




隨着 Nvidia 的每一代 GPU 加速器引擎的推出,機器學習推動了越來越多的架構選擇和變化,而傳統 HPC 模擬和建模的推動力也越來越少。至少直接上是這樣。但間接地,隨着 HPC 越來越多地採用 AI 技術,讓神經網絡從現實世界或模擬數據中學習,而不是運行大量計算來預測某物的行爲,HPC 和 AI 之間的差異可能在未來十年左右沒有實際意義。
簡而言之,英偉達正在豪賭——將其 GPU 計算引擎集中在神經網絡轉換器模型上,並將其 DGX 系統擴展爲能夠在機器學習訓練運行中支持數萬億個參數。
我們認爲,這個是一件好事,因爲從長遠來看,如果 Nvidia 是正確的,那么在世界各地的 HPC 中心執行的模擬的更多部分將是推斷的,而不是數字計算的。雖然密集线性代數計算仍然很重要——尤其是模擬爲無法直接查看的物理現象提供數據集,因此沒有真實世界的數據——恆星內部或內燃機內部是兩個很好的例子—— GPU 上單精度 FP32 和雙精度 FP64 數學以及其他類型的數學之間的比率將繼續降低到更低的精度。
這肯定發生在新的第四代 Tensor Core 中的新 8 位 FP8 浮點格式上,它是 Nvidia 新的“Hopper”GH100 GPU 芯片的核心。CPU 和 GPU 中向量和矩陣數學單元中的較低精度數據格式,包括 4 位和 8 位整數格式(術語爲 INT4 和 INT8),這對 AI 訓練沒有用處,而僅對 AI 推理有用。但是對於 FP8 格式,對於許多模型來說,大量 FP8 和一些 FP16 以及少量 FP32 和 FP64 的混合現在足以進行訓練,而 FP8 也可以用於推理,而不必做繁瑣的數據轉換爲 INT4 或 INT8 格式,以便針對神經網絡運行新數據,以便模型識別或轉換爲另一種類型的數據——語音到文本、文本到速度、視頻到語音,
不難想象,有一天Nvidia 可能能夠創建一個 GPU 計算引擎,它只具有浮點矩陣數學並支持所有級別的混合精度,可能一直到 FP4,當然也可能一直到 FP64 . 但與其他計算引擎制造商一樣,Nvidia 必須保持爲其舊設備編寫的軟件的向後兼容性,這就是爲什么我們看到混合使用 32 位和 64 位矢量引擎(它們具有整數支持以及浮點支持)和張量核心矩陣數學引擎。我們之前已經警告過,有很多計算不能在矩陣單元中有效地完成,向量仍然是必要的。(您將不得不原諒我們希望有人創建沒有暗硅的最高效數學引擎的熱情。)
好消息是,新的“Hopper”GPU 中的流式多處理器或 SM 能夠對大量矢量和矩陣數據進行數學運算。
SM 大致類似於 CPU 中的內核,實際上,當您查看 Top500 列表中混合超級計算機的內核數時,該內核數是 CPU 上的內核數和 GPU 上的 SMS 的組合在那個系統中。SM 具有比 CPU 更多的算術單元,並且具有明確設計用於隱藏由相當適中的內核組成的數萬個线程的延遲的調度程序,這些內核共同提供比運行的 CPU 一個數量級或更多的性能以大約兩倍的速度。對於某些類型的計算來說,更慢更寬比快速和瘦身更好——至少當你受到芯片尺寸、電力消耗和散熱的限制,並且你需要擴大到千萬億級和現在的百億億級處理時。
這是新的 Hopper SM 的外觀:

SM 被組織成象限,每個象限有 16 個 INT32 單元,提供混合精度的 INT32、INT8 和 INT4 處理;32 個 FP32 單元(我們希望 Nvidia 不稱它們爲 CUDA 核心,而是 CUDA 單元);和 16 個 FP64 單元。有一個新的 Tensor Core 設計,Nvidia 故意混淆了這個核心的架構細節。每個象限都有自己的調度器和調度單元,每個時鐘可以處理 32 個线程,雖然該調度器可以同時處理多種單元類型,但它不能同時調度所有這些單元。(與“Ampere”GA100 GPU 的比率是調度程序可以同時向五種單元類型中的三種發送工作。我們不知道 GH100 GPU 是什么。)每個 Hopper SM 象限有 16 個,384 個 32 位寄存器,用於維護被推入象限的线程的狀態,以及 8 個加載/存儲單元和 4 個特殊功能單元。每個象限都有一個 L0 緩存(聽起來應該是空的,雖然它不是空的,但我們不知道容量)。SM 由張量內存加速器(稍後會詳細介紹)、256 KB 的 L1 數據緩存和未知數量的 L1 指令緩存包裹。(爲什么不直接告訴我們?)
