





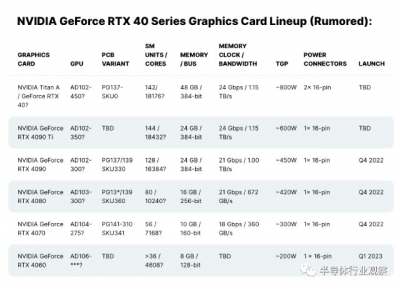
最近,博主Kopite7kimi報告了有關英偉達旗艦芯片 NVIDIA Ada Lovelace GPU SKU 的詳細信息,這使它看起來像是有史以來最強大的終極圖形芯片。傳聞指出,NVIDIA Ada Lovelace 旗艦 GPU 採用 AD102-450 GPU,具有 18176 個內核、48 GB“24 Gbps”GDDR6X 顯存和 800W TBP.
這不是第一次談論如此高端的 Ada Lovelace GPU SKU。之前的傳言也來自同一個泄密者,它報道了 Ada Lovelace GPU 陣容中的 Titan-Class 顯卡,該顯卡具有一些瘋狂的規格。再一次,這不是完全啓用的 AD102 GPU,而之前的變體被提及爲具有完整 18432 CUDA 內核的 900W TBP SKU。
根據傳聞的規格,該顯卡將採用 Ada Lovelace 架構並具有略微縮減的配置“AD102-450-A1”,在 18,432 個 CUDA 內核(18432 個 CUDA 中)上搖擺 142 個 SM(144 個 SM)核心)。基於大約 3 GHz 的時鐘速度,這款顯卡將輕松突破 100 TFLOPs 計算障礙。據說該顯卡配備 48 GB GDDR6X 內存,運行在 384 位總线接口上。
有趣的是,NVIDIA 不會拘泥於 VRAM 規格,而是採用最新的 24 Gbps 內存模塊,爲 GPU 提供高達 1.152 TB/s 的 VRAM 帶寬。與具有 21 Gbps 內存芯片的現有 RTX 3090 Ti 旗艦產品相比,內存帶寬增加了 14%。即將推出的 RTX 4090 也有望使用相同的 21 Gbps 內存芯片,只有旗艦“Ti”型號獲得 24 Gbps 芯片。
功耗方面,新的NVIDIA旗艦AD102 GPU驅動的顯卡將是瘋狂的,其TDP幾乎是RTX 3090 Ti的兩倍,額定功率高達800W。考慮到單個 16 針連接器只能提供 600 瓦的功率,如果它成爲現實,就必須爲這種卡的怪物使用雙 16 針連接器配置。圖形卡可以使用 PG137-SKU0。
基於 Ampere 陣容,我們看到 NVIDIA 不僅沒有發布 Titan 顯卡,而且實質上用其 BFGPU 級 GeForce RTX 陣容取代了 Titan 系列。更高容量的卡仍然作爲工作站 RTX Axxx系列推出,它也得到了完整的 GA102 處理,但除了RTX 3090 Ti和RTX A6000之外,沒有 Titan 級。那么 Titan 級 GPU 對 Ada Lovelace 是否有意義,或者這個特定的 SKU 最終會成爲下一代遊戲 BFGPU 和工作站的旗艦產品嗎?好吧,我們不能肯定地說,但有一件事是絕對正確的,這樣的 GPU 配置在規格、功耗和價格方面確實是瘋狂的。該卡如果涉及零售,肯定會在RTX 4090之後推出預計將於今年秋季晚些時候亮相。
Nvidia Ada Lovelace 和 GeForce RTX 40 系列:我們所知道的一切
