




如果 Nvidia 和 AMD 正在摩拳擦掌,想着他們可以將所有 GPU 賣給微軟,以支持其在生成人工智能方面的巨大抱負,特別是當涉及到 OpenAI GPT 大語言模型時(該模型是該公司所有未來軟件的核心和服務),他們最好再考慮一下。
從生成式人工智能爆發之初我們就一直在說,如果推理需要與訓練相同的硬件來運行,那么它就無法產品化。沒有人能夠負擔得起,即使是財力雄厚的超大規模提供商和雲構建商。
這就是爲什么微軟與華盛頓大學的研究人員合作,炮制了一個名爲 Chiplet Cloud 的小東西,從理論上講,它至少看起來在推理方面可以擊敗 Nvidia“Ampere”A100 GPU(而且對於較小的用戶來說),甚至還可以擊敗包括“Hopper”H100 GPU和運行 Microsoft GPT-3 175B 和 Google PaLM 540B 模型的 Google TPUv4 加速器。
Chiplet Cloud 架構剛剛在一篇基於 Shuaiwen Leon Song 牽頭的研究的論文中披露,Shuaiwen Leon Song 是太平洋西北國家實驗室的高級科學家和技術主管,也是悉尼大學和悉尼大學未來系統架構研究人員的記憶庫。華盛頓大學博士後,於今年 1 月加入微軟,擔任高級首席科學家,共同管理其Brainwave FPGA 深度學習團隊,並針對 PyTorch 框架運行其DeepSpeed 深度學習優化,這兩者都是微軟研究院 AI at Scale 系列的一部分項目。
這些研究並非毫無意義——正如您將看到的,我們真正的意思是——這些項目被 GPT 擊敗,迫使微軟在 Leon Song 加入微軟的同時向 OpenAI 投資 100 億美元。迄今爲止,微軟已向 OpenAI 提供了 130 億美元的投資,其中大部分將用於在微軟 Azure 雲上訓練和運行 GPT 模型。
如果我們必須用一句話來概括 Chiplet Cloud 架構(我們必須這樣做),那就是:採用晶圓級、大規模並行、充滿 SRAM 的矩陣數學引擎,就像 Cerebras Systems 設計的那樣,握住它在空中完美水平,讓它落在你面前的地板上,然後拾起完美的小矩形並將它們全部縫合在一起形成一個系統。或者更准確地說,不是用 SRAM 做晶圓級矩陣數學單元,而是制作大量單獨成本非常低且產量非常高(這也降低了成本)的小單元,然後使用非常快的互連。
這種方法類似於 IBM 對其 BlueGene 系列大規模並行系統(例如安裝在勞倫斯利弗莫爾國家實驗室的 BlueGene/Q)所做的事情與 IBM 在“Summit”超級計算機中對 GPU 重鐵所做的事情之間的區別。BlueGene 與日本 RIKEN 實驗室的“K”和“Fugaku”系統非常相似,從長遠來看可能一直是正確的方法,只是我們需要針對 AI 訓練、HPC 計算以及 AI 推理進行調整的不同處理器。
最近幾周,我們一直在討論構建運行基於 Transformer 的生成 AI 模型的系統的巨大成本,Chiplet Cloud 論文很好地闡述了爲什么 Amazon Web Services、Meta Platforms 和 Google 一直在努力尋找制造自己的芯片以使人工智能推理更便宜的方法。
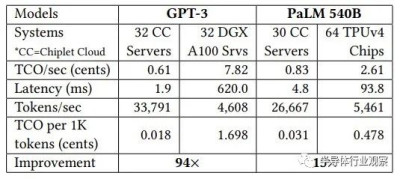
華盛頓大學的邁克爾·泰勒 (Michael Taylor)、胡萬·彭 (Huwan Peng)、斯科特·戴維森 (Scott Davidson) 和理查德·施 (Richard Shi) 等研究人員寫道:“在 GPU 等商用硬件上提供基於生成式Transformer的大型語言模型,已經遇到了可擴展性障礙。” “GPU 上最先進的 GPT-3 量爲每 A100 18 個token/秒。ChatGPT 以及將大型語言模型集成到各種現有技術(例如網絡搜索)中的承諾使人們對大型語言模型的可擴展性和盈利能力產生了疑問。例如,Google 搜索每秒處理超過 99,000 個查詢。如果 GPT-3 嵌入到每個查詢中,並假設每個查詢生成 500 個token,則 Google 需要 340,750 台 Nvidia DGX 服務器(2,726,000 個 A100 GPU)才能跟上。僅這些 GPU 的資本支出就超過 400 億美元。能源消耗也將是巨大的。假設利用率爲 50%,平均功率將超過 1 吉瓦,足以爲 750,000 個家庭供電。”
