



圖像分割基本上可以分爲兩種類型:語義分割和實例分割。近些年,基於CNN的語義和實例分割的研究得到了大量的關注。作爲納斯達克上市企業“微美全息US.WIMI”旗下研究機構“微美全息科學院”的科學家們詳細探討了關於多種基於卷積神經網絡的語義分割模型。以下將詳細探討一些先進的基於CNN的語義分割模型的體系結構細節。模型是根據使用的最重要的特徵進行分類的。在每一個分類討論的最後,還簡要討論了特定模型類別的優點和缺點。
1. 基於完全卷積網絡
Long等人提出了完全卷積網絡(FCN)來解決語義分割問題。他們使用了AlexNet、VGGNet和GoogleNe(這三個都是在ILSVRC數據上預先訓練過的)作爲基本模型。他們將這些模型從classifiers轉變爲稠密的FCN,方法是用11卷積層代替完全連接層,並附加一個通道數爲21的11卷積來預測20個PASCAL VOC類和1個背景類的得分。
在FCN AlexNet、FCN-VGG16和FCN GoogLeNet中,FCN-VGG16在PASCAL VOC 2011驗證數據集上的准確度最高。因此,作者選擇FCN-VGG16網絡進行進一步的實驗。由於網絡生成了粗糙的輸出位置,作者使用雙线性插值對粗輸出32進行上採樣,使其像素密集。但是這種上採樣對於詳細的分割是不夠的。因此,他們使用跳躍連接來組合預測層和VGG16豐富的下層特徵,並將這種組合稱爲deep jet。圖1顯示了不同的deep jet:FCN-16s、FCN-8s和FCN-32s。其中FCN-8s在PASCAL VOC 2011中的表現最好。
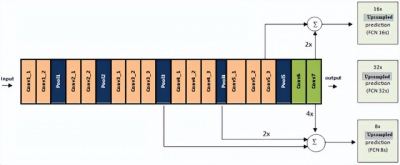
圖1.FCN32s, FCN16s, FCN8s的結構
FCN的主要變化有:基本模型VGG16、雙極插值技術(用於對原始特徵圖進行上採樣)和跳過連接(用於將低層和高層特徵結合起來以進行細粒度語義分割),這些都有助於該模型達到最新的結果。
FCN只利用局部信息進行語義分割,但由於局部信息會使圖像的全局語義上下文變得模糊。從整個圖像中減少模糊的上下文信息是很有幫助的。
2. 基於Dialatation卷積
Dialated-Net:傳統的CNN用於分類任務,會損失分辨率,不適合密集預測。Yu和Koltun引入了傳統CNN的改進版本,稱爲dialated卷積或Dialated-Net,系統地積累多尺度上下文信息,以便在不損失分辨率的情況下更好地進行分割。Dialated-Net就像一個卷積層的矩形棱鏡,不像傳統的金字塔CNN。如圖2所示,在不丟失任何空間信息的情況下,它可以支持指數擴展的感知域。
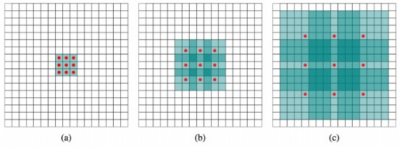
圖2.(a) 1倍dialation,感知域33;(b) 2倍dialation,感知域77;(c) 4倍dialation,感知域1515
基於dialation模型的優點是它有助於保持圖像的空間分辨率以產生密集的預測。但是,使用dialation卷積將圖像像素從其全局上下文中分離出來,這使得它很容易被誤分類。
3. 基於自上而下/自下而上的方法
DeconvNet由Noh等人提出,具有卷積和反卷積網絡。卷積網絡在拓撲上與VGG16的前13個卷積層和2個完全連接層相同,除了最後的分類層。反卷積網絡與卷積網絡相同,但層次相反。同時,它還具有多個系列的反卷積層、反池化層和反整流層。卷積和反卷積網絡的所有層都提取特徵映射,除了反卷積網絡的最後一層是用於生成像素級的概率圖,它與輸入圖像的尺寸相同。在反卷積網絡中,作者應用了反池化操作來重建初始激活大小。此處,反池化操作是通過在卷積操作時存儲的最大池索引來完成的。
爲了使放大但稀疏的反池化特徵圖的密度更大,作者將單個輸入激活與多個輸出相關聯,使用多個習得的濾波器完成類似卷積的操作。與FCN不同,作者將他們的網絡應用於從輸入圖像中提取出的目標建議,並產生像素級預測。然後,將所有建議的輸出集合到原始圖像空間,對整個圖像進行分割。這種基於實例的分割方法能夠處理多尺度對象的細節,同時降低了訓練的復雜度和訓練的內存消耗。爲了處理網絡中的內部協變量偏移,作者在卷積層和反卷積層之上添加了批處理規範化層。DevNet的架構如圖3所示。
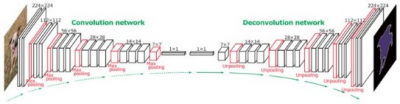
圖3. DeconvNet的網絡結構