Nvidia 的 Ada 架構和 GeForce RTX 40 系列顯卡預計將於今年年底上市,並且可能在 9 月至 10 月的時間範圍內——發生在Nvidia Ampere 架構之後的兩年,考慮到摩爾“定律”的放緩(或者如果你愿意,死亡),英偉達這個發布步驟基本上是按計劃進行的。隨着今年早些時候的Nvidia 遭受黑客攻擊,我們獲得了關於預期結果的大量信息。我們已將所有內容收集到這裏,詳細介紹了我們對 Nvidia 的 Ada 架構和 RTX 40 系列家族的了解和期望。
現在有很多謠言在流傳,但英偉達幾乎沒有透露其對 Ada 的計劃,有些人將其稱爲 Lovelace。我們所知道的是,Nvidia 已經詳細介紹了其數據中心Hopper H100 GPU,我們懷疑,就像Volta V100和Ampere A100一樣,消費產品將在不久的將來跟進。
最後一個可能是預期的最佳樣本。A100 於 2020 年 5 月正式發布,消費級 Ampere GPU 以RTX 3080和RTX 3090的形式推出大約四個月後。如果 Nvidia Ada Lovelace GPU 遵循類似的發布時間表,我們可以預期 RTX 40 系列將在 8 月或 9 月的某個時候到貨。讓我們從 Ada 系列 GPU 的傳聞規格的高級版本預覽开始。
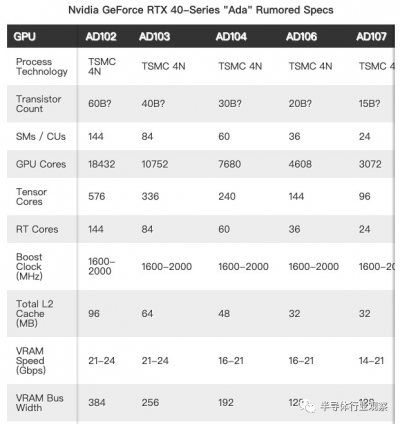
首先,根據預計,GPU 提供了介乎 1.6 到 2.0 GHz 的暫定時鐘速度估計值,這與 Nvidia 之前的 Ampere、Turing 甚至 Pascal 架構一致。Nvidia 完全有可能超過這些時鐘,因此我們認爲這是一個保守的估計。
我們假設 Nvidia 將在所有 Ada GPU 上使用 TSMC 的 4N 工藝——“4nm Nvidia”,這在技術上可能又是不正確的。我們知道 Hopper H100 使用台積電的 4N 節點,這似乎主要是對台積電 N5 節點的調整變體,該節點已廣泛用於蘋果的智能手機和筆記本電腦芯片,並且據傳聞,Nvidia 會將該節點用於 Ada。值得一提的是, AMD也有可能將其用於Zen 4 和RDNA 3。
坦率地說,節點名稱並不像實際的 GPU 規格和性能那么重要。換句話說,“任何其他名字的玫瑰都會聞起來很香”。我們早就過了工藝節點名稱與芯片上的物理特性有任何實際聯系的年代。在 250nm(或 0.25 微米)芯片實際上具有可以指向並以 0.25um 寬度進行測量的元素時,芯片的物理縮放在過去的幾個工藝節點上已經放緩,它們現在只是營銷名稱。
晶體管數量是目前最好的猜測。我們確實知道 Hopper H100 將擁有 800 億個晶體管(這實際上只是一個近似值,但我們會繼續使用它)。A100 GPU 有 560 億個晶體管,是 GA102 消費級 halo芯片數量的兩倍,但有跡象表明 Nvidia 將在 AD102 GPU 上“做大”,而且它的尺寸可能更接近 H100,而不是 GA102 . 如果有可靠的信息可用,我們將更新這些表格,但目前,任何關於晶體管數量的說法都只是與我們不同的猜測。
理論上,根據我們目前看到的“泄露”信息,Ada看起來是個怪物。與當前的 Ampere GPU 相比,它將包含更多的 SM 和相關內核,這將大大提高性能。即使 Ada 最終比泄漏所聲稱的要少,可以肯定的是,我們會看到頂級 GPU 的性能——也許是 RTX 4090,盡管 Nvidia 可能會再次改變命名法——不過毫無疑問,新產品將是領先RTX 3090 Ti 的一大進步.
