




爲現代、領先的制造技術設計芯片是一項昂貴的工作。不過,根據台積電和新思科技披露的信息,已有數十家公司採用了 台積電的 N3 和 N3E(3 納米級)制造工藝。
Synopsys IP營銷和战略高級副總裁 John Koeter 表示:“用於台積電 3nm 工藝的 Synopsys IP 已被數十家領先公司採用,以加快其开發速度、快速實現芯片成功並加快上市時間。”
自 2022 年底以來,台積電一直使用其最新的 N3(又名 N3B)制造技術(最多 25 個 EUV 層並支持 EUV 雙圖案化)生產芯片,並打算开始採用其簡化的 N3E 制造工藝(最多 19 個 EUV層和沒有 EUV 雙圖案)在 2023 年第四季度。
此前,台積電透露,其 N3 節點已被高性能計算 (HPC) 和智能手機 SoC的設計者採用 ,並且在其生命周期早期,採用者數量比 N5 更高。與此同時,台積電從未提及有多少家公司決定使用其 3 納米級制造工藝。
Synopsys 是一家主要的 IP 开發商和電子設計自動化工具提供商,因此當它表示數十家公司已將其 IP 授權用於台積電的 N3 制造技術時,意義重大。但 Synopsys 並不是唯一的 IP 設計商,Cadence 等公司也向其他無晶圓廠芯片开發商提供其 N3 兼容 IP。可以肯定地說,他們的客戶數量也很可觀。
台積電的 N3 系列工藝技術包括基准 N3 (N3B)、寬松的 N3E(晶體管密度略有降低,但擴大了工藝窗口以提高產量)、與 N3E IP 兼容的性能增強型 N3P 將於 2024 年下半年投入生產, N3X 用於將於 2025 年推出的超高性能應用。
Synopsys 目前授權的 IP 可用於 N3、N3E 和 N3P 生產節點。
台積電官方論文,詳細解讀3nm
本文介紹了業界最快的3nm CMOS平台技術可行性。與傳統FinFET技術相比,首次引入了具有由不同鰭配置組成的標准單元的FinFlex™,以提供關鍵的設計靈活性,從而實現更好的功率效率和性能優化。與我們之前的5nm CMOS工藝相比,實現了約1.6X邏輯密度的大幅擴展、18%的速度提高和34%的功率降低。這種FinFlex™平台技術提供了一流的PPAC價值,以充分滿足5G和HPC應用中的產品創新。
簡介
近年來,人工智能應用的激增和5G的部署一直是數據中心高性能計算以及邊緣設備低功耗聯網和處理能力的驅動力。隨着機器學習在需要快速和准確處理大數據的廣泛行業中被迅速採用,HPC正成爲下一個關鍵的增長動力。具有最高性能和最佳功率效率的先進CMOS邏輯技術比以往任何時候都更重要,它將爲我們的日常生活和社會的各個方面帶來創新。
