




來源:內容由半導體行業觀察(ID:icbank)編譯自nextplatform,謝謝。
AMD在 2023 年國際消費電子展上推出了其下一代 Instinct MI300 加速器,我們有幸獲得了一些動手時間,並拍攝了幾張這款龐大芯片的特寫照片。毫無疑問,Instinct MI300 是一個改變遊戲規則的設計——這個數據中心 APU 混合了總共 13 個小芯片,其中許多是 3D 堆疊的,以創建一個具有 24 個 Zen 4 CPU 內核並融合了 CDNA 3 圖形的芯片引擎和 8 堆 HBM3。總體而言,該芯片擁有 1460 億個晶體管,是 AMD 投入生產的最大芯片。
關於這個芯片的更多信息,我們可以參考文章《AMD推出13個Chiplet,1460億晶體管的Instinct MI300 加速器》
與許多 HPC 和 AI 系統構建者一樣,我們迫不及待地想看看 AMD 的“Antares”Instinct MI300A 混合 CPU-GPU 片上系統在性能和價格方面的表現。
隨着 ISC 2023 超級計算大會在幾周後召开,勞倫斯利弗莫爾國家實驗室的首席技術官 Bronis de Supinski將在會上發表了關於未來“El Capitan”百億億級系統的演講,該系統將成爲Antares GPU 的 MI300A 變體的旗艦機器 ,它在我們的腦海中。
因此,爲了好玩,我們提取了 trust Excel 電子表格,並試圖估計作爲 El Capitan 系統核心的 MI300A GPU 的進給和速度可能是多少。是的,這可能是愚蠢的,考慮到 AMD 可能會在 ISC 2023 及以後更多地談論 MI300 系列 GPU,我們最終將准確地知道這個計算引擎是如何構建的。但是很多人一直在問我們,MI300 系列是否可以與 Nvidia“Hopper”H100 GPU 加速器競爭。也許更重要的是,與將Hopper H100 GPU和72 核“Grace”Arm CPU 緊密捆綁創建的 Grace-Hopper 混合 CPU-GPU 復合體競爭時。AMD的這個產品表現如何?它將與將在 El Capitan 部署的 MI300A 進行正面交鋒。
考慮到基於大型語言模型的生成 AI 應用程序的 AI 訓練激增,以及 AMD 希望通過其 GPU 在 AI 訓練中發揮更多作用,對 GPU 計算的強烈需求,我們認爲需求將超過 Nvidia供應,這意味着盡管 Nvidia AI 軟件堆棧相對於 AMD 具有巨大優勢,但後者的 GPU 將獲得一些 AI 供應勝利。前身“Aldebaran”GPU 已經爲 AMD 贏得了一些令人印象深刻的 HPC 設計勝利,特別是在橡樹嶺國家實驗室的“Frontier”百億億級系統中,其中四個雙芯片 GPU 連接到定制的“Trento”Epyc CPU 以創建一個更松散耦合的混合計算引擎。(還有其他的。
人們不會比在 1990 年代末和 2000 年代初添加 Web 基礎設施以使他們的應用程序現代化以在 Internet 上爲他們部署接口更有耐心地在今天的工作負載中添加生成 AI。這一次的不同之處在於,數據中心並沒有將自己轉變爲通用的 X86 計算基板,而是越來越成爲一個競爭和互補架構的生態系統,這些架構交織在一起以提供整體上最好的性價比跨更廣泛的工作負載。
我們對 MI300 系列還不是很了解,但在 1 月份,AMD 談了一些關於該設備的信息。我們有該設備的圖像,我們知道它的 AI 性能將是 Frontier 系統中使用的現有 MI250X GPU 加速器的 8 倍和 5 倍的每瓦 AI 性能。我們知道整個 MI300A 綜合體在其六個 GPU 和兩個 CPU 小芯片上有 1460 億個晶體管。我們認爲,晶體管數量的很大一部分是在四個 6 納米的tile中實現的,這些瓦片將 CPU 和 GPU 計算元素互連,並且在它們上面實現了 Infinity Cache。很難說這個緩存用了多少晶體管,但我們期待着找出答案。
順便說一下,我們認爲 MI300A 被稱爲 AMD 旗艦並行計算引擎的 APU 版本——意思是在一個封裝上結合了 CPU 和 GPU 內核。這意味着將有非 APU、僅 GPU 的 Antares GPU 版本,可能在這四個互連和緩存芯片之上最多有八個 GPU 小芯片,如下所示:

