




英特爾最近發布的一項專利可能是其未來圖形加速器設計的基石——它利用了多芯片模塊 (MCM:Multi-Chip Module) 方法。英特爾描述了一系列協同工作以提供單幀的圖形處理器。英特爾的設計指向工作負載的層次結構:主圖形處理器協調整個工作負載。該公司將 MCM 作爲一個整體方法構建爲一個必要的步驟,以引導芯片設計人員遠離在不斷追求性能的過程中不斷增加裸片尺寸所帶來的可制造性、可擴展性和供電問題。
根據英特爾的專利,多個圖形繪制調用(指令)傳送到“多個”圖形處理器。然後,第一圖形處理器實質上運行整個場景的初始繪制通道。此時,圖形處理器只是創建可見性(和障礙)數據;它決定渲染什么,這是在現代圖形處理器上進行的高速操作。然後,在第一次通過期間生成的一些圖塊會轉到其他可用的圖形處理器。根據該初始可見性傳遞,他們將負責准確地渲染與其tiles相對應的場景,這表明每個tile中的圖元或顯示沒有要渲染的地方。
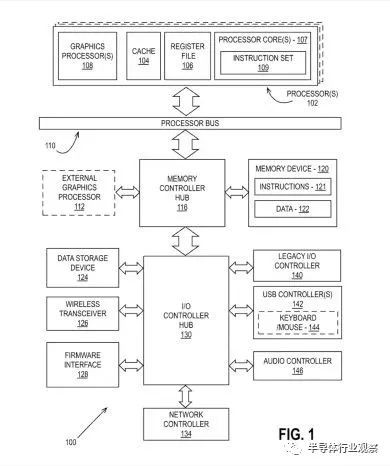
一種集成了英特爾專利中描述的圖形處理器之一的計算機系統。請注意處理器和內核中的復數。(圖片來源:英特爾)
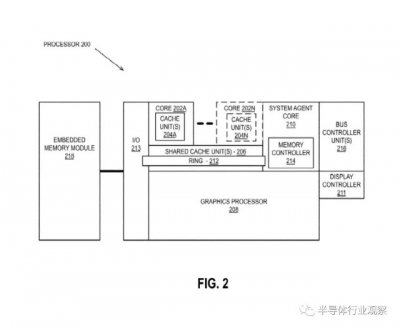
英特爾“細節”之一的詳細示意圖(圖片來源:英特爾)
因此,英特爾似乎正在考慮將基於圖塊的棋盤渲染(當今 GPU 中使用的一項功能)與分布式頂點位置計算(在初始幀傳遞之外)集成在一起。最後,當所有圖形處理器都渲染了他們的單幀拼圖(包括着色、照明和光线跟蹤)時,它們的貢獻被拼接起來,以在屏幕上呈現最終圖像。理想情況下,這個過程每秒會發生 60、120 甚至 500 次。英特爾對多芯片性能擴展的希望就這樣擺在我們面前。然後,英特爾使用 AMD 和 Nvidia 顯卡在 SLI 或 Crossfire 模式下工作的性能報告來說明經典多 GPU 配置的潛在性能提升。但是,當然,它總是低於真正的 MCM 設計。

基於圖塊的渲染,其中單個幀被分成多個圖塊。在英特爾的專利中,這些圖塊將經過第一次通過,指示哪些圖元可見以及在何處可見。這爲每個圖塊提供了多個圖形處理器必須在頂部渲染的框架,直到我們獲得 Destiny 2 幀。(圖片來源:英特爾)
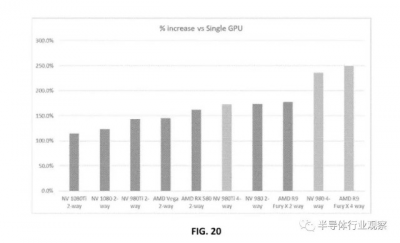
對多 GPU 配置的性能估計——英特爾沒有分享任何關於這項專利申請的內部結果,至少可以說這很有趣。(圖片來源:英特爾)
然而,英特爾的專利在架構層面的細節上是模糊的,並且涵蓋了盡可能多的領域——這在這個領域也是很常見的。例如,它允許設計甚至包括多個協同工作的圖形處理器或只是圖形處理器的一部分。該方法適用於“單處理器桌面系統、多處理器工作站系統、服務器系統”以及用於移動的片上系統設計 (SoC)。這些圖形處理器或實施例,正如 Intel 所稱的那樣,甚至被描述爲接受來自 RISC、CISC 或 VLIW 命令的指令。但英特爾似乎直接從 AMD 的劇本中吸取了教訓,解釋說他們的 MCM 設計的“中心”
隨着半導體微縮的速度放緩(並繼續放緩),公司必須找到在保持良好良率的同時擴大性能的方法。與此同時,他們必須在架構上進行創新,半導體制造工藝越來越復雜和奇特,所需的制造步驟越來越多,掩模數量越來越多,最終集成了極紫外光刻 (EUV) 應用。一段時間以來,我們一直在研究等式中的收益遞減部分:增加晶體管密度變得越來越難,而進一步增加裸片面積會降低晶圓產量。唯一的解決方案是將幾個較小的die配對在一起:擁有兩個正常工作的 400 平方毫米die比擁有一個完全工作的 800 平方毫米die更容易。
例如,自第一代以來,AMD 就憑借基於 MCM 的 Ryzen CPU 取得了巨大成功。這家公司仍然提供基於 MCM 的 GPU,但他們的下一代Navi 31 和 Navi 32可能採用該技術。我們也知道 Nvidia 也在積極探索 MCM 設計其未來的圖形產品,遵循其新的可組合封裝 GPU (COPA) 設計方法。這場競賽已經進行了很長時間,甚至在 AMD 推出 Zen 之前。第一家部署 MCM GPU 設計的公司應該比其競爭對手更具優勢,更高的產量有助於更高的利潤,或更低的市場定價。在可預見的未來,由於 AMD、英特爾和英偉達這三家公司都與台積電相同的制造節點籤約,每一個微小的優勢都可能產生潛在的巨大市場影響。
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:英特爾神祕專利曝光:透露GPU的未來設計方向
地址:https://www.breakthing.com/post/2790.html