我們人爲割裂了很多信息,從而限制的AI算法的智能能力(此外,模型的參數規模和模型架構,也對智能能力有很大影響)。
1.4 AGI特徵之三:通用性從2012年深度學習走入我們的視野,用於各類特定應用場景的AI模型就如雨後春筍般的出現。比如車牌識別、人臉識別、語音識別等等,也包括一些綜合性的場景,比如自動駕駛、元宇宙場景等。每個場景都有不同的模型,並且同一個場景,還有很多公司开發的各種算法和架構各異的模型。可以說,這一時期的AI模型,是極度碎片化的。
而從GPT开始,讓大家看到了通用AI的曙光。最理想的AI模型:可以輸入任何形式、任何場景的訓練數據,可以學習到幾乎“所有”的能力,可以做任何需要做的決策。當然,最關鍵的,基於大模型的AGI的智能能力遠高於傳統的用於特定場合的AI中小模型。
完全通用的AI出現以後,一方面我們可以推而廣之,實現AGI+各種場景;另一方面,由於算法逐漸確定,也給了AI加速持續優化的空間,從而可以持續不斷的優化AI算力。算力持續提升,反過來又會推動模型向更大規模參數演進升級。
2.專用和通用的關系
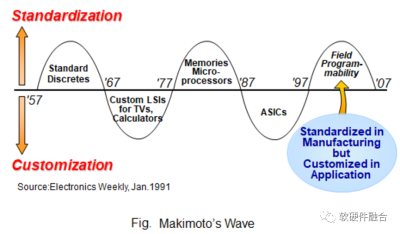
牧本波動(Makimoto's Wave)是一個與摩爾定律類似的電子行業發展規律,它認爲集成電路有規律的在“通用”和“專用”之間變化,循環周期大約爲10年。也因此,芯片行業的很多人認爲,“通用”和“專用”是對等的,是一個天平的兩邊。設計研發的產品,偏向通用或偏向專用,是基於客戶場景需求,對產品實現的權衡。
但從AGI的發展來看,基於大模型的AGI和傳統的基於中小模型的專用人工智能相比,並不是對等的兩端左右權衡的問題,而是從低級智能升級到高級智能的問題。我們再用這個觀點重新來審視一下計算芯片的發展歷史:
專用集成電路ASIC是貫穿集成電路發展的一直存在的一種芯片架構形態;
在CPU出現之前,幾乎所有的芯片都是ASIC;但在CPU出現之後,CPU迅速的取得了芯片的主導地位;CPU的ISA包含的是加減乘除等最基本的指令,也因此CPU是完全通用的處理器。
GPU最开始的定位是專用的圖形處理器;自從GPU改造成了定位並行計算平台的GP-GPU之後,輔以幫助用戶开發的CUDA的加持,從而成就了GPU在異構時代的王者地位。
隨着系統復雜度的增加,不同客戶系統的差異性和客戶系統的快速迭代,ASIC架構的芯片,越來越不適合。行業逐漸興起了DSA的浪潮,DSA可以理解成ASIC向通用可編程能力的一個回調,DSA是具有一定編程能力的ASIC。ASIC面向具體場景和固化的業務邏輯,而DSA則面向一個領域的多種場景,其業務邏輯部分可編程。即便如此,在AI這種對性能極度敏感的場景,相比GPU,AI-DSA都不夠成功,本質原因就在於AI場景快速變化,但AI-DSA芯片迭代周期過長。
從長期發展的角度看,專用芯片的發展,是在給通用芯片探路。通用芯片,會從各類專用計算中析取出更加本質的足夠通用的計算指令或事務,然後把之融合到通用芯片的設計中去。比如:
CPU完全通用,但性能較弱,所以就通過向量和張量等協處理器的方式,實現硬件加速和性能提升。
CPU的加速能力有限,於是出現了GPU。GPU是通用並行加速平台。GPU仍然不是性能最高的加速方式,也因此,出現了Tensor Core加速的方式。
Tensor Core的方式,仍然沒有完全釋放計算的性能。於是,完全獨立的DSA處理器出現。
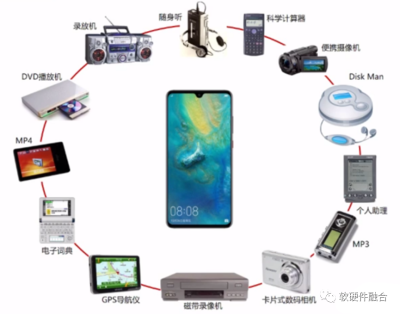
智能手機是通用和專用的一個經典案例:在智能手機出現之前,各種各樣的手持設備,琳琅滿目;智能手機出現之後,這些功能專用的設備,就逐漸消失在歷史長河中。
通用和專用,並不是,供設計者權衡的,對等的兩個方面;從專用到通用,是低級到高級的過程。短期來看,通用和專用是交替前行;但從更長期的發展來看,專用是暫時的,通用是永恆的。
3.通用處理器是否可行?