例如,RTX 3080 在發布時比 RTX 2080 Ti 快了大約 30%,而 RTX 3090 又增加了 15%,至少如果你以 4K 超分辨率將 GPU 推到極限的話。這也是需要牢記的。如果您當前運行的是更適中的處理器,而不是絕對最好的遊戲 CPU 之一(Core i9-12900K或Ryzen 7 5800X3D),這意味着即使在 1440p 超分辨率下,你也很可能會限制 CPU。爲了充分利用最快的 Ada GPU,可能需要進行更大的系統升級。
在高級版本簡介完畢之後,讓我們進入細節。
一
ADA 將大幅提升計算性能
與當前 Ampere 代相比,Ada GPU 最顯著的變化將是 SM 的數量。據猜測,AD102 包含的 SM 可能比 GA102 多 71%。即使架構沒有其他任何重大變化,我們也預計性能會大幅提高。
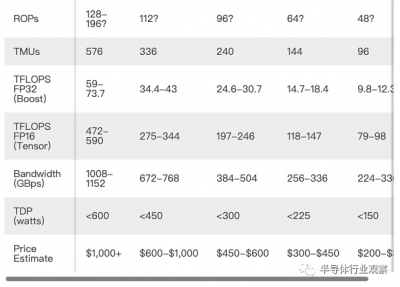
這不僅適用於圖形,也適用於其他元素。我們在 Tensor 核心性能上使用安培計算(Ampere calculations),運行頻率接近 2GHz 的完全啓用的 AD102 芯片將在 FP16 中具有高達 590 TFLOPS 的深度學習/AI 計算。相比之下,RTX 3090 Ti 中的 GA102 最高約爲 321 TFLOPS FP16(使用 Nvidia 的稀疏特性)。根據核心數量和時鐘速度,新產品理論上增加了 84%。理論上 84% 的性能提升同樣適用於光线追蹤硬件。
除非 Nvidia 爲各自的第三代和第四代實現重新設計 RT 內核和 Tensor 內核。我們懷疑不需要對 Tensor 內核進行大規模更改——Hopper H100 的深度學習硬件的重大改進將比 Ada AD102 更多。同時,RT 內核可以很容易地看到每核 RT 性能比 Ampere 再提高 25-50% 的改進,就像 Ampere 每個 RT 內核比 Turing 快 75% 左右一樣。
最壞的情況,只是將 Ampere 架構從三星 Foundry 的 8N 工藝移植到 TSMC 的 4N(或 5N 或其他),並沒有真正改變架構的任何其他內容,添加更多內核並保持類似的時鐘應該提供足夠的一代性能提升. Nvidia 的表現可能遠遠超過最低要求,但即使是位於底部的AD107 芯片也比當前的 RTX 3050快30% 或更多的改進。
請記住,列出的 SM 數量是完整的芯片,而且很可能 Nvidia 將使用部分禁用的芯片來提高良率。以 Hopper H100 爲例,它有 144 個潛在的 SM,但在 SXM5 變體上僅啓用了 132 個 SM,而 PCIe 5.0 卡將啓用 114 個 SM。我們可能會看到 Nvidia 推出高端 AD102 解決方案(即 RTX 4090),其中啓用了 132 到 140 個 SM,較低層型號使用更少的 SM。在良率提高後,這當然爲未來帶有完全啓用 AD102 的卡(即 RTX 4090 Ti)打开了大門。
二
猜測 ADA 的 ROP
我們在所有 Ada GPU 上的 ROP 計數(渲染輸出)之後加上了問號,因爲我們還不知道它們是如何配置的。通過 Ampere,Nvidia 將 ROP 與 GPC(圖形處理集群)聯系起來。每個 GPC 包含一定數量的 SM(流式多處理器),可以成對禁用。然而,即使我們知道 SM 的數量,我們也不知道它們是如何分成 GPC 的。
以帶有 144 個 SM 的 AD102 爲例。這可能是 12 個 GPC,每個 12 個 SM,8 個 GPC,每個 18 個 SM,或 9 個 GPC,每個 16 個 SM。其他可能性也存在,但這是我們認爲最有可能的三種。Nvidia 對 GPU 遊戲並不陌生,因此無論安排如何,最終我們都應該期望它能夠滿足 GPU 的需求。