本文介紹了最先進的3nm平台技術,該技術具有目標器件性能、標准單元設計和關鍵基本規則的擴展創新。除了成功地將批量FinFET擴展到3nm節點之外,FinFlex™標准單元創新還提供了多單元架構所需的更大設計靈活性。該技術與跨越200mV的6 Vt產品相結合,提供了前所未有的設計靈活性,以最具競爭力的邏輯密度滿足廣泛的功率效率SoC需求和HPC應用的高性能需求。這一過程已在由高密度和高電流SRAM宏和邏輯測試芯片組成的开發測試車上得到驗證。
設計靈活性–FinFlex™和多Vt
FinFlex™是一種具有不同散熱片配置的創新標准單元架構,首次在這項3nm技術中引入。伴隨着關鍵層的傳統間距縮放,它實現了全節點的邏輯密度增加。爲了進一步減少FinFET的面積,業界採用的典型方法是翅片間距縮放和翅片數量減少。隨着翅片間距已經低於30nm,翅片數量減少到單個翅片,工藝變化和設備驅動能力不足成爲進一步擴大規模的主要障礙。FinFlex™提供了如圖1所示的幾種配置,以解決縮放和性能之間的權衡問題。2-1鰭配置實現了面積減少,而不犧牲功率敏感應用的性能。二鰭器件可用於關鍵路徑以利用其更高的電流,而單個鰭用於減少漏電流,它是迄今爲止密度最高功耗最低的標准單元。類似地,3-2鰭配置,配備3鰭以獲得更高的驅動電流,非常適合性能要求高的應用。在需要性能、功率和密度之間的良好平衡的情況下,可以應用常規的2-2鰭配置。與常規標准單元中僅具有晶體管級電容減少的簡單鰭片切割不同,FinFlex™通過共同優化BEOL位置和路徑,提供單元級面積縮放以及芯片級電容減少。此外,在該技術中有6種不同的Vt產品,設計者可以爲單個N/PMOS選擇不同的鰭數和Vt組合,以滿足同一芯片上的寬範圍速度和泄漏要求。圖2顯示了與我們的5nm節點相比,此3nm FinFlex™技術的ARM Cortex-72 CPU性能和面積改進。功率效率高的2-1cell在0.64X區域顯示出30%的功率降低和11%的速度增益;高性能3-2配置,在0.85X面積下速度增益33%,功率降低12%;並且在0.72X區域,平衡的2-2單元23%的速度增益和22%的功率降低。這一創新是成功延長FinFET架構壽命的關鍵組件之一,適用於另一個全技術節點。
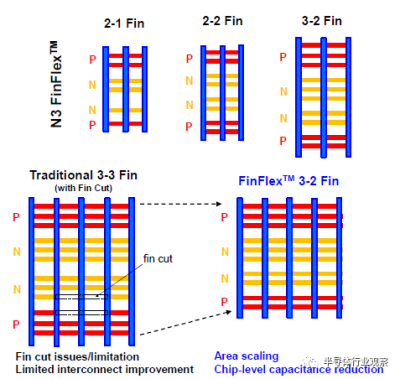
圖1 FinFlex™示意圖以及與傳統方案的比較。與傳統FinFET設計相比,面積減少和芯片級電容顯著減少是該創新的主要優勢。
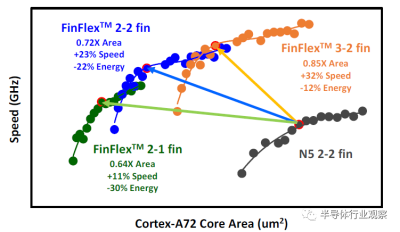
圖2 ARM Cortex-A72中的FinFlex™改進。FinFlex™ 2-1鰭配置的目標是超功率效率、2-2鰭高效功率和3-2鰭超高性能。每種配置都顯示了N5技術的不同面積、速度和能效改進。
工藝架構