CPU是通用的處理器,但隨着摩爾定律失效,CPU已經難堪大用。於是,又开始了一輪專用芯片設計的大潮:2017年,圖靈獎獲得者John Hennessy和David Patterson就提出“體系結構的黃金年代”,認爲未來一定時期,是專有處理器DSA發展的重大機會。
但這5-6年的實踐證明,以DSA爲代表的專用芯片黃金年代的成色不足。反而在AI大模型的加持之下,成就了通用GPU的黃金年代。
當然,GPU也並不完美:GPU的性能即將,如CPU一樣,到達上限。目前,支持GPT大模型的GPU集群需要上萬顆GPU處理器,一方面整個集群的效率低下,另一方面集群的建設和運行成本都非常的高昂。
是否可以設計更加優化的處理器,既具有通用處理器的特徵,盡可能的“放之四海而皆准”,又可以更高效率更高性能?這裏我們給一些觀點:
我們可以把計算機上運行的系統拆分爲若幹個工作任務,如一些軟件進程或相近軟件進程的組合可以看做是一個工作任務;
廣泛存在的二八定律:系統中的工作任務,並不是完全隨機的,很多工作業務是相對確定的,比如虛擬化、網絡、存儲、安全、數據庫、文件系統,甚至人工智能推理,等等;並且,即使應用層的比較隨機的計算任務,仍然會包含大量確定性的計算成分,例如一些應用包含安全、視頻圖形處理、人工智能等相對確定的計算部分。
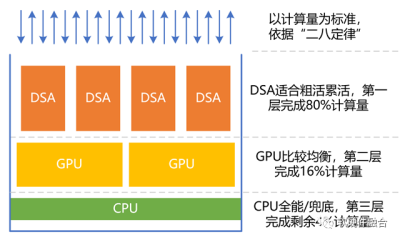
我們把處理器(引擎)按照性能效率和靈活性能力,簡單的分爲三個類型:CPU、GPU和DSA。
類似“塔防遊戲”,依據二八定律,把80%的計算任務交給DSA完成,把16%的工作任務交給GPU來完成,CPU負責剩余4%的其他工作。CPU很重要的工作是兜底。
依據性能/靈活性的特徵,匹配到最合適的處理器計算引擎,可以在實現足夠通用的情況下,實現最極致的性能。
4.通用處理器的歷史和發展
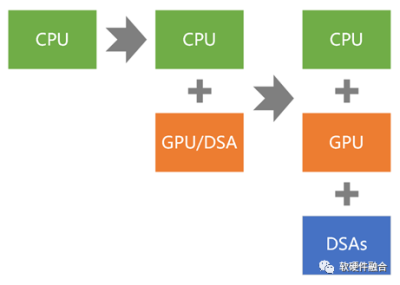
如果我們以通用計算爲准,計算架構的演進,可以簡單的劃分爲三個階段,即從同構走向超異構,再持續不斷的走向超異構:
第一代通用計算:CPU同構。
第二代通用計算:CPU+GPU異構。
第三代(新一代)通用計算:CPU+GPU+DSAs的超異構。
4.1 第一代通用計算:CPU同構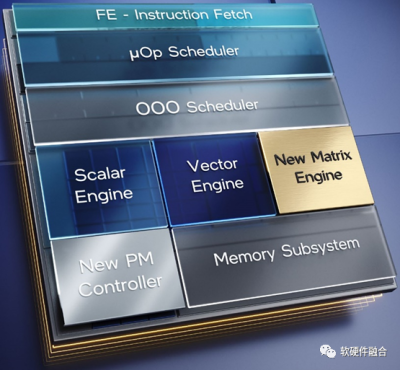
Intel發明了CPU,這是第一代的通用計算。第一代通用計算,成就了Intel在2000前後持續近30年的霸主地位。
