




來源:內容來自半導體行業觀察綜合,謝謝。
根據推特帳號Revegnus@Tech_ReveWafer 曝光台積電晶圓及先進制程芯片代工價的表單,其中一張圖來源於The Information Network。
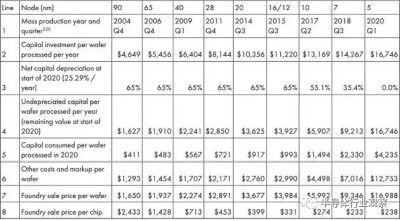
資料顯示,台積電晶圓代工價格從90納米到3納米乃至於未來的2納米一直在穩定增加,例如今年3納米報價19865 美元(約141637人民幣),5納米爲13400 美元(約95542人民幣),7納米爲10235 美元(約72975人民幣)。
據報導,本月稍早時,業界消息稱台積電近期啓動2納米試產前期准備工作,將搭配導入最先進AI 系統來節能減碳並加速試產效率,預計蘋果、英偉達等大廠都會是台積電2納米量產後首批客戶,並擴大與三星、英特爾等競爭對手的差距。
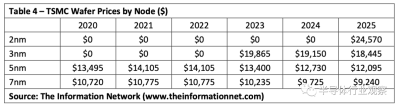
台積電表示不評論相關傳聞,強調2納米技術研發進展順利,預計2025 年量產;從這裏給出的代工報價來看,台積電2納米報價預計在24570 美元(約175184人民幣)左右。
據了解,台積電未來最先進的2納米生產基地會先落腳竹科寶山晶圓20 廠,該廠區爲4期規劃,後續並將擴至中科,共計有6期的工程。
業界傳出,台積電2納米研發初期會先在竹科建立小量試產生產线,目標今年試產近千片,試產順利後,將導入後續建造完成的竹科寶山晶圓20 廠,由該廠團隊接力衝刺2024 年風險試產與2025 年量產目標。
據悉,台積電2納米將首度採用全新環繞式閘極(GAA)晶體管架構,台積電之前於技術論壇中指出,相關新技術整體系統效能較3納米大幅提升,客戶群先期投入合作开發意愿遠高於3納米家族初期,並可量身定做更多元方案。
台積電3nm細節全曝光,成本驚人
本文章將涵蓋工藝節點過渡、台積電最先進技術的過高成本,以及它將如何顯着加速行業向先進封裝和小芯片的轉變。此外,我們將詳細介紹 N5、N4、N3B 和 N3E 的各種間距、特性和 SRAM 單元尺寸。
台積電 5nm 晶圓廠成本
2018年初,台積電宣布投資新晶圓廠。這個新站點將擁有其最先進的技術 N5。隨着蘋果和華爲承諾在 2020 年生產 N5 晶圓,這是進行大規模擴建的絕佳機會。台積電表示,他們對 Fab 18 第一至第三階段的投資將超過新台幣 5000 億元,約合 170 億美元。該站點計劃每月生產超過 80,000 個晶圓。在 2020 年第一季度的財報電話會議上,台積電確認 N5 正在大批量生產,可能處於第一階段。
盡管台南科學園區的 Fab 18 仍將是 N5 生產的主要地點,但台積電還宣布將其業務擴展到美國亞利桑那州鳳凰城。2018年年中,台積電宣布該廠總投資120億美元,月產2萬片晶圓。這座工廠建成後,將成爲台積電在台灣以外制造的最先進的技術節點。到 2022 年,台積電的 N5 產能將遠超每月 12 萬片晶圓,這僅佔台積電 N5 產能的 15% 左右。
乍一看,台灣台南 N5 的第 1 至 3 期設施規模擴大了 4 倍,但成本僅高出 40%,這證明了在沒有大量補貼的情況下在美國建造晶圓廠在經濟上沒有意義的論點. 實際上,這些數字沒有可比性。台積電爲美國晶圓廠提供的數字包括 2021 年至 2029 年的所有總支出。這遠遠超過了最初的資本支出成本。台積電給台灣晶圓廠的數字只是最初的擴建,沒有其他成本。
應該注意的是,在初始擴建期間,晶圓廠總成本的約 80% 來自設備。此外,超過 60% 的運營成本來自材料、化學品、工具維護和能源投入。無論晶圓廠位於何處,這些成本大多相同(能源確實不同)。
台積電 3nm 晶圓廠成本