GPU(任何 GPU,而不僅僅是 Nvidia 創建的 GPU)的問題在於,它們是通用設備,因此必須擁有許多不同類型的計算來滿足所有用例。你知道這是真的,因爲如果不是這樣,Nvidia GPU 將只有 Tensor Core 處理器,而沒有矢量引擎。即使使用像 Google 的 TPU 這樣的設備(本質上只是一個 Tensor Core 處理器),該設備的尺寸和復雜性及其 HBM 內存堆棧也使其交付成本非常昂貴,至少根據微軟的比較,提供比 Nvidia A100 GPU 更好的總擁有成本 (TCO)。像這樣:
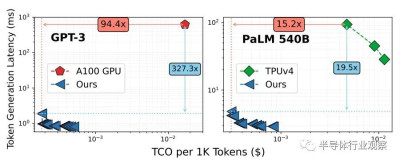
注意:這篇 Chiplet Cloud 論文獲得了Lamba GPU Cloud上 A100 容量的定價,當然,TPUv4 定價來自Google Cloud 。
這是上圖中所選參考數據點的數據,這很有趣:
在具有 1750 億個參數的 GPT-3 模型上,與 Nvidia 的 A100 GPU 相比,模擬的 Chiplet Cloud 設備每處理 1,000 個token的推理成本顯著降低了 94.4 倍,token生成延遲顯着降低了 327.3 倍。即使 H100 的量比 A100 高 3.2 倍(將 A100 上的 INT8 量與 H100 上的 FP8 量進行比較),我們也沒有理由相信即使使用 HBM3 內存,延遲也會有如此大的差異。我們的速度提高了 50%。即使是這樣,H100 的市場價格大約是 A100 目前價格的 2 倍。可以肯定的是,H100 會位於上圖中 A100 的下方和左側,但它還有很大的差距需要彌補。
轉向具有 HBM 內存的張量核心式矩陣數學引擎在一定程度上有所幫助,如上圖右側採用 TPUv4 計算引擎所示,甚至對於具有 5400 億個參數的更大的 PaLM 模型也是如此。Microsoft 的理論上的 Chiplet Cloud 顯示,運行推理時生成的每 1,000 個token的成本降低了 15.2 倍,延遲降低了 19.5 倍。
在這兩種情況下,微軟都在優化每個token的低成本,並以合理的延遲來支付費用。顯然,如果客戶愿意爲這些推斷支付相應更高的成本,那么通過 Chiplet 雲架構,它可以將延遲降低一點。
我們喜歡這張圖表,它顯示了爲什么超大規模企業和雲構建者正在考慮用於人工智能推理的定制 ASIC,特別是當大模型需要如此多的計算和內存帶寬來進行推理時:
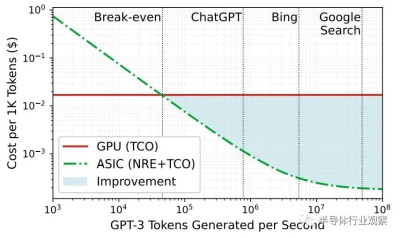
人工智能工作越密集,與使用 GPU 相比,使用 ASIC 的成本改進就越好,順便說一句,該圖表還表明微軟知道 Google 搜索比 Bing 搜索密集得多,而且成本也更低。
GPU 和定制 ASIC 之間的收支平衡點約爲每秒 46,000 個token。此性能基於在 Lamba GPU 雲上運行的 Microsoft 自己的 DeepSpeed-Inference 引擎,每個 GPU 的成本爲 1.10 美元/小時,而在模擬 Chiplet 雲加速器上運行的 DeepSpeed-Inference 則不同。
在設計 Chiplet Cloud 時,微軟和華盛頓大學的研究人員得出了一些結論。
首先,生產芯片的成本是任何計算引擎總體 TCO 的很大一部分。
根據我們的估計,GPU 佔現代 HPC/AI 超級計算機 98% 的計算能力,並且可能佔 75% 的成本。微軟估計,對於採用 7 納米工藝蝕刻的芯片,制造 LLM 推理加速器的成本約爲 3500 萬美元,其中包括 CAD 工具、IP 許可、掩模、BGA 封裝、服務器設計和人力成本。對於 400 億美元的潛在投資來說,這是微不足道的。