我們已經看到一些猜測表明 GA102 將有 12 個 GPC,每個 GPC 有 12 個 SM,這將產生 192 個 ROP 作爲最大值。這不是不可能的,但請注意,Hopper H100 有 8 個 GPC 集群,每個集群有 18 個 SM,因此這對於 AD102 來說似乎也是一個合理的配置——只是沒有 HBM3 並且較少關注深度學習硬件。
三
可疑的泄密和謠言
此外,AD102 的 144 個 SM 是令人懷疑的。巧合的是,Hopper H100 芯片共有 144 個 SM,其中 132 個在目前的頂級產品中啓用。對於 Ada 和 Hopper 都擁有相同的 144 個 SM 來說,這將是非常令人驚訝的。GA100 最多有 120 個 SM,因此,對於 H100,Nvidia 僅將 SM 數量增加了 20%。相比之下,假設泄密信息是真的,那就意味着AD102 的 SM 比 GA102 多 71%。
我們現在沒有更好的事情要做,所以我們報道了傳聞中的 144 SM 數字,但如果這完全是假的,請不要感到驚訝。僅僅因爲 Nvidia 被黑客入侵並且數據被泄露,並不意味着泄露的所有內容都是准確的。Nvidia 可能會更好地調整架構以獲得更高的時鐘並使用更少的 SM,類似於 AMD 對 RDNA 2 所做的,但這可能需要對底層架構進行更重大的改革。
另一方面,AD102 成爲巨大芯片至少有一個充分的理由——專業 GPU。Nvidia 並未爲消費者和專業市場制造完全獨立的芯片,RTX A6000 等 A 系列芯片就是明證。它使用與 RTX 3080 到 3090 Ti 相同的 GA102 芯片,只是在驅動程序中打开了一些額外的功能。光线追蹤並沒有真正讓遊戲世界着火,但它對專業市場來說是一件大事,並且封裝更多的 RT 核心將是 3D 渲染用戶的福音。另請注意,Hopper H100 不包含任何光线追蹤硬件,就像它所取代的 GA100 一樣。
各種 Ada GPU 也將用於運行 AI 和 ML 算法的推理平台,這再次意味着可以使用更多的 Tensor 內核和計算。因此,最重要的是,假設的最大 144 個 SM 並不是完全不可能的,但它肯定值得懷疑。也許英偉達黑客發現了過時的信息,或者人們錯誤地解釋了它。在接下來的幾個月裏,我們會知道更多。
四
內存子系統:GDDR6X 再上新台階
早前,美光宣布它擁有運行速度高達 24Gbps 的 GDDR6X 內存的路线圖。最新的 RTX 3090 Ti 僅使用 21Gbps 內存,而 Nvidia 是目前唯一一家使用 GDDR6X 的公司。這立即引發了將使用 24Gbps GDDR6X 的問題,唯一合理的答案似乎是 Nvidia Ada。較低層的 GPU 更有可能堅持使用標准 GDDR6 而不是 GDDR6X,其最高速度爲 18Gbps。
這代表了一個問題,因爲 GPU 通常需要計算和帶寬來按比例擴展以實現承諾的性能量。例如,RTX 3090 Ti 的計算量比 3090 多 12%,更高的時鐘內存提供了 8% 的帶寬。如果我們上面的計算估計證明甚至接近准確,那么就會出現巨大的脫節。假設的 RTX 4090 的計算量可能比 RTX 3090 Ti 多 80%,但帶寬僅多 14%。
假設可以控制 GDDR6X 功耗,那么在較低級別的GPU 上帶寬增長的空間要大得多。當前的 RTX 3050 到 RTX 3070 都使用標准 GDDR6 內存,主頻爲 14-15Gbps。我們已經知道運行在 18Gbps 的 GDDR6 將及時爲 Ada 提供,因此具有 18Gbps GDDR6 的假設 RTX 4050 應該可以輕松跟上 GPU 計算能力的增長。如果 Nvidia 仍然需要更多帶寬,它也可以將 GDDR6X 用於較低層的 GPU。
更高級別的 Ada GPU 最終與 GDDR7 或三星的“GDDR6+”配對的可能性也很小,據報道,這將達到高達 27Gbps 的速度。然而,我們還沒有聽到關於其中任何一個的具體細節,在這個階段,Nvidia 將需要其合作夥伴來提高內存產量。更多的生產將不可避免地導致更多的泄漏,由於我們還沒有看到 GDDR7 或 GDDR6+ 生產的泄漏,我們假設它不會及時出現。