大腦很難理解 Tensor Core 是什么,但我們認爲它是一個硬編碼的矩陣數學引擎,矩陣中的所有輸入都來自寄存器,流經單元,它完成了所有同時對矩陣元素進行乘法運算,並一舉累積。這與在向量單元中單獨排列一些向量、將它們相乘、將結果存儲在寄存器中、獲取更多向量、進行乘法並通過累積整個 shebang 來完成形成對比。
這是 Nvidia 如何在 44 矩陣上使用 FP32 單元來說明 Pascal 矩陣數學,與 Volta Tensor Core 單元和 Ampere Tensor Core 單元相比,這兩個單元都硬編碼了 44 矩陣數學,而後者有一個稀疏數據壓縮技巧,可以在不顯着犧牲 AI 准確性的情況下使吞吐量翻倍:
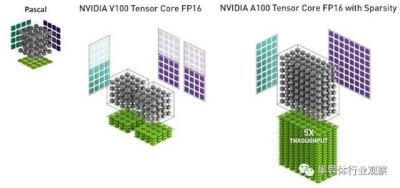
如您所見,Volta Tensor Core 在 FP16 模式下實現了一對硬編碼的 44 矩陣乘以 44 矩陣乘法,FP32 累加。啓用稀疏性後,Tensor Core 有效地變成了一個數學單元,相當於對 48 矩陣乘以 88 矩陣進行計算。
在下面的比較中,Nvidia 似乎展示了 GA100 和 GH100 GPU 的 SM 級別的張量核心,每個都有四個張量核心:
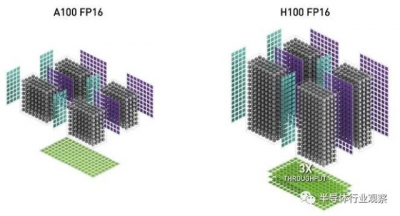
所以我們知道 GA100 每個 SM 有四個張量核心(英偉達在其 GA100 架構論文中透露),我們從這張圖推斷 GH100 每個 SM 也有四個張量核心(英偉達在其 GH100 架構文件中沒有披露) . 我們還可以看到,在稀疏打开的 FP16 模式下,Hopper GPU Tensor Core 有效地將 416 矩陣乘以 816 矩陣,這是支持稀疏的 Ampere Tensor Core 吞吐量的三倍在。
如果您對所有這些進行數學運算,並爲 P100 FP64 矢量引擎分配一個值 1,將 44 矩陣乘以另一個 44 矩陣,那么 V100 Tensor Core 的功能是 8 倍,A100 Tensor Core 是 20 倍更強大,40X 更強大的稀疏支持(如果適用),H100 Tensor Core 更強大 60X 和 120X 稀疏支持。
物理張量核心的數量因 GPU 架構而異(Volta 爲 672,Ampere 爲 512,Hopper SXM5 爲 576),裸片上激活的核心數量也不同(Volta 爲 672,Ampere 爲 432,Ampere 爲 528 Hopper SXM5。更復雜的是峰值性能比較,GPU 時鐘速度也因架構而異:Pascal SXM 爲 1.48 GHz,Volta SXM2 爲 1.53 GHz,Ampere SXM4 爲 1.41 GHz,Hopper SXM5 估計爲 1.83 GHz。每個 GPU 的原始張量核心性能上下波動。
就像向量單元越來越寬——128 位、256 位和 512 位——通過它們填充更多的 FP64、FP32、FP16 或 INT8 數字以在每個時鐘周期內完成更多工作,Nvidia 正在制造 Tensor Core矩陣更寬更高;大概這可用於對大型矩陣進行數學運算,但也可以將更多較小的矩陣填充到它們中,以使每個時鐘完成更多的工作。
重要的是,對於某些類型的矩陣數學,Hopper 只是摒棄了直接使用 FP32 或 FP64 單元來乘數,盡管精度降低了。Tensor Core 還以更高的 FP32 和 FP64 精度運行,支持的 FP32 和 FP64 吞吐量是 GPU 上實際 FP32 和 FP64 單元的兩倍。爲了保持這個比例正確,Nvidia 不得不不斷增加幾代的 FP32 內核和 FP64 內核的數量,在 Kepler 到 Hopper 的幾代人中平均增加了大約 1.9 倍。
您可以在下面的 Nvidia GPU 計算引擎的計算能力表中看到這一切:
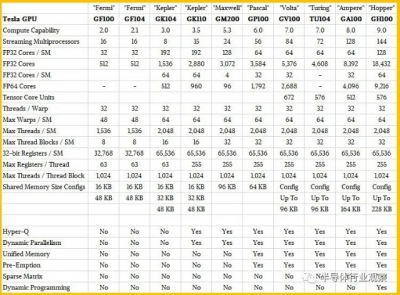
Hopper GH100 GPU 共有 144 個 SM,每個 SM 有 128 個 FP32 內核、64 個 FP64 內核和 64 個 INT32,以及 4 個 Tensor Core。
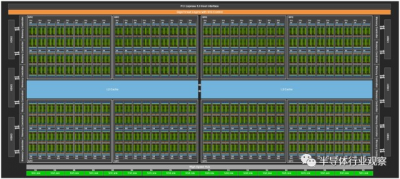