這意味着如果您想降低成本,就不能使用破壞性的計算引擎。微軟等人在論文中表示,對於台積電的7納米工藝,缺陷密度爲0.1個/cm,750 mm芯片的單價是150mm芯片的兩倍。
其次,推理既是一個計算問題,也是一個內存帶寬問題。
爲了說明這一點,不幸的是,使用較舊的 GPT-2 模型和同樣較舊的 Nvidia“Volta”V100 GPU,大多數 GPT-2 內核的操作強度較低,這意味着它們畢竟不需要太多的失敗,並且受到HBM2的900 GB/秒帶寬限制。此外,微軟計算出需要 85,000 GB/秒(幾乎增加了兩個數量級的帶寬)才能驅動 V100 GPU 中 112 teraflops 的計算能力來有效運行 GPT-2。
鑑於此,Chiplet 雲的祕密正是 Cerebras Systems、GraphCore 和SambaNova Systems 已經弄清楚的:獲取模型參數及其關鍵值中間處理結果,這些結果被回收以加速生成模型,矩陣數學引擎也盡可能接近地存儲到 SRAM 中,因爲DRAM 和 HBM 之間的差距是如此巨大:
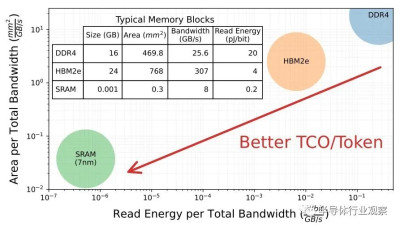
所以 SRAM 在這裏似乎是理所當然的。
另一件事是,微軟需要一種方法來降低小芯片設計的封裝成本,並限制芯片間通信,這會增加推理延遲並降低量。微軟正在使用chiplet作爲一個封裝,並在板級而不是socket字級進行集成,並使用張量和管道並行映射策略來減少Chiplet雲板上的節點間通信。每個chiplet都有足夠的SRAM來保存所有計算單元的模型參數和KV緩存。實際上,您擁有一個大規模分布式緩存,然後各個小芯片會在進行自己獨特的推理時對其進行咀嚼。
提議的 Chiplet Cloud 如下所示:
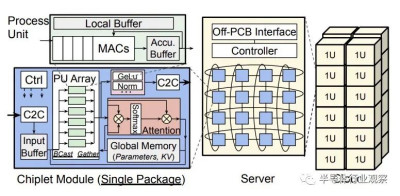
而且它沒有硅中介層或有機基板集成,這會增加成本和復雜性,並降低封裝級良率,這也是 GPU 和 TPU 等大型、fat、精彩設備的一個問題。該小芯片板使用印刷電路將一堆小芯片連接在 2D 環面中,微軟表示,這種電路足夠靈活,可以適應設備的不同映射。(這類似於 Meta Platforms 在使用 PCI-Express 交換作爲互連的 GPU 加速器系統的電路板上所做的事情。)電路板有一個 FPGA 控制器,每個小芯片都有一個以 25 GB 運行的全雙工鏈路/秒,使用地面參考信號,覆蓋範圍爲 80 毫米。微軟表示,其他類型的互連可以根據需要將節點連接在一起。
微軟表示,不同的模型需要不同的小芯片計算和內存容量,以及是否針對延遲或 TCO 進行優化。這確實非常有趣:
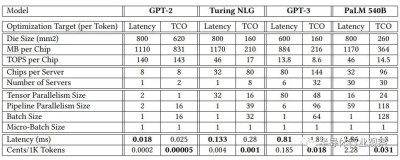
這裏的教訓是,一種方法不可能適合所有情況。你可以擁有更通用的東西,但你總是付出較低的效率。雲構建者需要通用設備,因爲他們永遠不知道人們會運行什么,除非他們只是打算針對專有軟件堆棧銷售服務,在這種情況下他們可以瘋狂優化並提供最佳性價比並保留一些剩余資金,只有當他們不過度優化(作爲利潤)時才會發生這種情況。
如果微軟向谷歌出售經過優化的Chiplet Cloud以運行5400億參數的 PaLM ,或者通過定制的 Chiplet Cloud 從 Google Cloud 搶走 TPU 客戶,這不是很有趣嗎?
我們不確定這個 Chiplet Cloud 有多少仍然是理論,或者它是否正在實施,或者它已經運行了一段時間。不管情況如何,微軟在研究上花了一些錢,現在擁有了對抗 Nvidia 和 AMD 的討價還價籌碼。
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:替代英偉達GPU,微軟有了新籌碼,成本大降!
地址:https://www.breakthing.com/post/77374.html