除了新穎的標准單元特性外,還採用了臨界接地規則進行縮放,以實現比以前的5nm節點提高約1.6X的邏輯密度。在不同的鰭片布置中,鰭片寬度和外形優化在減小的柵極長度下保持所需的短溝道效應。實施低K間隔物以減少接觸和柵極之間的寄生電容,而不影響產量和可靠性。具有雙外延工藝的凸起源極/漏極被優化以提供溝道應變並降低源極/漏電極(S/D)電阻。第六代高K金屬柵極(HK/MG)RMG工藝支持內核和I/O器件。新的接觸方案和工藝解決方案在生產线的中降低了緊密CPP縮放的寄生電阻,同時保持了可觀的產量和可靠性。我們還开發了先進的Cu/低k互連方案,該方案具有積極縮放的最小金屬間距工藝。創新的屏障和襯墊工程以及圖案化優化使BEOL金屬和通孔RC保持在軌道上,而不會因縮放而影響芯片性能。
晶體管性能
基於品質因數(FOM),該3nm技術的2-1鰭配置提供了18%的等功率速度增益,或在相同速度下比我們的5nm技術降低了34%的功率,如圖3所示。我們優化了鰭的寬度和輪廓,以在目標縮放Lg(圖4)處獲得約50mV/V的DIBL,證明FinFET在3nm節點處仍然是可行的架構。FOM性能以及NMOS和PMOS器件分別實現了該技術的目標性能,如圖5和圖6所示。爲了充分實現FinFlex™的預期效益,消除可能降低固有翅片性能的翅片數量差異引起的負載效應至關重要。單鰭器件尤其脆弱,因爲許多工藝步驟,例如蝕刻和外延,自然地與多鰭結構所經歷的工藝步驟不同。圖7顯示,經過工藝優化後,2-1鰭配置的單鰭器件與設計一樣,其二鰭對應器件的有功功率約爲50%。對於高速應用,如圖8所示,3-2鰭配置的速度增加了9%以上。六種電壓範圍>200mV的不同Vt選項(圖9)可供選擇,以進一步提供電源性能權衡的設計靈活性。由於器件變化在設計裕度預算中變得越來越重要,因此我們還實施了專門針對對抗變化的工藝改進,以將NMOS和PMOS的器件Vt失配(AVt)降低20%,如圖10所示。對於I/O器件,圖11中的LDD注入優化根據SCE控制所需的鰭輪廓將Iboff降低了2個數量級以上。
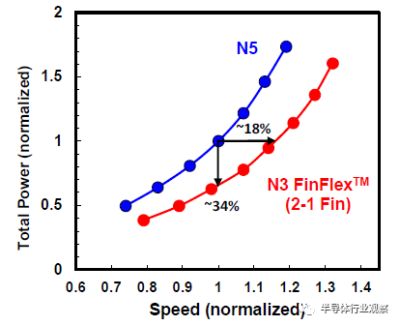
圖3 FinFlex™ 2-1cell在固定功率下提供18%的SPD增益或在固定速度下降低34%的功率
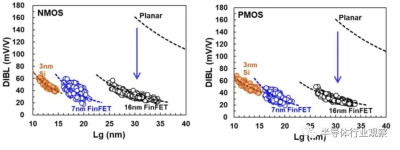
圖4 FinFET SCE的改進繼續支持3nm技術所需的Lg縮放。
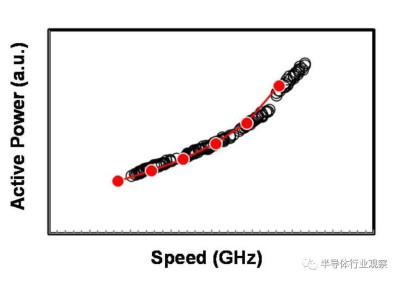
圖5 品質因數(FOM)結構實現了所有Vt的目標功率速度性能。
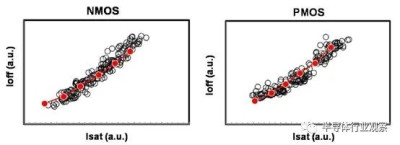
