




來源:內容由半導體行業觀察綜合自tomshardware等,謝謝。
英偉達GTC秋季大會近日盛大开幕。會上,英偉達CEO黃仁勳不但帶來了最新一代的RTX 4090以及 “Ada Lovelace”架構。同時,他還修正了公司的汽車SoC路线圖,拋棄 Atlan,計劃推出具備2000 TFLOPS性能的Thor。在會上,黃仁勳還披露,H100已經全面投產。
現在,我們來看一下這次大會上的重點。
GeForce RTX 40 系列顯卡:速度提升高達4倍
據報道,英偉達RTX 4090 將有 128 個 SM 和 2,520 MHz 升壓時鐘(boost clock),再加上 24GB GDDR6X 內存,運行速度爲 21 Gbps,具有 384 位接口。內存配置與RTX 3090 Ti相比基本沒有變化,這從表面上看基本是對的。然而,就像 AMD 對 RDNA 2 的 Infinity Cache 所做的那樣,Nvidia 顯然會在 AD102 中打包 96MB 的 L2 緩存,而 GA102 中只有 6MB 的 L2 緩存——但這還沒有得到官方證實。
與 Ampere 相比,新產品的核心數量增加了 50% 以上,最多有 128 個 SM,而不是最多只有 84 個 SM — 未來仍有進一步提升到140-144 個 SM 型號產品的空間,也許是新的Titan RTX,或者至少是未來的 RTX 4090 Ti。僅核心數量就可以大幅提升性能,但 Nvidia 還調整了 Ada 以達到更高的時鐘頻率,這再次類似於 AMD 對 RDNA 2 所做的,結果是已發布型號上預期的 2.5-2.6 GHz 提升時鐘。這比 RTX 3090 的 1,695 MHz 升壓時鐘高出近 50%,比 RTX 3090 Ti 的 1,860 MHz 高出 35%。黃仁勳透露,Nvidia 在其實驗室中通過超頻達到了超過 3.0 GHz 的時鐘速度。(您好,800W 定制 RTX 4090 卡!)
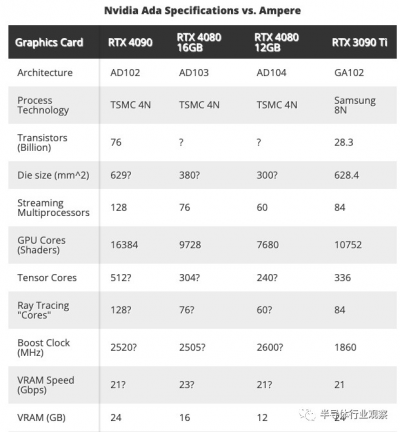
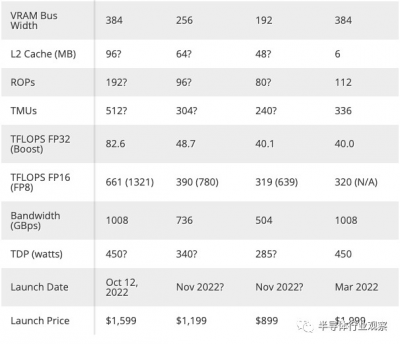
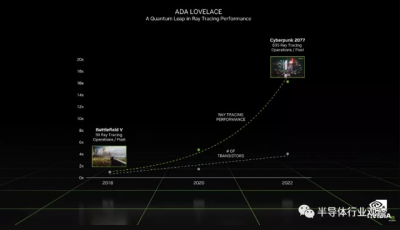
結合起來,GPU 着色器計數和時鐘速度產生了理論上的最大性能數據。RTX 3090 的額定值爲 35.6 teraflops,RTX 3090 Ti 將其提升至 40 teraflops,而現在 RTX 4090 將指針推高至 82.6 teraflops——換句話說,計算量增加了一倍多。雖然僅 teraflops 可能是一個毫無意義的數字,但它在類似的架構中仍然有用,而且我們正在研究自 GeForce 品牌首次出現以來我們從 Nvidia 看到的最大的代際性能飛躍。
Nvidia 尚未說明各種卡中具體使用了哪些 GPU,盡管之前的傳言稱我們正在研究三個獨立的芯片:AD102、AD103 和 AD104。再次考慮到核心數量的差異,這似乎仍然很可能,盡管 4080 12GB 可能會使用收獲的 AD103 芯片——如果不是現在,那么在未來的某個時候。
當然,更大的問題將是現實世界的收益,而內存帶寬缺乏實質性收益確實會引發一些問題。但是,請記住,當 AMD 基本上在其 RDNA 設計上添加了一堆 L3 緩存然後提高時鐘速度時,像 RX 6600 XT 這樣的卡能夠保持領先於上一代 RX 5700 XT,後者的內存幾乎是其兩倍帶寬 — Navi 23 上只有 32MB。96MB 的二級緩存應該使 Nvidia 緩存命中率達到 50% 或更高,這意味着有效內存帶寬增加了一倍。