用今年早些時候 AMD 的語言來說非常精確,8 倍和 5 倍的數字是基於對 MI250X GPU 的測試和對 MI300A 復合體的 GPU 部分的建模性能。非常具體地說,這就是 AMD 所說的:“AMD 性能實驗室在 2022 年 6 月 4 日對當前規格進行的測量和/或對估計交付的 FP8 浮點性能的估計,其中結構稀疏性支持 AMD Instinct MI300 與 MI250X FP16( 306.4 基於峰值理論浮點性能的 80% 估計交付的 TFLOPS)。MI300 的表現基於初步估計和預期。最終表現可能會有所不同。”
因此,這是我們的表格,根據 AMD 到目前爲止所說的情況,估計 MI300A 的饋送和速度可能是什么樣子,與往常一樣,大量猜測以粗體紅色斜體顯示。
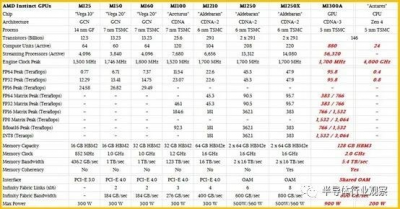
如果 MI250X 的 FP16 性能是 383 teraflops,那么這意味着 8X 倍數,包括降檔到 FP8 數據格式和處理,具有稀疏支持的 MI300A(提供 8X 倍數的另外 2 倍)可以推動 3,064 teraflops 峰值。如果 MI250X 的額定功率爲 560 瓦,那么 MI300A 的 GPU 部分必須以 900 瓦的功率運行才能產生 AMD 所說的每瓦性能提高 5 倍。
如果以上所有這些都是正確的,那么 MI300A CPU 復合體的性能必須是 MI250X 的 4 倍。如果您假設時鐘速度保持在 1.7 GHz,那么這意味着 MI300A 的六個 GPU 小芯片的計算單元和流處理器數量必須是 MI250X 的 4 倍。如果 AMD 能夠提高時鐘速度(我們認爲從 6 納米到 5 納米工藝的轉變不太可能——不是一個巨大的跳躍),那么 AMD 會用它來嘗試在相同的功率範圍內提高時鐘速度。但我們將在公告日看到。
就像 Nvidia 將 H100 GPU 中的矩陣數學單元的性能提高到比向量單元高出數倍一樣,我們認爲 AMD 也會對 MI300A 混合計算引擎做同樣的事情。如果矩陣單元有 4 倍的改進,那么矢量單元可能只會有 2 倍的改進。這是另一種說法,許多 HPC 工作負載不會像 AI 訓練工作負載那樣加速,除非並且直到它們被調整爲在矩陣數學單元上運行。
現在,讓我們談談錢。
在我們於 2021 年 12 月的分析中,當 MI250X 首次運往橡樹嶺以建造 Frontier 機器時,我們估計其中一個 GPU motors的標價可能在 14,500 美元左右,比時售價爲 12,000 美元Nvidia “Ampere” A100 SXM4 GPU 加速器更高。在2022 年 3 月發布 H100之後,我們估計高端 H100 SXM5(您不能從 HGX 系統板單獨購买)的價格在 19,000 美元到 30,000 美元之間,並且PCI-Express 版本的 H100 GPU 的價值可能在 15,000 美元到 24,000 美元之間。當時,由於需求增加,A100 SXM4 的價格已漲至 15,000 美元左右。而就在幾周前,PCI-Express 版本的 H100 在 eBay 上以每件 40,000 多美元的價格拍賣。這太瘋狂了。
這個情況比美國這裏的二手車市場還要糟糕,是一種需求過多供應過少的通貨膨脹。當供應商知道他們無論如何都無法生產足夠的單位時,他們會喜歡這種情況。超大規模和雲建設者正在限制他們自己的开發人員對 GPU 的訪問,我們不會對雲中 GPU 容量的價格上漲感到驚訝。
當談到啓用稀疏性的 FP8 性能時,MI300A 將提供大約 3 petaflops 的峰值理論性能,但相對於 128 GB 的 HBM3 內存和大約 5.4 TB/秒的帶寬。Nvidia H100 SXM5 單元具有 80 GB 的 HBM3 內存和 3 TB/秒的帶寬,額定峰值性能爲 4 petaflops,在 FP8 數據分辨率和處理上具有稀疏性。AMD 設備的峰值性能降低了 25%,但內存容量增加了 60%,如果設備上的所有這八個 HBM3 堆棧都可以完全填充,則內存帶寬可能增加 80%。(我們當然希望如此。)我們認爲許多 AI 商店將完全可以犧牲一點峰值性能來換取更多的內存帶寬和容量,這有助於提高實際的 AI 訓練性能。