圖6 NMOS和PMOS器件都顯示了目標性能。
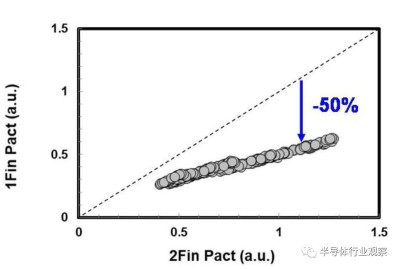
圖7 1-fin器件顯示出50%的有功功率降低,不存在工藝負載引起的退化。
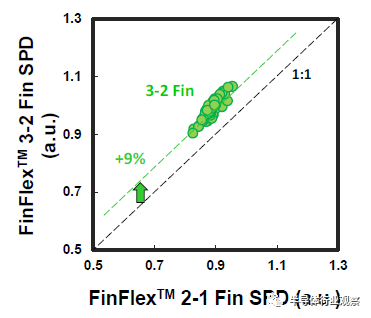
圖8 FinFlex™ 3-2鰭具有額外的9% SPD增益。
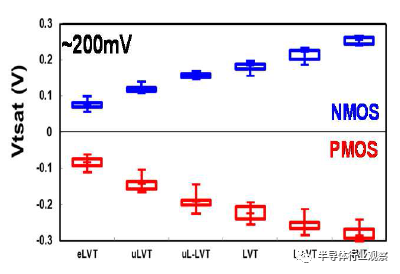
圖9 六種不同的Vt選項,跨度約200mV。
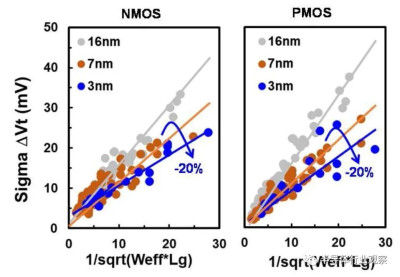
圖10 展示了優異的失配性能。
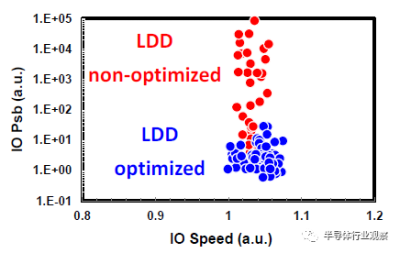
圖11 I/O器件Psb與速度的關系。通過LDD優化,Iboff顯著降低。
互連技術
互連工藝在決定芯片整體性能方面發揮了越來越重要的作用。對於這種3nm技術,23nm處的最小金屬間距用於實現FinFlex™ 2-1鰭配置的縮放,同時提供所需的布线效率。據我們所知,這是迄今爲止在高級節點中報告的最緊密的金屬間距。採用了創新的Cu襯墊,以將標稱金屬寬度的最小間距RC降低20%,將2X金屬寬度的結構RC降低30%,如圖12所示。基於圖13中的創新屏障工藝,過孔Rc顯著降低了約60%,這是實現這種激進間距縮放的重要組成部分。通過檢查M0和Mx層的A线與B线的金屬電阻,圖14中A线和B线之間的可比分布證明了工藝的魯棒性。在上部松弛金屬節距以及ELK電介質處減少阻擋層厚度,以最小化總體BEOL RC延遲。圖15顯示了15級Cu/低k金屬堆疊的橫截面圖。對於6級和15級金屬,堆疊接觸到通孔鏈的緊密Rc分布證明了該封裝的穩定性。同時還對BEOL過程集成的可靠性進行了檢驗。圖16(a)和16(b)分別驗證了最小間距金屬的Vx/Mx和Vx/Mx+1的優異EM性能和互連SM穩定性。在應力500小時後,具有規則和寬金屬的Kelvin Rc結構的電阻偏移百分比可忽略不計。此外,上一代中需要EUV雙圖案化的三個關鍵層被單EUV圖案化所取代,這降低了工藝復雜性、固有成本和循環時間。
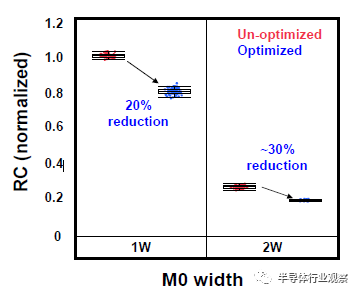
圖12 間距23nm金屬线RC的增加,由創新的銅襯墊工藝控制。
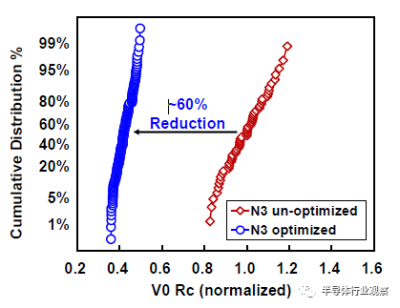
圖13 通過創新的屏障工藝,在最緊密的間距處顯著降低Rc。
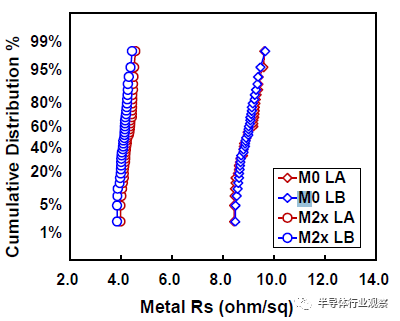
圖14 A线和B线在大幅縮放間距下的M0/Mx金屬電阻分布。
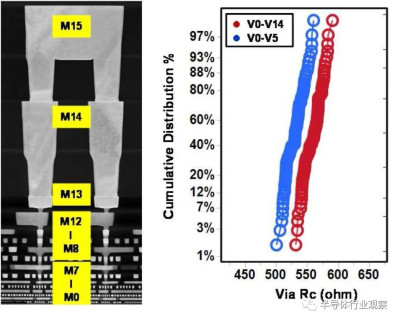