更有可能的是,Nvidia不需要大幅增加純內存帶寬,因爲它會重新設計架構,類似於我們看到 AMD 對 RDNA 2 所做的與原始 RDNA 架構相比。
五
ADA 希望利用 L2 緩存獲利
一種減少對更多原始內存帶寬需求的好方法是幾十年來已知和使用的方法——在芯片上增加更多緩存,您會獲得更多cache hits,每次cache hits意味着 GPU 不需要從 GDDR6/GDDR6X 內存中提取數據。AMD 的 Infinity Cache 讓 RDNA 2 芯片基本上可以用更少的原始帶寬做更多的事情,泄露的Nvidia Ada L2 緩存信息表明 Nvidia 將採取類似的方法。
AMD 在 Navi 21 GPU 上使用了高達 128MB 的大型 L3 緩存,Navi 22 爲 96MB,Navi 23 爲 32MB,Navi 24 僅爲 16MB。令人驚訝的是,即使是較小的 16MB 緩存也能爲內存子系統帶來奇跡。我們沒想到Radeon RX 6500 XT總的來說是一張很棒的卡,但它基本上可以跟上內存帶寬幾乎是兩倍的卡。
Ada 架構似乎將一個 8MB L2 緩存與每個 32 位內存控制器配對。這意味着具有 128 位內存接口的卡將獲得 32MB 的總二級緩存,而堆棧頂部的 384 位接口卡將擁有 96MB 的二級緩存。雖然在某些情況下這比 AMD 的 Infinity Cache 要小,但我們還不知道延遲或設計的其他方面。L2 緩存的延遲往往低於 L3 緩存,因此稍小的 L2 肯定可以跟上更大但速度較慢的 L3 緩存。
如果我們以 AMD 的 RX 6700 XT 爲例,它的計算能力比上一代 RX 5700 XT 高出約 35%。我們的GPU 基准測試層次結構中的性能同時在 1440p 超分辨率下高出約 32%,因此整體性能與計算幾乎一致。除此之外,6700 XT 擁有 192 位接口,帶寬僅爲 384 GB/s,比 RX 5700 XT 的 448 GB/s 低 14%。這意味着大型 Infinity Cache 使 AMD 的有效帶寬提高了 50%。
假設 Nvidia 可以通過 Ada 獲得類似的結果,那么通過 24Gbps 內存將帶寬增加 14%,然後將其與有效帶寬增加 50% 配對。這將使 AD102 的有效帶寬增加大約 71%,這與 GPU 計算的增加非常接近,因此一切都應該很好地發揮作用。
然而,關於緩存謠言的更多都是猜測。Nvidia 已經發布了有關 Hopper H100 的大量細節。它確實比上一代 GA100 具有更大的 L2 緩存大小,但它不是每個內存控制器 8MB。事實上,H100 上的總二級緩存爲 50MB,而 A100 的二級緩存爲 40MB。但 Hopper 也使用 HBM3 顯存,將用於海量數據集,這也是它擁有 80GB 顯存的原因。任何不能放入 40MB 的東西也不太可能放入 50MB 甚至 150MB。消費者工作負載,尤其是遊戲,更有可能從更大的緩存中受益。Nvidia 可能會在這裏追隨 AMD 的腳步,或者謠言最終可能完全錯誤。
六
ADA的功耗
Ada 架構的一個元素肯定會引起一兩個人的注意,那就是功耗。Igor's Lab 的 Igor 是第一個將 Ada 的 600W TBP(典型電路板功率)傳聞記錄在案的人,我們第一次聽到就笑了。“不可能,”我們想。多年來,Nvidia 顯卡的最高功率接近 250W,而 Ampere 在 RTX 3090(以及後來的 RTX 3080 Ti)上躍升至 350W 已經感覺有些過分了。隨後英偉達公布了 Hopper H100 規格並發布了 RTX 3090 Ti,突然覺得 600W 的可能性不大。