位於台南科學園區的 Fab 18 也是生產 N3 系列節點的主要地點。第 4 至第 6 期專供3nm家族使用。位於新竹科學園區的 Fab 12 第 8 期和第 9 期也將生產該節點。近日,台積電又宣布投資Fab 21 Phase 2。這擴大了其在亞利桑那州的現有工廠,以生產 N3 晶圓。亞利桑那州的新計劃將使台積電的總支出增加到 400 億美元,並將產能增加到每月 50,000 片晶圓。其中 20,000 個仍將是 N5,30,000 個將是 N3。完成後,N3 產能將佔台積電全球 N3 產能的 25%。
這將是台積電首次分享同一地點不同代工廠之間的完整成本比較。由於成本超支的傳言,台積電的 N5 晶圓廠成本可能已從最初的120億美元增加到130億美元。最有可能的是,這些成本處於該範圍的中間。
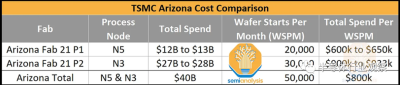
每個晶圓开始的每月總支出從 38% 增加到 55%。這與我們聽到的 N3 定價比 N5 高出約 40% 的其他謠言非常吻合。與DigiTimes 的謠言相反,晶圓價格不是 20,000 美元。
N3 的故事很復雜。最初,考慮到不溫不火的性能、功率和密度改進,N3 的良率和價格都具有挑战性,超出了大多數客戶愿意支付的價格。它有大約 25 個 EUV 層,幾乎是 N5 的兩倍。N3 出現了許多問題,最終導致台積電錯過了典型的 2 年主要工藝節點發布周期。對公衆來說最值得注意的變化是,隨着摩爾定律的放緩,蘋果公司被迫徹底改變其產品的芯片計劃。
除了將 N3 從 2022 款 iPhone 推出到 2023 款 Pro iPhone 之外,許多其他客戶也放棄了他們最初的 N3 計劃。關於 Zen 5、英特爾 GPU 和一些 Broadcom 定制 ASIC 存在許多謠言。據傳,這些公司選擇堅持使用 N5 級工藝節點或轉向寬松的 N3E 工藝。最初的 N3 被大多數人稱爲 N3B,但 N3E 與 N5 類工藝節點共享相同的 SRAM 位單元大小,並減少了 EUV 曝光的次數。
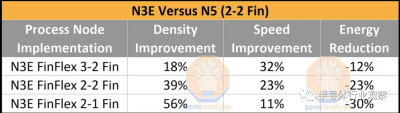
密度的提高充其量只是略高於晶圓成本的增加。通過 FinFlex 2-1 實施,密度提高了 56%,成本增加了 40%。這導致每個晶體管的成本降低了 11%,這是 50 多年來主要工藝技術的最弱擴展。
其他實現要么在每個晶體管的成本上持平,要么甚至爲負,但每個晶體管的速度都有更大的改進。請注意,上述一代又一代的改進是使用 Arm Cortex A72 測量的。密度改進將根據正在實施的 IP 而有所不同。
大多數芯片設計不會實現 56% 的密度提升,而是低得多,約爲 30%。這意味着每個晶體管的成本增加,但公司正在調整設計以確保不會發生這種情況。這將在工藝技術部分進行解釋。
3nm 實施成本
當採用最先進的工藝技術實現芯片的成本變得更高時,轉向 3nm 或留在 N5 系列的決定變得更加棘手。
我們在上面詳細解釋了這個問題,但在最新的工藝技術中實施產品的固定成本變得如此之大,以至於對公司來說意味着巨大的風險。延遲變得越來越棘手,重新設計的成本越來越高,最糟糕的是,實現每晶體管成本改進所需的體積越來越大。
出於這個原因,許多公司將在未來很長一段時間內堅持使用 N5 級工藝節點。許多其他公司只會將計算小芯片轉移到 N3 類,同時保留所有其他 IP,例如 SRAM 和模擬的舊工藝技術。台積電 N3 將導致小芯片和先進封裝的爆炸式增長。
在我們進入 N3 工藝細節之前,我們想詳細介紹一下 N5 系列,因爲它真實地證明了 TSMC 的驚人之處。迭代的不是一個制程節點,而是最適合每種不同類型客戶需求的許多並發風格和修改。
5nm工藝族技術詳解