圖15 15層金屬疊層的TEM圖像和通孔Rc疊層的緊密分布。
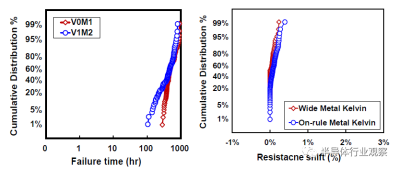
圖16(a)最小螺距金屬的EM性能;(b) Kelvin結構的SM。
產量和可靠性
HD和HC SRAM單元可用於低泄漏和高性能應用。由HD和HC 6-T SRAM 256Mb宏以及帶有CPU/GPU/SoC塊的邏輯測試芯片組成的產量學習工具可用於技術开發。0.021um2 HD SRAM單元的蝶形曲线如圖17所示,其中顯示了低至0.3V的單元穩定性。對於0.45V和0.6V操作,靜態噪聲容限(SNM)分別達到97mV和124mV。圖18中256Mb HD SRAM宏的Shmoo圖顯示了低至0.5V的完整讀寫能力。256Mb HC/HD SRAM宏和類似產品的邏輯測試芯片在同一开發階段始終顯示出比我們的前幾代更健康的缺陷密度。此外,兩個256Mb HC/HD SRAM宏都通過了HTOL 1000小時鑑定(如圖19所示),邏輯測試芯片通過了CPU的Vmin功率規格(如圖20所示)。
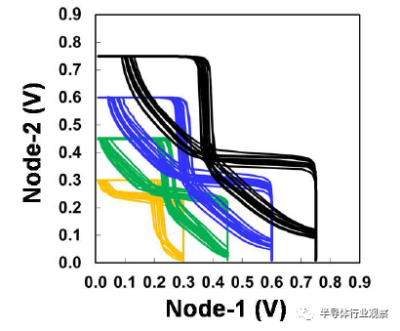
圖17 0.021um高密度6-T SRAM單元的SNM。
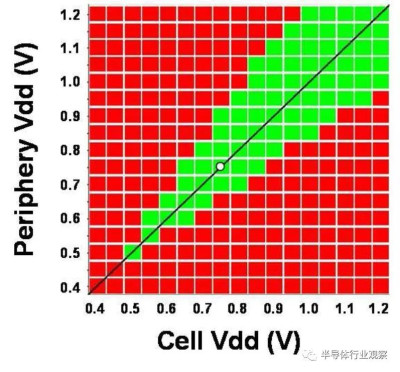
圖18 0.021um HD 256Mb SRAM宏的Schmoo圖,具有低至0.5V的完整讀/寫功能。
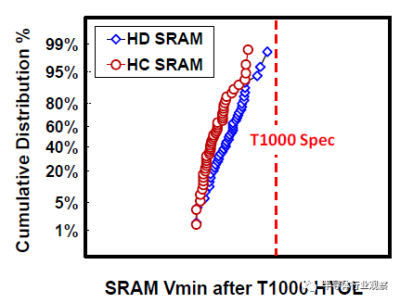
圖19 HC/HD 256Mb SRAM均通過HTOL 1000小時規格。

圖20 Vmin對邏輯測試芯片中CPU塊的IDDQ。
結論
我們引入了業界領先的3nm FinFlex™ CMOS制造技術,該技術具有創新的設計靈活性和廣泛的Vt選項。利用這一新的DTCO功能,可以將具有針對性能、功率和/或面積目標進行優化的不同功能塊的產品設計集成在同一芯片上。加上關鍵的基本規則縮放和23nm的最小金屬間距,該技術提供了迄今爲止最高密度的同類最佳邏輯性能、功率效率和低Vmin SRAM。隨着器件性能達到設計目標和工藝引起的變化得到適當解決,高性能HPC應用以及功率敏感SoC產品的苛刻要求都可以得到很好的滿足。各種5G移動和AI/HPC應用的大規模生產技術成熟度已得到充分證明,該技術經過嚴格的技術鑑定,將保證穩定的產量和強大的可行性。
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:數十家芯片廠,用上了台積電3nm?
地址:https://www.breakthing.com/post/82989.html