這一切都可以追溯到 Dennard scaling的終結,以及摩爾定律的死亡。簡而言之,Dennard scaling(也稱爲 MOSFET scaling)觀察到,每一代,尺寸都可以縮小約 30%。這將總面積減少了 50%(長度和寬度都按比例縮放),電壓下降了類似的 30%,電路延遲也將減少 30%。此外,頻率將增加約 40%,總功耗將減少 50%。
如果這一切聽起來好得令人難以置信,那是因爲 Dennard scaling實際上在 2007 年左右停止發生。就像摩爾定律一樣,它並沒有完全失效,但收益變得不那么明顯了。集成電路中的時鐘速度僅從 2004 年 Pentium 4 Extreme Edition 的最高約 3.7GHz 增加到如今 Core i9-12900KS 的最高 5.5GHz。這仍然幾乎增加了 50% 的頻率,但它已經超過了六代(或更多,取決於您要如何計算)的流程節點改進。換句話說,如果 Dennard scaling沒有死,現代 CPU 的時鐘頻率將高達 28GHz。
死亡的不僅僅是頻率縮放,還有功率和電壓縮放。如今,新的工藝節點還可以提高晶體管密度,不過需要平衡電壓和頻率。如果您想要一個速度快兩倍的芯片,您可能需要使用幾乎兩倍的功率。或者,您可以構建更高效的芯片,但不會更快。Nvidia 似乎正在尋求 Ada 的第一個選項。
使用像 GA102 這樣的 350W Ampere GPU,將性能提升 70-80%。因此,這樣做意味着要多使用 70-80% 的功率。350W 然後變成 595–630W。Nvidia 可能會比线性擴展稍微好一點,並且 600W 很可能是參考卡上的最大功率使用,但我們已經聽說一些下一代第三方超頻卡可能包括雙 16 針電源連接器。
七
ADA會最終成爲RTX 40-SERIES嗎?
下一代Nvidia GPU將被稱爲什么仍然存在問題。我們建議 RTX 40 系列,堅持過去幾代人建立的模式,但 Nvidia 總能改變一些事情。改變的一個潛在原因是:中國人不喜歡“四”,這在粵語和普通話中也意味着死亡。
這是一個足夠好的理由來改變事情嗎?也許不是。當然,這些年來我們已經看到很多顯卡和其他型號爲“4”的 PC 產品。英偉達在其 RTX 品牌上投入了大量資金,雖然如果每個人都准確地猜出下一系列 GPU 的名稱可能不會那么令人興奮,但銷量才是最重要的。
無論最終調用 Ada 顯卡,都不會改變它們的性能或功能。我們中的大多數人有理由相信 Nvidia 將使用 RTX 40 系列名稱,但如果 Nvidia 做出改變,這並不是世界末日。
簡短的答案,也是真正的答案是,它們的成本將與 Nvidia 可以擺脫的收費一樣多。Nvidia 推出 Ampere 時採用了一套財務模型,但事實證明,這些模型在 Covid-19 大流行時代是完全錯誤的。現實世界的價格飆升,黃牛從中牟取暴利,而那是在加密貨幣礦工开始支付官方推薦價格的兩到三倍之前。即使是現在,我們仍然看到 30% 或更多的加價。好消息是GPU 價格正在下降。
Ada 和 RTX 40 系列的 GPU 價格很可能會上漲。然而,假設的大型 L2 緩存和內存帶寬的相對有限增加應該導致 Ada 僅在 Ampere 的採礦性能方面提供適度的提升,就像 AMD 的 RDNA 2 卡僅比 RDNA 模型快一點一樣。這意味着,即使在 Ada 到來之前採礦盈利能力“恢復”,單靠採礦幾乎肯定無法維持我們從 2020 年底到 2022 年初看到的大幅上漲的價格。
正如我們將在下一節中討論的那樣,Nvidia 也沒有理由立即將其所有 GPU 生產從 Ampere 轉移到 Ada。我們可能會看到 RTX 30 系列 GPU 仍在生產相當長一段時間,特別是因爲沒有其他 GPU 或 CPU 競爭三星 Foundry 的 8N 制造。Nvidia 首先推出高端 Ada 卡,利用其可以從台積電獲得的所有可用容量,並在必要時降低現有 RTX 30 卡的價格以填補任何漏洞,從而獲得更多收益。