與 GA100 一樣,GH100 被組織成 8 個 GPU 處理集群,它們對應於 GH100 可以分割和虛擬化的多實例 GPU (MIG) 分區——現在完全隔離。GPC 有九個紋理處理結構 (TPC),每個由兩個 SM 組成。芯片頂部是 uber-scheduler、GigaThread Engine,以及一個 PCI-Express 5.0 主機接口。四個 GPC 排列在一個 L2 緩存組中,有兩個組,總容量爲 60 MB。
沿着 GA100 GPU 的側面,有十幾個 5,120 位內存控制器,它們饋送到六個 HBM3 內存庫。底部是一個高速集线器,所有 GPC 都連接到該集线器,並連接到 18 個 NVLink 4.0 端口,這些端口的總帶寬爲 900 GB/秒。
爲了獲得可觀的產量,英偉達只銷售八分之七的 GPC 和六分之五的 HBM3 內存條和相關的內存控制器工作的 H100。因此,GH100 的 12.5% 的計算能力和 16.7% 的內存容量和帶寬是黑暗的——與兩年前在 GA100 GPU 上的比例相同。
與其像 Nvidia Research 最近表明的那樣,英偉達轉向了小芯片,但實際上GH100 是一個單片芯片。
“我們並不反對小芯片,”GPU 工程高級副總裁 Jonah Alben 解釋說,他直接指的是聯合封裝的“Grace”Arm 服務器 CPU 和 Hopper GPU。“但我們真的很擅長制造大芯片,我認爲我們在制造大芯片方面實際上比使用 Hopper 時更好。如果你能做到的話,一個大Die仍然是最好的選擇,我認爲我們比其他任何人都知道如何做到這一點。所以我們以這種方式建造了 Hopper。”
GH100 芯片採用台積電 4 納米 4N 工藝的定制變體實現,在 SXM4 外形尺寸下消耗 700 瓦,這將內存帶寬驅動到 3 TB/秒,而不是 PCI- 中的 2 TB/秒。該卡的 Express 5.0 變體,重量僅爲 350 瓦,具有幾乎相同的計算性能。
從 Ampere GPU 中使用的 7 納米工藝縮小到 Hopper GPU 中使用的 4 納米工藝,Nvidia 能夠將更多的計算單元、緩存和 I/O 塞入裸片,同時將時鐘速度提高 30% . (英偉達尚未最終確定精確的時鐘速度。)
有一大堆新技術使 Hopper GPU 的性能比今年第三季度 Hopper 开始出貨時將取代的 Ampere GPU 的性能高出 6 倍。我們已經與Nvidia 的超大規模和 HPC 總經理Ian Buck 討論了動態編程和 Transformer Engine 加速。但簡而言之,Transformer Engine 可以選擇性地將新的 8 位 FP8 數據格式應用於機器學習訓練或推理工作負載,還可以調用其他降低的精度來加速 Transformer 神經網絡模型。重要的是,這種自適應精度是基於在 Selene 超級計算機上進行的大量模擬而動態調整的,以在盡可能提高性能的同時保持精度。
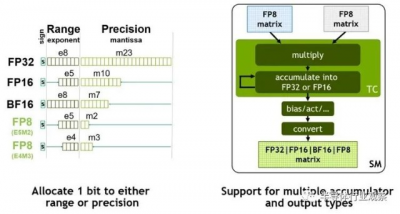
Hopper GPU 中實際上有兩種 FP8 格式:一種與 FP16 保持相同的數值範圍,但精度大大降低,另一種精度稍高但數值範圍較小。Tensor Core 中的 FP8 矩陣數學可以累加成 FP16 或 FP32 格式,並且根據神經網絡中的偏差,可以將輸出轉換爲 FP8、BF16、FP16 或 FP32 格式。
當你把它加起來時,轉向 4 納米工藝使 GH100 時鐘速度增加了 1.3 倍,SM 的數量增加了 1.2 倍。與 GA100 相比,新的 Tensor Core 以及新的 FP32 和 FP64 矢量單元都提供了 2 倍的每時鐘性能提升,對於變壓器模型,具有 FP8 精度的 Transformer 引擎將機器學習吞吐量再提高 2 倍。這使得 HPC 常用的矢量引擎的性能提高了 3 倍,而 AI 中常用的 Tensor Core 引擎的性能提高了 6 倍。
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:深入解讀英偉達“HOPPER”GPU架構
地址:https://www.breakthing.com/post/7110.html