CPU標量計算的性能非常弱,也因此,CPU逐漸引入向量指令集處理的AVX協處理器以及矩陣指令集的AMX協處理器等復雜指令集,不斷的優化CPU的性能和計算效率,不斷的拓展CPU的生存空間。
4.2 第二代通用計算:CPU+GPU異構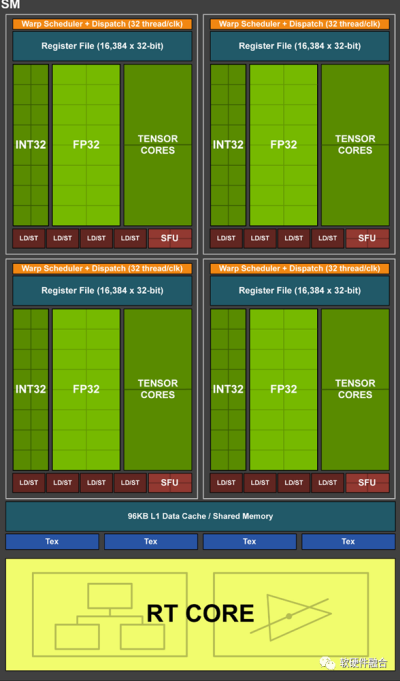
CPU協處理器的做法,本身受CPU原有架構的約束,其性能存在上限。在一些相對較小規模的加速計算場景,勉強可用。但在AI等大規模加速計算場景,因爲其性能上限較低並且性能效率不高,不是很合適。因此,需要完全獨立的、更加重量的加速處理器。
GPU是通用並行計算平台,是最典型的加速處理器。GPU計算需要有Host CPU來控制和協同,因此具體的實現形態是CPU+GPU的異構計算架構。
NVIDIA發明了GP-GPU,以及提供了CUDA框架,促進了第二代通用計算的廣泛應用。隨着AI深度學習和大模型的發展,GPU成爲最炙手可熱的硬件平台,也成就了NVIDIA萬億市值(超過Intel、AMD和高通等芯片巨頭的市值總和)。
當然,GPU內部的數以千計的CUDA core,本質上是更高效的CPU小核,因此,其性能效率仍然存在上升的空間。於是,NVIDIA开發了Tensor加速核心來進一步優化張量計算的性能和效率。
4.3 第三代(面向未來的)通用計算:CPU+GPU+DSAs超異構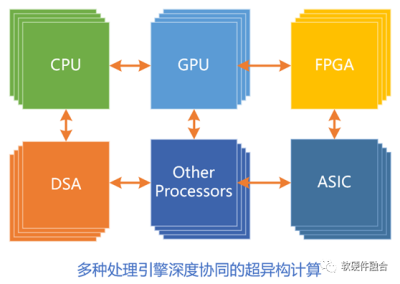
技術發展,永無止境。第三代通用計算,即多種異構融合的超異構計算,面向未來更大算力需求場景的挑战:
首先,有三個層次的獨立處理引擎。即CPU、GPU和DSA。(相應的,第一代CPU只有一個,第二代異構計算有兩個。)
多種加速處理引擎,都是和CPU組成CPU+XPU的異構計算架構。
超異構不是簡單的多種異構計算的集成,而是多種異構計算系統的,從軟件到硬件層次的,深度融合。
超異構計算,要想成功,必須要實現足夠好的通用性。如果不考慮通用性,超異構架構裏的相比以往更多的計算引擎,會使得架構碎片化問題更加嚴重。軟件人員無所適從,超異構就不會成功。
*免責聲明:本文由作者原創。文章內容系作者個人觀點,半導體行業觀察轉載僅爲了傳達一種不同的觀點,不代表半導體行業觀察對該觀點贊同或支持,如果有任何異議,歡迎聯系半導體行業觀察。
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:是否存在足夠通用的處理器?
地址:https://www.breakthing.com/post/65268.html