




在摩爾定律驅使下,芯片發展的目標永遠是高性能、低成本和高集成。隨着單芯片可集成的晶體管數量越來越多,工藝節點越來越小,隧穿效應逐漸明顯,漏電問題越發凸顯,導致頻率提升接近瓶頸,爲進一步提升系統性能,芯片由單核向多核系統發展。
在後摩爾時代,先進工藝的研發成本過高,而市場需求變化又太快,導致應用碎片化嚴重,很難確保一顆大而全的芯片可以成功覆蓋所有需求,而過高的研發成本和因Die面積過大造成的良率下降也導致芯片成本大幅飆升。爲延續摩爾定律,採用多芯片異構集成的方式取代單一大芯片,以確保在可接受的成本下進一步提升集成度和性能,因此芯片系統也逐漸演進到衆核異構系統。
 什么是芯片互聯技術
什么是芯片互聯技術
進入到衆核時代,各大廠商不約而同的採用了多Die擴展的技術路线。
一是,有基板封裝技術(MCM),通過基板走线的方式進行Die間互聯,例如低功耗超短距離;二是,硅中介層技術(silicon interposer),在Die的底部加入一層硅,作爲中介層連接多個Die,蘋果就採用此方式;三是,嵌入式多芯互連橋技術(Embedded Multi-die Interconnect Bridge,EMIB),在基板制作過程中嵌入具有多個布线層的電橋,通過這些橋實現多Die間的互連,英特爾就採用此方式。
Arm 高級副總裁兼基礎設施總經理 Chris Bergey 表示:“CPU 設計的未來正在加速並向多芯片方向發展,這使得整個生態系統必須支持基於小芯片的 SoC。”
蘋果M1 Ultra Fusion

M1、M1 Pro、M1 Max、M1 Ultra的尺寸比較。管芯面積不斷擴大,分別有160億、337億、570億、1140億個晶體管。M1 Max 是 M1 的 3.5 倍,是 M1 Pro 的 1.7 倍,但 M1 Ultra 是 M1 Max 的兩倍。
蘋果M1 Ultra由 1140 億個晶體管組成,M1 Ultra 支持高達 128GB 的高帶寬、低延遲統一內存,支持 20 個 CPU 核心、64 個 GPU 核心和 32 核神經網絡引擎,每秒可運行高達 22 萬億次運算,提供的 GPU 性能是蘋果 M1 芯片的 8 倍,提供的 GPU 性能比最新的 16 核 PC 台式機還高 90%。
如此驚人的芯片,其技術的關鍵點在於將兩個 M1 Max 半導體裸片(半導體芯片體)連接在一起,形成一個兩倍大的 SoC。M1 Ultra,將兩個M1 Max 芯片拼在一起,使得芯片各項硬件指標直接翻倍。
現有的 PC 雙處理器配置通過主板上的布线連接兩個處理器。但是,在這種配置中,CPU之間的通信帶寬是有限的,因此會出現延遲,性能並不是簡單的翻倍,它還增加了功耗和發熱。
M1 Ultra 針對這個問題使用的互連技術被稱爲“UltraFusion”,使用了 10000 多個硅中介層(連接布线)並按原樣連接半導體管芯,而不通過外部電路。採用這種設計,互連部分的數據傳輸速度最高可達 2.5TB/秒。
最重要的是,內置在 M1 Max 中的指令調度程序將指令分配給雙倍的處理內核,並像單個 SoC 一樣運行。由於內存控制器也像集成一樣運行,因此整個內存通道增加了一倍,內存帶寬增加到每秒 800GB。
例如,一個M1Max中內置有10個核心的CPU,但是在連接兩個CPU的情況下增加到20個核心。將程序中的命令用哪個核心來處理,由調度器這個模塊來分配,但是M1Max的調度器假定有20個核心的CPU,指令緩衝區的數量也進行了優化。
英偉達、英特爾與AMD的選擇
英偉達超大規模計算副總裁 Ian Buck 表示:“小芯片和異構計算對於應對摩爾定律放緩至關重要。”
英偉達近日發布的數據中心專屬CPU Grace CPU超級芯片也採用了類似的方式。
該芯片由兩顆CPU芯片組成,其間通過NVLink-C2C技術進行互連。其鏈路的能效最多可比英偉達芯片上的PCIe Gen 5高出25倍,面積效率高出90倍,可實現每秒900GB乃至更高的帶寬。
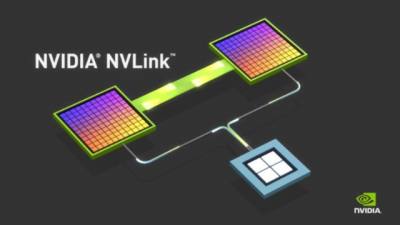
NVLink-C2C與近日英特爾和台積電、三星等多家科技廠商發起的UCIe標准有着異曲同工之妙,也是一種新型的高速、低延遲、芯片到芯片的互連技術,可支持定制裸片與GPU、CPU、DPU、NIC、SoC實現互連。
此前英特爾在Hotchips芯片上就展示過EMIB(嵌入式芯片互連橋)技術,單個基板中可以有許多嵌入式橋接,根據需要在多個裸片之間提供極高的 I/O 和良好控制的電氣互連路徑。
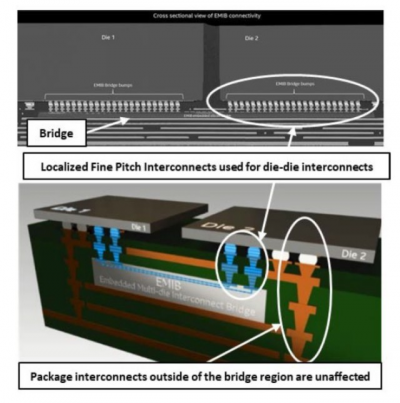
由於芯片不必通過帶有 TSV 的硅中介層連接到封裝,因此不會降低其性能。我們將微凸塊用於高密度信號,使用粗間距、標准倒裝芯片凸塊用於從芯片到封裝的直接電源和接地連接。
爲什么用芯片互聯技術?