台積電 N5 系列的一部分包括:N5、N5P、N5A、N4、N4P 和 N4X。除了那些已宣布的變體之外,我們預計台積電將在未來幾年內發布 RF 優化和泄漏優化版本。通過所有這些變體,台積電希望延長工藝技術的壽命,並將更多客戶推向 N4 節點,部分原因是它們的生產成本較低,客戶的固定成本也較低。N4 是量產的最新節點,已在聯發科天璣 9200、高通驍龍 8 Gen 2 和 Apple A16 中實現。
N5 是一個工程奇跡,在其發布時無疑是最先進的節點。台積電宣布其邏輯密度將提高 1.84 倍,在相同功耗下性能提升 15%,在相同性能下功耗降低 30%。雖然無數芯片在性能和功率方面確實得到了改進,但似乎從未實現過規定的密度增益。
正如 Angstronomics 最近報道的那樣,這是因爲台積電撒謊了。邏輯密度的增益接近 52%。雖然台積電可能在密度上撒了謊,但台積電N5仍然是量產中最好的節點。
N5 的鰭間距爲 28nm,僅略低於三星 5LPE,接觸柵極間距爲 51nm,僅略低於 Intel 4。通過連續擴散的新方法,他們設法減小了單元寬度。
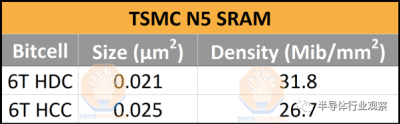
N5 在 M0 上的最小金屬間距爲 28nm,比 N7 減少了 30%。這將有助於減少可能由信號和電源路由引起的瓶頸。台積電的 M2 金屬間距爲 35 納米,擁有一個 6 軌標准單元,盡可能密集,使用帶有 2 個 PMOS 鰭片和 2 個 NMOS 鰭片的 FinFET。N5 還擁有最小的 6T 高密度 SRAM 位單元,尺寸爲 0.021 m,低於 Intel 4 的 0.0240 m 和三星 4LPE 的 0.0262 m 位單元。TSMC 的 6T 高電流 SRAM 位單元也非常小,只有 0.025 m,是迄今爲止密度第三高的。
N5P是N5的流程優化。通過增強工藝的 FEOL 和 MOL,台積電的性能提高了 7%,功耗降低了 15%。雖然這看起來可能不多,但好處是這種流程優化與 N5 是 IP 兼容的。任何 N5 設計都可以輕松移植到 N5P 並看到這些收益。隨着半導體設計固定成本的飆升,其影響不可低估。

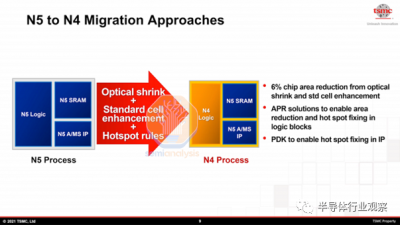
N4是N5的另一項工藝優化,但它有一個小的設計收縮。這也稱爲“nodelet”。通過標准單元庫的優化、較小的光學收縮和設計規則的改變,N4 實現了更好的面積效率。N4 還減少了掩模數量和工藝復雜性。這使得台積電能夠以低於每片晶圓 N5 的成本生產 N4。
Nikkei Asia曾有傳言稱 Apple A16 的制造成本是其制造商的 2 倍,但這完全是錯誤的。與 N5P 非常相似,通過改進 FEOL 和 MOL 改進了功率和性能特徵。
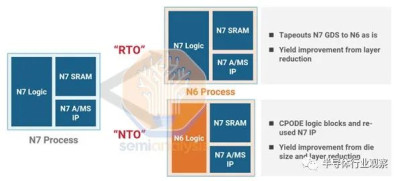
與 TSMC 的其他 nodelet N6 一樣,N4 提供了兩種從現有 N5 設計遷移的方法。兩者都有其權衡取舍。
首先是 RTO 或重新流片,涉及使用與 N5 相同的設計規則。這更便宜,需要更少的工程,並且提供更少的 N4 的好處。這就是聯發科能夠在風險生產後這么快就在“N4”上發布天璣 9000 的原因。
接下來是 NTO 或新流片,這需要使用 N4 提供的最新庫和更多優化來重新實現邏輯塊。這需要更多的工程,但提供了更多的好處,包括較小的面積縮小。
2021 年底,台積電宣布 N4P,這是 N4 的工藝優化。通過進一步改進 FEOL 和 MOL,TSMC 的性能比 N4 又提高了 6%,功耗比 N5 降低了 22%。
現在進入專業技術;N5A基於台積電的N5工藝。這個節點在技術上並不是特別獨特。但是,它已通過汽車公司在使用工藝節點時尋求的所有標准的認證。它經過優化,可以在車輛中長時間(10 年或 20 年)存活而不會降解。