我們多次提到了 9 月推出 Ada 和 RTX 40 系列 GPU 的時間表,但重要的是要記住,第一批 Ada 卡只是冰山一角。英偉達於 2020 年 9 月推出了 RTX 3080 和 RTX 3090,一個月後 RTX 3070 到貨,再過一個月後 RTX 3060 Ti 到貨。RTX 3060 直到 2021 年 2 月下旬才問世,然後 Nvidia 在 2021 年 6 月用 RTX 3080 Ti 和 RTX 3070 Ti 更新了該系列。預算友好的 RTX 3050 直到 2022 年 1 月才到貨,最後是 RTX 3090 Ti 剛剛於 2022 年 3 月下旬推出。
我們預計 Ada 卡也將分階段推出,從最快的型號开始逐步進入高端和主流產品,以預算爲導向的 AD106 和 AD107 最早可能要到 2023 年才會推出。正如我們剛剛提到的,RTX 3050 僅在 1 月下旬推出,因此至少再過一年甚至更長的時間都不會更換。再說一次,我們仍然需要真正的預算產品來接管 GTX 1660 和 GTX 1650 系列。我們能否以低於 200 美元的價格獲得新的 GTX 系列或真正的預算 RTX 卡?這是可能的,但不要指望它,因爲 Nvidia 似乎滿足於讓 AMD 和英特爾在 200 美元以下的範圍內與之抗衡。
在首次發布大約一年後,不可避免地會更新 Ada 產品。在這個階段,任何人都猜測這些最終是“Ti”模型還是“Super”模型或其他什么,但你幾乎可以在你的日歷上標記它。
八
GPU世界的更多競爭
幾十年來,英偉達一直是顯卡領域的主導者。它控制着整個 GPU 市場的大約 80% 到 90%,並且在很大程度上能夠決定光线追蹤和 DLSS 等新技術的創建和採用。然而,隨着人工智能和計算對科學研究和其他計算工作負載的重要性不斷增加,以及它們對類似 GPU 的處理器的依賴,許多其他公司都在尋求進入該行業,其中最主要的是英特爾。
自 90 年代後期以來,英特爾就沒有在專用顯卡上做出過適當的嘗試,除非你算上流產的 Larrabee。這一次,Intel Arc 似乎是玩真的——或者至少是進了門。看起來英特爾更多地關注媒體功能,而在 Arc 的遊戲或一般計算性能方面,陪審團仍然沒有定論。據我們所知,頂級消費模型最多只能在 18 TFLOPS 範圍內。看看我們在頂部的桌子,看起來它只會與 AD106 競爭。
但 Arc Alchemist 只是英特爾計劃的常規 GPU 架構中的第一個。Battlemage 可以輕松地將 Alchemist 的能力翻倍,如果英特爾能夠早日實現這一目標,它可能會开始蠶食 Nvidia 的市場份額,尤其是在遊戲筆記本電腦領域。
AMD 也不會停滯不前,它已經多次表示它“有望”在今年年底之前推出其 RDNA 3 架構。我們預計 AMD 將轉向台積電的 N5 節點,這意味着它可能會直接與 Nvidia 競爭晶圓,並且兩者都必須做出類似的設計決策。到目前爲止,AMD 一直避免將任何形式的深度學習硬件放入其消費級 GPU(與其 MI200 系列不同),但由於 Arc 還包括 Xe Matrix 內核,它可能需要重新考慮這種方法。
毫無疑問,Nvidia 目前提供的光线追蹤性能遠遠優於 AMD 的 RX 6000 系列卡,但 AMD 對光线追蹤硬件或遊戲中對 RT 效果的需求幾乎沒有直言不諱。就英特爾而言,它的 RT 性能似乎比 AMD 還要低。但只要大多數遊戲在沒有 RT 效果的情況下繼續運行得更快並且看起來不錯,那么說服人們升級顯卡就是一場艱苦的战鬥。
長達兩年的 GPU 幹旱和價格過高的顯卡已經過去了。2022 年將成爲自 2020 年以來 GPU 領域的第一次真正激動人心的時刻。希望這一輪能夠看到更好的可用性和定價。它幾乎不會比我們過去 18 個月看到的情況更糟。
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:英偉達最強芯片曝光:18176個內核、48GB內存、24Gbps速度和800WTBP
地址:https://www.breakthing.com/post/10346.html