




$教育ETF(SH513360)$ $科大訊飛(SZ002230)$ $中國高科(SH600730)$ #AI教育# #職業教育# #今日話題# @指慧家 @今日話題
6月20日消息,據內部人士透露,百度文心大模型3.5版本已內測可用。早在5月末 中關村 論壇上,百度創始人、董事長兼CEO李彥宏透露,百度大模型產品“文心一言”的“母本”將迎來3.5版本。
時隔不到一個月,最新版本文心大模型達到了怎樣的實力?在公开測試集上進行的基礎模型少樣本(Few-Shot)評測顯示,文心大模型3.5(ERNIE 3.5)在多個測試集的得分已超過ChatGPT。
三大評測基准綜合評估 上萬道考題“統考”主流大模型
爲驗證主流大模型的各項綜合能力,評測在AGIEval、C-Eval和MMLU三個權威評測基准上進行綜合評估。
AGIEval評測基准是微軟研究院發布的、專門用於評估模型在“以人爲本”的標准化考試中表現水平的測試集。該基准選取20種面向普通人類考生的官方、公开、高標准的資格考試,包括普通大學入學考試(如中國的高考和美國的SAT考試)、司法考試、數學競賽、律師資格考試、國家公務員考試以及美國的GRE、GMAT等。
C-Eval評測基准是由上海交通大學、清華大學以及愛丁堡大學聯合創制和發布的中文基礎模型評測集。它包含13948個多項選擇題、涵蓋52個不同的學科,設置了四個難度級別,是面向中文語言模型的綜合考試評測集。
MMLU是伯克利大學、哥倫比亞大學、伊利諾伊大學厄巴納-香檳分校和芝加哥大學聯合發布的一種大規模多任務語言理解的基准測試,用於衡量模型的英文跨學科專業能力。該測試包含57個科目,涵蓋STEM、人文、社會科學等。
除了文心大模型3.5,評測的模型還有ChatGPT、GPT-4、ChatGLM、LLaMa系列大模型。評測可以看出大模型在能力上的優劣,同時對模型的迭代發展也有着很強的指導作用。
評測結果:文心大模型3.5中文能力超GPT-4,綜合能力超ChatGPT
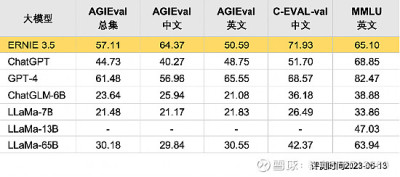
在AGIEval、C-Eval等中英文權威測試集和MMLU英文權威測試集中,國產文心大模型3.5取得了超過ChatGPT和LLaMa、ChatGLM等其他大模型的分數表現,在中文評測項中超越了GPT-4。
在中文AGIEval評測中,文心大模型3.5得分64.37,遠超ChatGLM-6B、LLaMa-7B、LLaMa-13B、LLaMa-65B,同時還超過了 ChatGPT的40.27分和 GPT-4的56.96分,位居第一。AGIEval評測英文部分中,GPT-4得分65.55居於首位,文心大模型3.5得分錄得 50.59分,僅次於GPT-4。緊隨其後的是ChatGPT錄得48.75分。
在中文C-Eval評測中,文心大模型3.5測出71.93的最高得分,不僅高於ChatGPT的51.70分,還略高於GPT-4的68.57分,領先於LLaMa-65B、LLaMa-7B、ChatGLM-6B的得分。
在英文MMLU測試中,GPT-4和ChatGPT的表現較好,分別以82.47分和68.85分領先於其他大模型。文心大模型3.5得分65.10緊隨其後,優於LLaMa-65B、LLaMa-13B、LLaMa-7B、ChatGLM-6B等模型分數。
從上述評測得分來看,文心大模型3.5版中文能力突出,甚至有超出 GPT-4 的表現;綜合能力稍遜於GPT-4,但已經在評測中超過了 ChatGPT,遠遠領先於其他开源大模型。
國產大模型中文能力優勢突出 綜合能力加速縮小差距
盡管市面上有多個大模型橫空出世,但大模型研發門檻高、難度大、投入高,依賴算力、數據等綜合支撐的現實不容小覷。在推動大模型產業化的路上,中國企業如何在大模型發展過程中發揮所長優勢,加速縮小差距?
中國工程院院士鄔賀銓曾在接受採訪時表示,中國企業在獲得中文語料和對中國文化的理解方面比外國企業有天然的優勢,中國制造業門類最全,具有面向實體產業訓練產業AIGC的有利條件。在算力方面中國已具有較好的基礎。
以百度文心大模型3.5爲例,與3.0版本相比,通過各項算法和數據的優化,尤其是百度首創的知識增強和檢索增強技術的優化,新版本文心大模型在各項能力上均有明顯提升。據了解,百度人工智能四層架構的端到端優化,尤其是框架和模型層的協同優化,讓文心大模型訓練速度、模型效果加速提升。
創新工場董事長兼CEO李开復也曾公开表示“中國擁有豐富的中文語料和龐大的市場,通過發展AI大模型,中國可以推動創 新產業 的發展,實現科技與經濟的雙重紅利。而且中國擁有龐大基數的年輕工程師和最堅韌的企業家,爲發展AI大模型提供了強大的人才支持,技術領先、策略靈活、市場反應快、能打硬仗、落地執行力強,將是中國大模型公司的成功關鍵。”
眼下,市場呼喚大模型,呼喚先進可用的 AI大模型。相信以百度等爲代表的中國科技公司,基於對中國文化的感悟和對中國市場的理解,能夠做出不遜於國外公司的AI應用。在數智化的徵程上,中國企業應積極迎接挑战,持續創新。
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:百度文心大模型3.5已內測應用 實測得分超越ChatGPT
地址:https://www.breakthing.com/post/70317.html