N4X 是台積電首款 HPC 優化制程技術。N4X 針對超過 1.2V 的高壓設備進行了優化,性能比 N4P 提高了 4%。FEOL 對鰭片進行了改進,以允許更高的電流、電壓和更高的頻率。金屬堆棧經過精心設計,可通過降低電阻和寄生電容來改善這些高性能設備的功率傳輸和信號完整性。金屬堆棧還具有改進的金屬金屬電容器,可通過減少電壓降並將性能進一步提高 2-3% 來提供更強大的電力傳輸。
爲了達到如此高的頻率,可能放寬了一些設計規則,但這可能不是問題,因爲高性能設備更受金屬堆疊的限制,無論如何都無法利用密度。在泄漏方面也有一些讓步,必須做出這些讓步才能實現更高的性能。大多數半導體公司不會使用此節點,因爲他們更喜歡較低的功耗/泄漏,但 N4X 是一些最高性能應用的有力競爭者。
現在,我們將討論 N5 系列節點的關鍵間距,並專門詳細介紹 TSMC 的 N4 節點的間距。N5 的高密度 (HD) 庫的鰭間距爲 28nm,具有 8 條擴散线,單元高度爲 210nm。接觸柵極間距 (CGP) 爲 51nm。N5 的高性能 (HP) 庫具有相同的間距,但爲 280nm 的單元高度添加了 2 條擴散线。高性能庫還將 CGP 略微放寬至 57nm,從而實現更高的性能。正如台積電所說,N4 通過光學縮小提供了 6% 的面積減少。爲實現這一目標,HD 和 HP 庫的單元高度分別縮小到 206 納米和 274 納米。此外,CGP已經縮小到49nm和55nm。
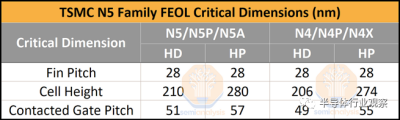
N5 爲其最低金屬層提供 28nm 的間距,這是生產中最小的。這也是節點的最小金屬間距。它還提供 35nm 的金屬 2 間距,這是生產中最小的間距。
正如我們所提到的,N5 在每個 6T HD 和 HP 位單元類別中都具有生產中最密集的位單元。借助 30% 的輔助電路开銷,HD SRAM 密度達到 31.8 Mib/mm,HP SRAM 密度達到 26.7 Mib/mm2。盡管 N4 並未帶來 SRAM 位單元尺寸的進一步縮小,但台積電仍處於領先地位。
現在,進入主要吸引力,邏輯密度。雖然這可能是最引人注目的數字,但它並不能單獨描述一個節點。必須考慮所有其他特性,從其 SRAM 位單元到功率和性能。這些指標是使用 Bohr 公式計算的,該公式將 60% 的權重分配給小而稀疏的 NAND2 單元,將 40% 的權重分配給大但密集的 Scan Flip-Flop 單元。台積電在這一指標上處於領先地位,但在其他因素上略遜一籌。
雖然其HD庫的密度是生產中最高的,但其HP庫的密度落後於Intel 4的HP。需要明確的是,根據英特爾的說法,Intel 4 已經“准備好制造”,但真正的大批量生產還需要幾個季度。然而,密度是使用 TSMC 的 N5 系列節點的最誘人的原因之一。
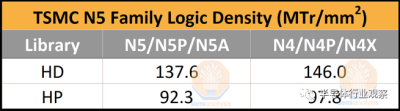
台積電的 N5 系列是一組出色的節點,單靠這些指標並不能說明問題。它在功率、性能、面積、易用性、IP 生態系統和成本方面的組合是無與倫比的。
N3技術節點
N3 系列節點包括 N3B、N3E、N3P、N3X 和 N3S。其中許多是針對特定目的優化的小節點,但有所不同。N3B,即初代的 N3,與 N3E 無關。與其將其視爲 nodelet,不如將其視爲一個完全不同的節點。
在 IEDM 2022 上,台積電透露了 N3B 的一些方面。N3B 具有 45nm 的 CGP,與 N5 相比縮小了 0.88 倍。台積電還實施了自對准接觸,從而可以更大程度地擴展 CGP。台積電還展示了 0.0199 m2 的 6 晶體管高密度 SRAM 位單元。這僅縮小了 5%,這對於 SRAM 未來的擴展來說是個壞兆頭。