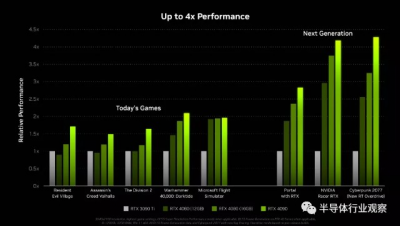
理論性能看起來異常強大,但其余部分呢?Nvidia 提供了上述基准測試結果,將三款新 GPU 與現有 RTX 3090 Ti 進行了比較。您可以看到,在傳統遊戲中,在左側,RTX 4080 12GB 可能會比 3090 Ti 稍慢,但要快很多。考慮到其他細節,我們懷疑某些測試是在啓用 DLSS 3 的情況下完成的,這僅在 RTX 40 系列卡上可用,從而使它們具有相當大的性能優勢。
在右邊,情況確實如此。RacerX、Portal RTX 和 Cyberpunk 2077 “RT Overdrive”都將光线追蹤效果提升到了新的極致。我們沒有基准 fps 數據,但在某些情況下,RTX 4080 12GB 的速度是 3090 Ti 的兩倍多,而 RTX 4090 的速度則高達四倍。是否仍允許 RTX 3090 Ti 使用 DLSS 2?
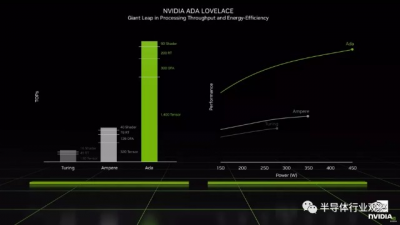
讓我們簡要介紹一下架構更新,以了解更多背景信息。據介紹,英偉達全新的Ada Lovelace產品使用台積電4n工藝打造,擁有760億的晶體管。

核心數量和時鐘速度有所提高,但更重要的是,架構更新可以進一步提升性能。在 GPU 着色器上,Nvidia 表示 Ada 內核的功率效率高達兩倍。着色器還支持稱爲 SER 的新功能,即着色器執行重新排序,它似乎主要有助於提高光线追蹤性能,但在傳統渲染模式中也可能有用。
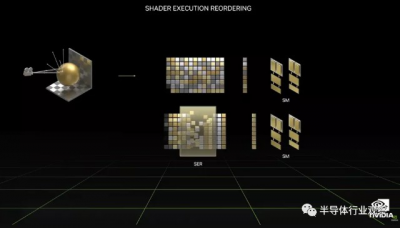
轉向 RT 核心本身,Nvidia 增加了更多的射线/三角形相交硬件,從而使該區域的量提高了兩倍。新的不透明度微圖引擎還可以加快透明紋理的光线追蹤。同樣,微網格引擎顯然可以在沒有 BVH 構建和存儲成本的情況下添加幾何“豐富度”——這意味着 BVH 的三角形更少,但最終渲染的三角形更多。Nvidia 表示,第三代 RT 內核生成 BVH 結構的速度比第二代內核快 10 倍,同時使用的內存減少了 20 倍,即 VRAM 需求的 5%。

最後,通過 Hopper 對 FP8 數據類型的支持升級了 Tensor 核心。假設工作負載可以降低精度,這有效地使計算量翻了一番。請注意,每個 SM 的 Tensor 核心數量似乎沒有變化,FP16 操作中每個 Tensor 核心的量保持不變。但是新的 Tensor 核心顯然是 DLSS 3 的要求。
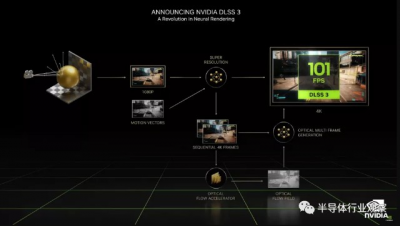
雖然架構更新很棒,但 Nvidia 也一直在努力進行軟件更新。DLSS 3 現已正式發布(在新標籤中打开),在主題演講期間展示的幾款遊戲中都支持它,並且可能還會有更多遊戲。Nvidia 在《賽博朋克 2077》中使用 DLSS 3 與 DLSSS 2 相比,性能提升了 63%,大概在最終輸出上具有相似的視覺保真度。
顯然,我們無法測試 DLSS 3,所以我們必須拭目以待,但 DLSS 2 已經爲整體升級質量設定了很高的標准。DLSS 3 將採用現有的輸入——幀數據、運動矢量、深度緩衝區和前一幀——並添加一個新的光流加速器。
提供的信息表明,DLSS 3 和 OFA 可以通過查看先前的數據從單個源圖像中生成多個幀。所以理論上,它可能會使幀速率翻倍,並且在運動中,它可能有助於使遊戲看起來更流暢,盡管我們確實想知道單個幀比較如何站起來。在很多方面,這幾乎聽起來像是來自 VR 的異步空間扭曲 (ASW),它獲得了一些 AI 增強功能並與升級一起應用,如果你想提高幀率,這實際上聽起來很聰明。