我們可以肯定地說,El Capitan 是 MI300A 計算引擎的第一线,要在普通 64 位雙精度浮點上突破 2.1 exaflops 峰值,將需要 22,000 個插槽,在這種情況下,一個插槽是一個節點。目前的“Sierra”系統已有 4320 個節點,每個節點有 4,320 個節點,每個節點有 2 個 IBM 的 Power9 處理器和 4 個Nvidia 的“Volta”V100 GPU 加速器。
Sierra 中總共有 17,280 個 GPU,如果我們對 MI300A 的 FP64 性能的猜測是正確的——我們首先承認這只是一種預感——那么 El Capitan 中的 GPU 插槽只比之前多 27%塞拉利昂。但,每個 El Capitan 插槽中有六個邏輯 GPU,因此更像是 132,000 個 GPU 來提供可能爲 2.1 exaflops 的性能。這將使兩個系統的原始 FP64 性能提高 16.9 倍,價格提高 4.8 倍,GPU 並發性提高 7.6 倍。El Capitan 必須提供至少比 Sierra 高 10 倍的性能,並且在不到 40 兆瓦的熱包絡內做到這一點。
如果我們對所有這些都是正確的,那么僅用於計算引擎的 2.1 exaflops El Capitan 的功耗約爲 25 兆瓦。El Capitan 必須提供至少比 Sierra 高 10 倍的性能,並且在不到 40 兆瓦的熱包絡內做到這一點。如果我們對所有這些都是正確的,那么僅用於計算引擎的 2.1 exaflops El Capitan 的功耗約爲 25 兆瓦。El Capitan 必須提供至少比 Sierra 高 10 倍的性能,並且在不到 40 兆瓦的熱包絡內做到這一點。如果我們對所有這些都是正確的,那么僅用於計算引擎的 2.1 exaflops El Capitan 的功耗約爲 25 兆瓦。
作爲對這整個事情的價格檢查,如果 El Capitan 機器 85% 的成本是 CPU-GPU 計算引擎,並且有 22,000 個,那么它們的成本約爲 23,200 美元。超大規模和雲建設者爲他們支付的費用絕不會低於基本上贊助 AMD 進軍 HPC 高層的美國國家實驗室所支付的費用。(這是很多“如果”,我們很清楚。)
過去,我們實際上是通過倒推 HPC 國家實驗室的深度折扣,從超級計算交易中計算出 GPU 的標價。例如,在 Sierra 中使用的 Volta V100 加速器,GPU 的標價約爲 7,500 美元,但以每張 4,000 美元左右的價格賣給了 Lawrence Livermore 和 Oak Ridge。因此,如果舊的折扣水平普遍存在,MI300A 的標價可能會超過 40,000 美元。我們認爲折扣不那么陡峭,因爲 AMD 爲 MI300A 引擎增加了更多的計算能力,而且每單位價格也低了很多——標價更像是市場價,因爲 AMD 需要積極取代 Nvidia。
請記住,當最初的 El Capitan 交易於 2019 年 8 月宣布將於 2022 年底交付並在 2023 年底前驗收時,它被指定爲具有 1.5 exaflops 持續性能和大約 30 兆瓦功耗的機器,僅用於運行系統。
這一切給我們留下了兩個問題。一:AMD能做多少台MI300A設備?如果進入 El Capitan 的數量遠遠超過計劃,那么它可以設定價格並全部出售。第二:AMD 會以激進的價格出售它們還是推到市場可以承受的價格?
第二個問題不難回答吧?在這個牛市 GPU 市場中,AI 絕對不會受到衰退的影響。如果人工智能在取代人類方面越來越成功,它甚至可能會加速經濟衰退。. . . 到目前爲止,真正的衰退和人工智能加速的衰退都沒有發生。
點擊文末【閱讀原文】,可查看原文鏈接!
*免責聲明:本文由作者原創。文章內容系作者個人觀點,半導體行業觀察轉載僅爲了傳達一種不同的觀點,不代表半導體行業觀察對該觀點贊同或支持,如果有任何異議,歡迎聯系半導體行業觀察。
今天是《半導體行業觀察》爲您分享的第3396期內容,歡迎關注。
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:AMD的千億晶體管芯片,叫板英偉達H100
地址:https://www.breakthing.com/post/57064.html