





在這兩天舉行的 2023 世界人工智能大會上,阿裏雲旗下的通義系列大模型上新了一位新成員,通義萬相,並开啓了定向邀測。

通義萬相是一款 AI 繪圖應用,對於 AI 繪圖大家應該都不陌生,畢竟在此之前就有大名鼎鼎的 Midjourney 和 Stable Diffusion 了。
但這次重點在於,通義萬相還使用了新的繪圖模型 Composer。
可能有些讀者對繪圖模型的重要性不太了解,其實 AI 繪圖的發展,離不开 AI 繪圖模型的進步。
從早期的生成對抗網絡模型 Gan,到現在很多知名 AI 繪圖軟件都在用的擴散模型 Diffussion。
隨着訓練模型的迭代,AI 繪圖的能力也是越來越強。
而這次的繪圖模型 Composer,也不例外。
早在幾個月前,阿裏就發表了 Composer 相關的論文,而且外網上對於 Composer 的討論度還不低。
比如,有博主就發推文曬出了一些通過 Composer 模型生成的不同風格的圖片。
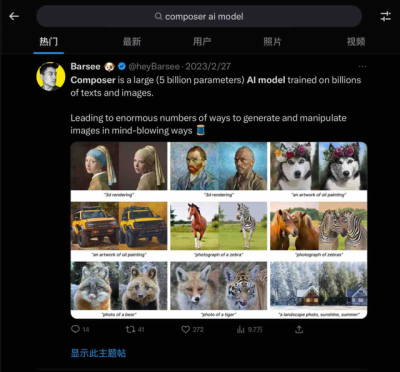
在這些例子中,有把棕毛馬變成斑馬的,把名畫變成真人的,把狐狸變成老虎的,這些生成圖不僅保留了原圖像的動作外形等細節,在風格轉換的融合上也是幾乎看不出什么違和感。
這個 Composer 之所以能有這么好的風格置換效果,和它這個模型框架的核心思想分不开關系。
因爲 Composer 主打的就是一個組合性,它是在文生圖 Diffusion 擴散的基礎上,更進一步,稱之爲可控擴散模型。
大家應該都知道,現在的主流 AI 繪圖模型基本上用的都是 Diffusion 擴散模型,Diffusion 擴散模型的訓練基本原理要說起來也非常簡單,就是給圖片加噪聲,然後通過神經網絡學習圖片加了噪聲和去了噪聲後是什么樣子,在生成圖片時,進行反向推理就行了。
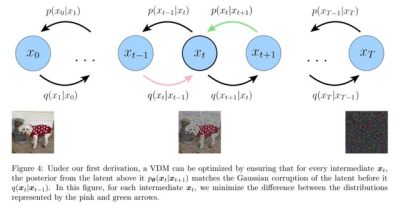
不過 Composer 既然加上了 “ 可控 ” 二字,必然有其獨到之處,爲了讓圖像的生成更有可控性,Composer 在進行加噪訓練前,還多了一個對圖片的重新拆解和組合的過程。
拆解的,就是圖片的一系列基本元素,比如线框,圖片中分割的物體蒙版,深度信息圖,顏色信息等等。
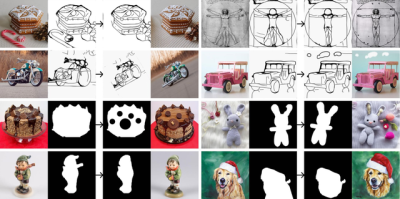
隨後,再把這些分割的元素圖,拿去做擴散模型的訓練,訓練出模型後,在推理階段重新組合。這樣,由於訓練時的數據量更多,而且對元素也有過分類訓練,在生成圖片時,就能對圖片中的各種細節元素,進行單一屬性的微調,大大增加了圖像生成的可控性和組合創造性。
以上說了這么多,都不如自己親自試用了解的快,而且碰巧,本次知危編輯部也獲得了定向邀測的資格,接下來咱們就測測這個通義萬相真實實力到底如何。
本次測試,通義萬相一共开放了三項功能,分別是基礎的文生圖功能,相似圖片生成,以及圖像風格遷移功能。
首先是文生圖功能,這個功能重點在於它對咱們輸入的中文語義理解如何,以及生成的圖片美感如何。
第一個挑战的是虛擬動漫風格,知危編輯部讓通義萬相生成一張:
“ 一只帶着黑色鴨舌帽的貓頭鷹,站在一塊滑板上,迪士尼畫風,月光灑在大地上。”
在通義萬相給出的幾張圖中,文字描述所提到的內容基本全部理解,貓頭鷹和背景畫的也不賴,算是完成的比較好。