由於基於FCN的模型在最後層的上採樣率很高,所以會產生粗輸出。因此,不可能進行精細的語義分割。另一方面,基於自上而下/自下而上方法的模型使用逐漸增加的上採樣率,從而獲得更精確的分割。但在這種情況下,該模型還缺少全局上下文信息的整合。
4. 基於全局語境的方法
ParseNet:Liu等人提出了一種端到端結構的ParseNet,它是對全卷積神經網絡的改進。爲了更好的分割,作者添加了全局特徵或全局上下文信息。圖4顯示了ParseNet的模型描述。在提取卷積特徵映射之前,ParseNet與FCN相同。之後,作者使用了全局平均池化來提取全局上下文信息。然後,對池化後的特徵圖進行反池化操作,使其與輸入特徵圖的大小相同。現在,將原始特徵圖和反池化後的特徵圖結合起來預測分類。作者將兩個不同的特徵圖組合在一起,而這些特徵圖在規模和標准上都是不同的。爲了使這種組合起作用,他們使用了兩個L2規範化層:一個是在全局池化層之後,另一個是在從FCN中提取原始特徵圖之後。該網絡在ShiftFlow,PASCAL context上達到了最先進的性能,在PASCAL VOC 2012數據集上接近最新水平。
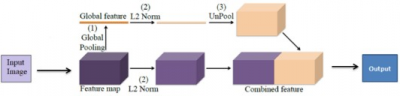
圖4. ParseNet的模型設計
雖然全局卷積的應用有助於提高精度,但它缺乏多尺度目標的尺度信息。
5. 基於感受野放大的方法
DeepLabv2和DeepLabV3:DeepLabv2和DeepLabV3的作者使用Atrous Special Pooling Pyramid(ASPP)修改了他們的網絡,聚集多尺度的特徵以更好地進行定位,並提出了DeepLabv2。圖5顯示了ASPP。該體系結構同時使用ResNet和VGGNet作爲基礎網絡。在DeepLabv3中,爲了將多個語境合並到網絡中,作者使用了級聯模塊,並對ASPP模塊進行了深入研究。
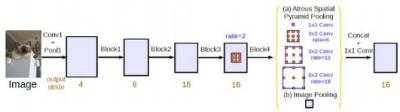
圖5. Atrous Spatial Pooling Pyramid
利用基於多分辨率金字塔的表示方法可以擴大感受野,這有助於上述模型融合對象的尺度信息,獲得精細的語義分割。但是,爲了獲得更好的語義分割,使用感受野擴大來捕獲語境信息可能不是唯一的解決方案。
微美全息科學院成立於2020年8月,致力於全息AI視覺探索科技未知,以人類愿景爲驅動力,开展基礎科學和創新性技術研究。全息科學創新中心致力於全息AI視覺探索科技未知, 吸引、集聚、整合全球相關資源和優勢力量,推進以科技創新爲核心的全面創新,开展基礎科學和創新性技術研究。微美全息科學院計劃在以下範疇拓展對未來世界的科學研究:
一、全息計算科學:腦機全息計算、量子全息計算、光電全息計算、中微子全息計算、生物全息計算、磁浮全息計算
二、全息通信科學:腦機全息通信、量子全息通信、暗物質全息通信、真空全息通信、光電全息通信、磁浮全息通信
三、微集成科學:腦機微集成、中微子微集成、生物微集成、光電微集成、量子微集成、磁浮微集成
四、全息雲科學:腦機全息雲、量子全息雲、光電全息雲
微美全息科學院旨在促進計算機科學和全息、量子計算等相關領域面向實際行業場景和未來世界的前沿研究。建立產研合作平台,促進重大科技創新應用,打造產業、研究中心深度融合的生態圈。微美全息科學院秉承“讓有人的地方就有科技”爲使命,專注未來世界的全息科學研究,爲全球人類科技進步添磚加瓦。
微美全息成立於2015年,納斯達克股票代碼:WiMi。
微美全息專注於全息雲服務,主要聚集在車載AR全息HUD、3D全息脈衝LiDAR、頭戴光場全息設備、全息半導體、全息雲軟件、全息汽車導航、元宇宙全息AR/VR設備、元宇宙全息雲軟件等專業領域,覆蓋從全息車載AR技術、3D全息脈衝LiDAR技術、全息視覺半導體技術、全息軟件开發、全息AR虛擬廣告技術、全息AR虛擬娛樂技術、全息ARSDK支付、互動全息虛擬通訊、元宇宙全息AR技術,元宇宙虛擬雲服務等全息AR技術的多個環節,是一家全息雲綜合技術方案提供商。
- 納斯達克(NDAQ)
- 微美全息(WIMI)
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:微美全息科學院:多種基於卷積神經網絡的語義分割模型
地址:https://www.breakthing.com/post/8074.html