然而,最大的問題之一是 DLSS 3 僅適用於 RTX 40 系列(及更高版本)GPU。如果遊戲开發者想要迎合更廣泛的遊戲玩家,他們基本上需要同時包含 DLSS 2 和 DLSS 3 支持,此時他們不妨也添加 FSR 2.0 和 XeSS 支持。這可能不會發生,但由於 Ampere 和更早的 RTX GPU 沒有新的光流加速器,也許有一種備用模式,它們只需使用 DLSS 2.x 算法運行。
值得注意的是,到目前爲止,所有版本的 DLSS 都可以在每張 RTX 卡上運行,從低端的RTX 2060和RTX 3050一直到RTX 3090 Ti. 然而,這些 GPU 上潛在的 Tensor 核心計算存在巨大差異,RTX 2060 僅提供約 52 teraflops 的 FP16,而 3090 Ti(具有稀疏性)則高達 640 teraflops。現在,借助 RTX 40 系列上的 FP8,即使是假設的 20 SM RTX 4050 也將提供大約 200 teraflops 的計算,而 RTX 4090 的量高達 1.4 petaflops。

英偉達放棄 Atlan,推出具備2000 TFLOPS性能的Thor
作爲其秋季 GTC 2022 活動的一部分,NVIDIA 今天發布的大量公告中,該公司正在對其 DRIVE 汽車 SoC 計劃進行令人驚訝的更行,且立即生效。NVIDIA表示將取消Atlan,這是他們計劃用於 2025 年汽車的後 Orin SoC。取而代之的是,NVIDIA 宣布推出 Thor,這是一款功能更強大的 SoC,將於 2025 年推出。
NVIDIA 的 Atlan SoC 於 2021 年春季 GTC 首次亮相,NVIDIA 宣布將其作爲下一代汽車 SoC,以接替(現在的)Orin SoC。在宣布時,Atlan 計劃成爲一款高性能 SoC,提供 1000 TOPS 的 INT8 推理性能,採用下一代(Lovelace)GPU 設計和下一代 Grace CPU 設計。該芯片甚至集成了 BlueField DPU 作爲網絡和安全處理器,旨在提供一個可以處理自動駕駛汽車所需的所有計算功能的 SoC。

但無論 Atlan本應是什么,現在都已不復存在。截至 NVIDIA 新的 DRIVE SoC 路线圖,Atlan 已被廢棄。取而代之的是一個新的 SoC——Thor,它比Atlan 更強大。
與 2021 年的 Atlan 公告一樣,NVIDIA 僅在發布之前發布了有關 Thor 的少數細節。高級細節包括,沒有命名特定的 NVIDIA CPU 和 GPU 架構,但 SoC 正在利用 Grace CPU、Ampere GPU 架構和 Lovelace GPU 架構首次引入的功能。與此同時,NVIDIA 關於此事的博客文章確實更進一步,指出 SoC 使用了 Arm 迄今爲止祕密的 Poseidon CPU 內核的汽車增強 (AE) 版本。我們對Poseidon 知之甚少,它是 Arm 正在开發的下一代高性能 CPU 內核,將用於其下一代 Neoverse V 系列平台,取代剛剛發布的Neoverse V2。
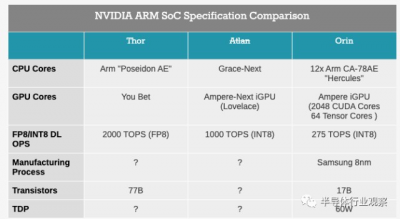
從性能的角度來看,Thor 計劃使用新標准化的 FP8 數據格式提供 2 PFLOPS (2000 TFLOPS) 的浮點推理性能。盡管與 Atlan 的 1000 TFLOPS INT8 數字相比,這不是一個公平的比較,但它仍然代表了 8 位精度計算量的兩倍。SoC 的張量核心還將採用 NVIDIA 的 transformer engines,使 SoC 能夠進一步加速transformer networks的處理。