隨後知危編輯部又讓通義萬相嘗試了一波寫實風格:
“ 末日廢墟,長滿雜草和植物,生鏽的人形機器人半埋在土裏,寫實風格。”
這一次稍微有點不太對,雖然通義萬相對前面場景描述的細節基本都還原了,但是整個畫面還是有濃烈的繪畫風格,對寫實這個關鍵詞並沒有把握住。

一开始,知危編輯部懷疑通義萬相是不是沒有太理解寫實這個詞,隨後又嘗試換了幾種說法和測試,比如換成攝影風格,或者說是拍攝照片,結果都不是特別好,當然橫向對比了幾波,通義萬相的表現已經是國產 AI 繪畫大模型裏表現最好的大模型之一了。

知危編輯部還發現,除了默認生成風格外,通義萬相還提供了幾種設定好的風格,不過也是全部偏繪畫風格,比如水彩,油畫,中國畫之類的,感覺有點特意避开寫實圖片的意思。

所以知危編輯部對於文生圖這個功能的評價是,中文的語義理解能力挺棒,整體不同風格生成的質量也較好,但是在寫實風格上略顯不足,畫面表現力和美感尚可。
接下來就是通義萬相的二號功能了,相似圖像生成。
這個功能需要提供一張素材圖片,交給通義萬相分析後,會根據圖像的各種特徵,生成類似風格的圖片。
知危編輯部嘗試的第一張照片,是一只羊駝。
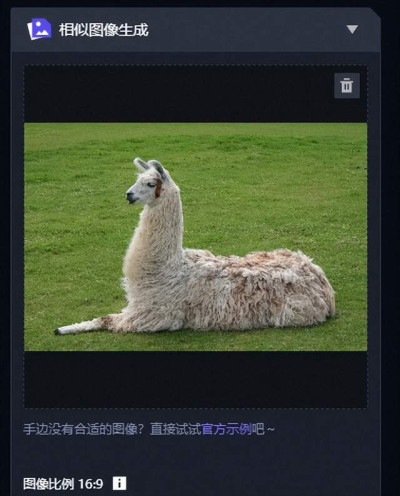
這是一張寫實的圖片,如果按照之前的文生圖的評測來看,它應該沒辦法生成非常寫實的類型。
不過讓知危編輯部意外的是,這次的相似圖片生成, 結果居然依舊很寫實。

可以看到通義萬相很好的提取出了畫面中的重點,一只羊駝和綠色草地,而且對草地和羊駝的形狀進行了重繪。
除了羊駝外,後續知危編輯部又使用了一些其它圖片來做相似圖片生成,比如這個透明泡泡的圖片,生成的相似圖片中,不僅保留了泡泡的外形和整體構圖,泡泡中的植物還進行了很多細節上調整。
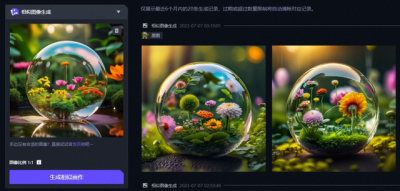
之後,知危編輯部還和設計部門的設計師們從實際應用方向討論了一下這個功能,他們都覺得這個相似圖片生成最厲害的地方在於,它能分清畫面中的主體到底是什么,比如這個泡泡明顯是一個主要的元素,而泡泡裏面的植物是可以進行多樣性的變化的。
這個看上去很小的點,實際上是顯示了通義萬相在對畫面結構分析上的厲害之處,在實際設計平面圖的過程中,如果 AI 能直接幫助分析主體,並且按照主要信息給你返多張相似圖片,那么對於提供設計素材的多樣性幫助還是非常大的。
接下來測試的最後一項功能就是圖像風格遷移了,這項功能會要求你提供兩張照片,一張是原圖,另一張則是需要遷移的風格,比如這裏知危編輯部就選擇了一張鄉村風景圖,讓通義萬相遷移成名畫《 星空 》的風格。
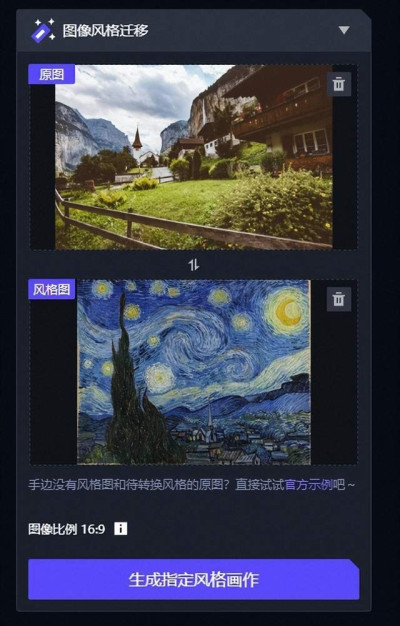
不過從最後的結果來看,首先,顏色風格肯定是變得更像《 星空 》了,但是整個畫畫的筆觸,知危編輯部感覺還沒有模仿到精髓。

