




來源:內容由半導體行業觀察編譯自servethehome ,謝謝。
近日,NVIDIA 對 HC34(“Hot Chips 34”) 下周的重大信息進行了一定的披露,我們想專注於 NVIDIA Grace Arm CPU 的詳細信息進行解析。這些也許是最有趣的。
新 NVIDIA Grace Arm CPU 詳細信息
有許多關於 NVIDIA Grace CPU 的新披露。我們現在得到了一個基本的平面圖:
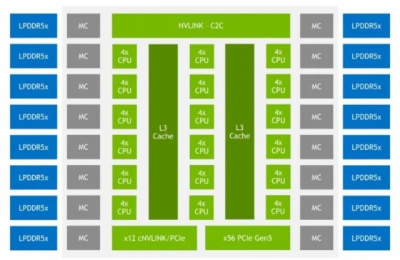
NVIDIA Grace IO HC34 外殼
NVIDIA 表示,新的 Grace CPU 將基於 Arm v9.0,並將具有 SVE2、虛擬化/嵌套虛擬化、S-EL2 支持(安全 EL2)、RAS v1.1 通用中斷控制器(GIC)v4.1 等功能、內存分區和監控 (MPAM)、系統內存管理單元 (SMMU) v3.1 等。
NVIDIA 還分享說,它預計新的 72 核 CPU 使用 GCC 時,每個完整的 72 核 Grace CPU 的 SPEC CPU2017 整數速率得分約爲 370。在某些情況下,64 核 AMD 芯片的官方分數將在 390-450 範圍內(例如AMD EPYC 7773X。)在一個模塊上有兩個 Grace CPU,我們得到的Grace Superchip可以有效地將這些數字翻倍。
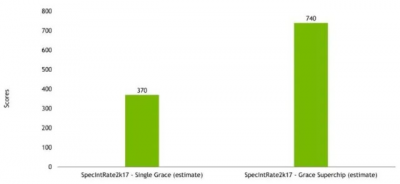
NVIDIA Grace 預計性能 HC34
就Grace而言,這實際上只是等式的一部分。Grace 並非專爲全面的 CPU 性能而設計。相反,它專爲內存帶寬、電源效率和與公司 GPU 產品的一致性而設計。可以在上面的 Grace 圖中看到 16x 內存通道。Grace 的基本目標是使用 LPDDR5x 獲得 HPC/AI 可用容量。那么英偉達會使用很多通道來獲得很多帶寬。這裏有幾個重要的注意事項,即 AMD 將有一個帶有 Genoa 的 12 通道 DDR5 控制器,因此總容量和帶寬應該成比例地高於下面的 8 通道。熱那亞部分將以功耗換取可維護性和更大容量。HBM2e 非常昂貴,但它以容量爲代價提供了大量帶寬。

NVIDIA Grace 帶寬 HBM2e DDR5 LPDDR5x HC34
以上似乎非常關注 Sapphire Rapids HBM 討論四個站點 HBM 和 8 通道 DDR5。我們在 Intel Vision 2022 上通過 Intel Sapphire Rapids HBM展示了這一點。

Sapphire Rapids HBM 和 Patrick 2
最大的好處是內存帶寬。以下是 Grace CPU(單 CPU,不是 Grace Superchip)的估計內存帶寬結果:
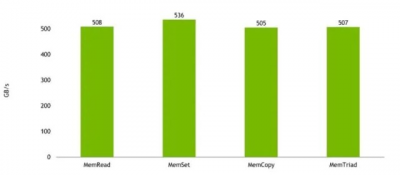
HC34:NVIDIA Grace 預估內存性能
也許對 NVIDIA 更大的吸引力是 Grace CPU 能夠使用 NVLink 和 NVSwitch 結構在 CPU 和 GPU 之間建立連貫的鏈接。NVIDIA 基本上是在構建一種高性能結構,業內其他公司將在某個時候與之匹敵。英偉達現在才這樣做。使用 NVLink-C2C,該公司獲得高達 900GB/s 的速度,與 PCIe Gen5 相比,“能源效率提高了 5 倍”。其中很大一部分是 PCIe Gen5 還設計爲跨越更長的距離,而不僅僅是一個封裝接口。
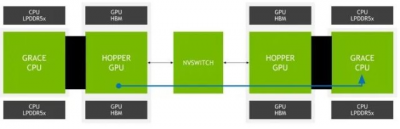
NVIDIA Grace Hopper NVSwitch
NVIDIA 的計劃是使用這些復合體,在 Grace 超級芯片上只有 LPDDR5x 的封裝上擁有高達 1TB/s 的帶寬,或者通過 Grace Hopper 解決方案獲得更高的帶寬。該公司僅展示了一個 Grace to Hopper 互連,估計組合帶寬將超過 500GB/s。雖然使用 Grace CPU 更大的 512GB 內存佔用是有代價的,但 NVIDIA 力求將影響降到最低。
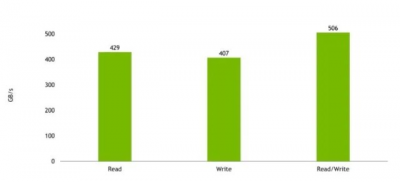
NVIDIA Grace To Hopper 帶寬
NVIDIA 還展示了該公司計劃如何擴展設計的更多信息。使用 NVIDIA Scalable Coherecy Fabric,NVIDIA 希望獲得高達 4 插槽的一致性和 72 個內核/117MB 的三級緩存(1.625MB/內核。)
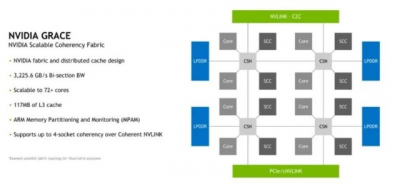
NVIDIA 可擴展一致性結構
該公司還表示,有多達 68 條 PCIe 連接通道。我們可以看到有 56 個 PCIe Gen5 通道加上另外 12 個可以是 PCIe 或 cNVLINK 的通道。
NVIDIA Grace IO 外殼
總的來說,這是一個非常令人興奮的設計。
最後的話
NVIDIA 構建自己的 CPU 確實有兩個原因。首先,NVIDIA 想要在大型系統中爲公司的 GPU 提供更高效的協處理器。NVIDIA 擁有與 Apple 類似的硬件/軟件堆棧,因此這是成爲真正的全堆棧供應商的嘗試。NVIDIA 不需要 Intel/AMD 的新 AI 加速器,它有自己的。同樣,它可以構建具有正確性能屬性的芯片來增強 GPU,而不是復制其他部分。
第二個原因現在更明顯了。英偉達需要將自己與英特爾和 AMD 脫鉤。兩者都在 HPC 和 AI 方面與 NVIDIA 競爭。同時,Hopper H100 正在等待 Sapphire Rapids 發射,然後 DGX H100 才能發射。因此,我們預計 Hopper 將在 2023 年第一季度中後期首次亮相。鑑於芯片存在,(見下文)NVIDIA 需要一個 CPU 解決方案,以便它可以銷售其 GPU。

Patrick 與 NVIDIA H100 在 NVIDIA 總部, 2022 年 4 月
*免責聲明:本文由作者原創。文章內容系作者個人觀點,半導體行業觀察轉載僅爲了傳達一種不同的觀點,不代表半導體行業觀察對該觀點贊同或支持,如果有任何異議,歡迎聯系半導體行業觀察。
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:英偉達GraceCPU最新披露
地址:https://www.breakthing.com/post/15163.html