對於目前的芯片技術來說,台積電5nm的制程工藝是已經能夠真正達到的業界頂尖工藝。但如果仍想在制程受到約束的情況下,推出性能更強的芯片,有兩種方式:第一,是再設計一款面積更大的芯片。第二,是將原來的芯片組合在一起使用,也就是說一次用兩顆。
但更大面積的芯片也是當前成電路發展面臨的困境之一,而當裸片面積越大,其良率就會越低,400平方毫米以上芯片良率降至20-30%,生產大面積裸片就意味着更多的壞點和更低的良率。而從一次用兩顆的方式來看,目前業界的主流通過主板 PCB 連接。
比如像華碩的 WS C621E SAGE 主板就屬於雙路 CPU 主板,在設計之初就支持兩塊 CPU 同時工作。
但這樣做缺點也很明顯,比如兩個 CPU 的插槽以及相應連接所需的布线明顯會佔用很大的 PCB 面積,這樣做出來的產品尺寸會很大。而且由於兩個 CPU 之間是通過 PCB 走线連接,延遲會變得很大。
通過主板 PCB 連接兩塊 CPU 所帶來的缺點基本都是連线過長導致的,這也是爲什么蘋果、英偉達、英特爾都紛紛看向封裝。
業內人士推測蘋果的UltraFusion 封裝架構至少是 InFO_LSI/CoWoS-L 的定制版本。在台積電宣布了兩個版本的硅橋技術InFO_LSI 和 CoWoS-L中, InFO_LSI 凸塊焊盤間距指定爲 25 m。這與Apple M1 MAX凸塊焊盤間距已壓縮至 25 m高度重合。
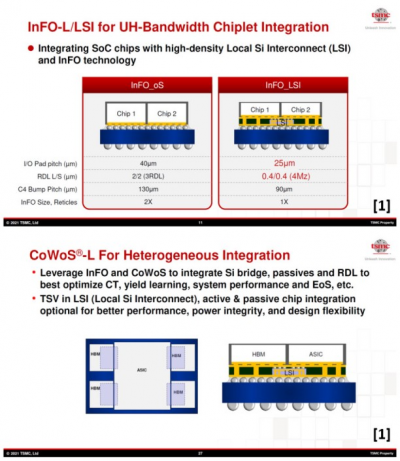 硅橋技術比較
硅橋技術比較
InFO_LSI 的 RDL(再分布層)线/空間尺寸爲 0.4/0.4 m,這意味着 I/O 密度爲 1250/mm/層。鑑於互連側的芯片邊緣長度超過 18 毫米,提供了超過 20000 個潛在的 I/O,遠遠超過 Srouji 引用的 10000 個。
2021 年 1 月,台積電總裁魏哲家在財報會議上透露:“對於包括 SoIC、CoWoS 等先進封裝技術,我們觀察到 chiplet 正成爲一種行業趨勢。台積電正與幾位客戶一起,使用 chiplet 架構進行 3D 封裝研發。
受限於不同架構、不同制造商生產的die(裸片)之間的互連接口和協議的不同,設計者必須考慮到工藝制程、封裝技術、系統集成、擴展等諸多復雜因素,同時,還要滿足不同領域、不同場景對信息傳輸速度、功耗等方面的要求,使得小芯片的設計過程異常艱難。而解決這些問題的最大難關就是沒有統一的標准協議。
一片火熱的互聯聯盟
英特爾、台積電、三星聯合日月光、AMD、ARM、高通、谷歌、微軟、Meta(Facebook)等十家行業巨頭共同宣布,成立小芯片(Chiplet)聯盟,並推出一個全新的通用芯片互聯標准——UCIe,以此共同打造小芯片互聯標准,推動开放生態建設。
UCIe的魅力在於可以將各個企業的Chiplet規定在統一的標准之下,這樣不同廠商、工藝、架構、功能的芯片就可以進行混搭,從而輕易地達到互通,並且還能實現高帶寬、低延遲、耗、低成本。
在UCIe聯盟當中並沒有英偉達與蘋果這兩大異構集成公司的身影,但從英偉達的了NVLink-C2C互連技術以及蘋果UltraFusion的提出可以看出,這兩大公司都不會缺席。
2022年4月2日,芯原股份宣布正式加入UCIe產業聯盟,成爲中國大陸首批加入該組織的企業。但目前國產廠商在UCIe聯盟中力量仍稍顯薄弱。如果這些行業大佬有意聯合起來,制定“新的遊戲規則”,下遊的終端企業將別無選擇,只有隨波逐流。但未雨綢繆,國內早已开始構建一套原生 Chiplet 標准。
2021 年 5 月,中國計算機互連技術聯盟(CCITA)在工信部立項了 Chiplet 標准,即《小芯片接口總线技術要求》,由中科院計算所、工信部電子四院和國內多個芯片廠商合作展开標准制定工作。
如今,距離這個制定工作已經過去了整整十個月,目前相關草案已經出爐,即將進入徵求意見的環節,然後再進行修訂,在年前完成技術驗證,在今年年底或者明年初再正式發布。
开放的小芯片生態系統對這一未來至關重要,主要行業合作夥伴可在UCIe聯盟支持下共同努力,實現改變行業交付新產品的方式並繼續兌現摩爾定律承諾的共同目標。
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:大勢所趨的芯片異構
地址:https://www.breakthing.com/post/7635.html