隨後,知危編輯部又測試了幾個案例,發現這個風格遷移在元素相對簡單的畫像上,效果還是挺不錯的,比如把一只河馬的素描遷移成類似紙版畫風格。
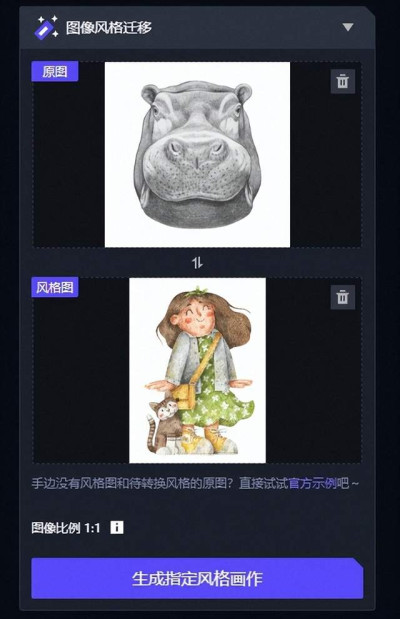
整個過程也就短短幾秒,最後出來的河馬也確實像那么一回事。

知危編輯部同樣問了問設計部門對這個功能的看法,據設計師們的說法,這個功能更像一個萬能的濾鏡,它方便之處在於,可以通過尋找自己想要的風格圖片,快速給素材套上這種風格的濾鏡,而平常如果要手工處理這種活,復雜的幹上一天都是有可能的。
但問題也是有的,現在對於一些特定的素材模仿其實並沒有那么到位,比如之前《 星空 》的那幅畫,在筆觸部分就沒有很好的呈現出來。
這次的測試下來,知危編輯部認爲通義萬相體驗還是非常不錯的,而且它在中文語義的理解上表現,也是讓整個測試過程無比輕松愉快。
現在的 AI 繪圖雖然已經是一個老話題了,但是目前把 AI 繪圖真正的往產品化發展,去針對設計師們的痛點提供工具的還是非常少的,而據阿裏方面人士回答,通義萬相目前的這三項功能未來還會改進,並且還會針對不同行業的不同需求,上线更多的繪畫功能。
其實 AI 的概念开始火起來之後,AI 繪圖算是率先滲透進各個行業的 AI 應用先驅,畢竟繪畫作爲一項非常古老的人類技藝,在如今的各行各業,多多少少都會有所涉及。
市場對繪畫和設計的需求,催生了 AI 繪圖巨大的市場,根據國泰君安的研報預計,到 2025 年,AI 繪畫在圖像內容生成領域滲透率將達到 30%,市場規模更是超 2000 億元。
包括遊戲,電影,廣告廠商等等產業都在被 AI 繪圖帶來的效率提升所變革,未來的產業發展中,想要和 AI 脫離關系,基本不可能。
這促進了 AI 繪圖應用的爆發式產出,基本上國內有訓練語言大模型的公司,都會在後續推出自己的 AI 繪圖產品。但產品的推出,只是第一步,AI 繪圖想要產品化,需要解決的問題還有很多,比如生成圖像的版權問題,生成內容的合法性問題,生成內容的多樣性和可控性問題等等。
這些,都需要大模型廠商們在未來好好研究和打磨。
畢竟能搶下這塊肥肉的,只會是那些真正在 AI 繪圖技術上創新和滿足用戶需求的少部分模型。
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:AI繪圖還在卷,阿裏新繪圖模型上线,圖片創作更精准可控
地址:https://www.breakthing.com/post/75686.html