近年來,芯片設計人員嚴重依賴 SRAM 來提高性能。SRAM 縮放的消亡帶走了提高性能的一個重要槓杆,並將增加架構在提高功率和性能特徵方面的重要性。

與N5相比,台積電最初表示,N3在同等功率下性能提升約12%,同等性能下功耗降低27%。這將具有 1.2× SRAM 密度和 1.1× 模擬密度。
IEDM 上公开的高密度位單元僅將 SRAM 密度提高了約 5%,與最初聲稱的 20% 相去甚遠。
誰能解釋一下爲什么台積電又不誠實了…………
在 IEDM 期間,台積電透露 N3B 的 CGP 爲 45nm,是迄今爲止透露的最密集的。這領先於Intel 4的50nm CGP、三星4LPP的54nm CGP和TSMC N5的51nm CGP。
雖然邏輯密度的增加無疑是有希望的,但低 SRAM 密度增益意味着 SRAM-heavy 設計可能會經歷顯着的成本增加。N3B 的良率和金屬堆疊性能也很差。基於這些原因,N3B 不會成爲台積電的主要節點。

由於 N3B 未能達到 TSMC 的性能、功率和產量目標,因此开發了 N3E。其目的是修復N3B的缺點。第一個重大變化是金屬間距略有放松。台積電沒有在 M0、M1 和 M2 金屬層上使用多重圖案化 EUV,而是退縮並切換到單一圖案化。
此外,上一代需要 EUV 雙圖案化的三個關鍵層被單 EUV 圖案化所取代,這降低了工藝復雜性、固有成本和周期時間。
這是在保持功率和性能數據相似的同時實現的。邏輯密度也略有下降。此外,使用標准單片芯片(50% 邏輯 + 30% SRAM + 20% 模擬),密度僅增加 1.3 倍。
在 IEDM 期間,台積電透露 N3E 的位單元尺寸爲 0.021 m2,與 N5 完全相同。這對SRAM來說是毀滅性的打擊。由於良率,台積電放棄了 SRAM 單元尺寸而不是 N3B。
台積電表示,256Mb HC/HD SRAM 宏和類似產品的邏輯測試芯片始終表現出比我們上一代更健康的缺陷密度。
N3E 比 N3B 做得好得多,明年年中將量產。對於那些保持跟蹤的人來說,N5 推出已經 3 年多了。這是 AMD、Nvidia、Broadcom、Qualcomm、MediaTek、Marvell和許多其他公司最終將使用 N3E 作爲其領先優勢的節點。
與台積電爲其 N7 和 N5 系列節點推出的先前 nodelet 不同,N3E 與 N3B IP 不兼容。這意味着必須重新實現 IP 塊。因此,許多公司,例如 GUC,選擇只在更持久的 N3E 節點上實現他們的 IP。
N3P 將是 N3E 的後續節點。它與 N5P 非常相似,通過優化提供較小的性能和功率增益,同時保持 IP 兼容性。N3X 與 N4X 類似,並針對非常高的性能進行了優化。到目前爲止,功率、性能目標和時間表尚未公布。
N3S 是最終公开的變體,據說是密度優化的節點。目前知道的不多,但有一些謠言。Angstronomics 認爲這可能是一個單鰭庫,可以讓台積電進一步縮小單元高度。由於金屬堆疊的限制因素,這可能會受到限制,但設計會盡可能使用它。N3S 甚至可能實施背面供電網絡來緩解許多金屬堆疊問題,盡管這尚未得到證實。
作爲台積電的最後一個 FinFET 節點,N3E 及其後續節點有機會獲得與台積電最成功的節點之一 N28 類似的地位。鑑於其動蕩的歷史,這將是一項艱巨的任務,但台積電已經多次證明了自己的能力,尤其是在其生態系統方面。
*免責聲明:本文由作者原創。文章內容系作者個人觀點,半導體行業觀察轉載僅爲了傳達一種不同的觀點,不代表半導體行業觀察對該觀點贊同或支持,如果有任何異議,歡迎聯系半導體行業觀察。
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:台積電3nm晶圓價格曝光
地址:https://www.breakthing.com/post/66782.html