值得注意的是,整合所有這些性能將使 Thor 成爲一個非常龐大的芯片。雖然 NVIDIA 沒有宣布工藝節點,但他們已經表示它將使用 770 億個晶體管,這比他們的新旗艦 GH100 GPU 少了 30 億個晶體管。NVIDIA 的性能聲明並未表明是否使用了矩陣稀疏性,但即使是這樣,Thor 的 FP8 性能也將是 NVIDIA 旗艦 GPU 的一半。所有這些都突顯了 NVIDIA 對計劃中的 SoC 的極端性能目標。
雖然 NVIDIA 的芯片模型在 AGX 板上以單芯片配置顯示它,但今天的公告還明確提到了 NVLink 芯片到芯片 (NVLink-C2C) 芯片互連技術。這是一個奇怪的提及,因爲 NVIDIA 的關鍵藝術並沒有顯示 Thor 是基於chiplet的。這可能意味着 NVIDIA 將轉而使用 NVLink-C2C 來實現更強大的多芯片 DRIVE AGX 板(ala Pegasus),或者很可能 Thor 是基於chiplet的設計,而 NVIDIA 故意將其通用化藝術。
除此之外,NVIDIA 沒有提供有關 SoC 的任何進一步技術細節。因此,有關使用的內存類型、GPU 架構和其他功能塊的詳細信息仍有待觀察。
在這一點上,NVIDIA 也沒有詳細說明爲什么他們取消了 Atlan 來代替 Thor。Thor 無疑是一個更強大的設計,並且似乎包含了一些在 Atlan 上找不到(或至少從未公开過)的新功能。這是否意味着 NVIDIA 正在以某種方式引入本應是後 Atlan 芯片的芯片,或者他們是否因爲客戶需要更好的自動駕駛汽車 AI 推理性能而放棄了 Atlan,還有待觀察。
拋开硬件升級不談,很明顯,NVIDIA 正在爲與 Atlan 相同的細分市場設計 Thor。也就是說,它是一種高性能的單芯片設計,用於處理自動駕駛汽車的所有計算需求,從信息娛樂系統和傳感器融合到實際的自動駕駛算法本身。與 Atlan 一樣,其目標是用一台可以完成所有工作的計算機取代目前汽車內的獨立計算機,利用具有廣泛隔離(包括 MIG)的功能安全設計技術來防止單獨的任務相互幹擾。
然而,也許最令人驚訝的是,SoC 的這種變化預計不會影響 NVIDIA 的 SoC 交付日期。英偉達表示,他們將在 2025 年爲汽車廠商提供Thor,這與亞特蘭的計劃到達時間相同。因此,雖然魔鬼在細節中,但在高水平上,英偉達的目標是提供接近相同的Thor時間,因爲他們會交付Atlan 。不過值得注意的是,雖然 NVIDIA 此前曾宣布 Atlan 將在 2023 年出樣,但尚未發布關於 Thor 的此類公告。因此,Thor 的送樣日期可能最終會晚於 Atlan 的送樣日期。
H100已經全面投產
在企業方面,英偉達今天會上期待最久的更新之一是 NVIDIA 的 H100 “Hopper”加速器的出貨狀態。因爲根據之前說法,該加速器最初預計在今年第三季度登陸。。據 NVIDIA 稱,該加速器已全面投入生產,首批系統將於 10 月從 OEM 處發貨。
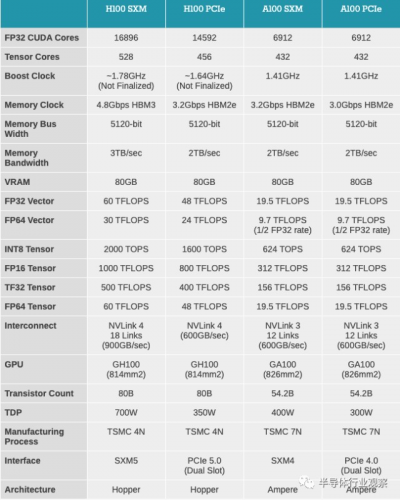
H100在 3 月份的 NVIDIA 年度春季 GTC 活動中首次亮相,是 NVIDIA面向服務器、超大規模計算機和類似市場的下一代高性能加速器。H100 基於 Hopper 架構,基於台積電的 4nm“4N”工藝,是 NVIDIA 非常成功的 A100 加速器的後續產品。除其他變化外,該公司最新的加速器實現了 HBM3 內存,在其張量內核中支持transformer模型,支持動態編程,具有更強大隔離的多實例 GPU 的更新版本,以及兩者的計算量都大大提高矢量和張量數據類型。基於 NVIDIA 的 800 億晶體管 GH100 GPU,H100 加速器也在功耗方面突破極限,最大 TDP 爲 700 瓦。
鑑於 NVIDIA 的春季 GTC 活動與他們這一代的制造窗口不完全一致,今年早些時候的 H100 公告稱 NVIDIA 將在第三季度出貨第一批 H100 系統。但是,NVIDIA 今天概述的更新交付目標意味着第三季度的日期已經推遲。好消息是,正如 NVIDIA 所說,H100 正在“全面生產”。壞消息是,生產和集成似乎並沒有按時开始。目前,該公司預計第一批生產系統要到 10 月,也就是第四季度开始時才能到達客戶手中。
更進一步,系統和產品推出的順序基本上與 NVIDIA 的慣常策略相反。NVIDIA 的合作夥伴並沒有首先從基於其最高性能 SXM 外形部件的系統开始,而是從性能較低的 PCIe 卡开始。也就是說,10 月份出貨的第一批系統將使用 PCIe 卡,而 NVIDIA 的合作夥伴將在今年晚些時候推出集成了更快的 SXM 卡和他們的 HGX 載板的系統。
值得一提的是,NVIDIA 的旗艦 DGX 系統通常是最早發布的系統之一,現在將成爲最後一批。NVIDIA 今天开始接受 DGX H100 系統的預訂,預計在 2023 年第一季度(即從現在起的 4 到 7 個月)交付。這對 NVIDIA 的服務器合作夥伴來說是個好消息,他們在過去幾代人中不得不等待 NVIDIA,但這也意味着 H100 作爲產品在开始在系統中出貨時將無法發揮最大的作用下個月。
在與媒體的預先簡報中,英偉達沒有詳細解釋爲什么 H100 最終會延遲。盡管在高層發言,但公司代表確實表示延遲不是出於組件原因。同時,該公司引用了 PCIe 卡相對簡單的原因,因爲 PCIe 系統首先出貨。這些在通用 PCIe 基礎架構中主要是即插即用的,而 H100 HGX/SXM 系統更復雜,需要更長的時間才能完成。
兩種外形尺寸之間也存在一些顯著的功能差異。SXM 版本是唯一使用 HBM3 內存的版本(PCIe 使用 HBM2e),而 PCIe 版本需要更少的工作 SM(114 對 132)。因此,NVIDIA 有一些回旋余地來隱藏早期產量問題,如果這確實是一個因素的話。
讓 NVIDIA 更復雜的是,DGX H100 系統基於英特爾反復延遲的第 4代Xeon 可擴展處理器 ( Sapphire Rapids ),目前還沒有完全確定的發布數據。不太樂觀的預測是它在第一季度推出,這與 NVIDIA 自己的發布日期一致——盡管這很可能只是巧合。無論哪種方式,Sapphire Rapids 缺乏普遍可用性都沒有給 NVIDIA 帶來任何好處。
最終,由於 NVIDIA 無法在明年之前推出 DGX,它將成爲 NVIDIA 的服務器合作夥伴,率先推出 HGX 系統——可能使用當前一代主機,或者如果及時准備好,可能使用 AMD 的 Genoa 平台。在計劃推出 H100 系統的公司中,包括 Supermicro、戴爾、HPE、技嘉、富士通、思科和 Atos。
同時,對於急於在購买任何硬件之前試用 H100 的客戶,H100 現在可在 NVIDIA 的 LaunchPad 服務中使用。
最後,當我們討論 H100 的主題時,NVIDIA 還利用本周的 GTC 宣布更新其 NVIDIA AI Enterprise 軟件堆棧的許可。H100 現在附帶一個 5 年的軟件許可證,這是值得注意的,因爲 5 年訂閱通常是每個 CPU 插槽 8000 美元。
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:不止RTX4090,英偉達超強汽車芯片來襲
地址:https://www.breakthing.com/post/19637.html