




當下,百度文心大模型、華爲盤古大模型、騰訊混元大模型、阿裏通義大模型正在加快向GPT模型追趕的步伐。#GPT產業鏈行情持續爆發##大模型軍備競賽白熱化##熱度重燃!AI行情或進下半場#
那么什么是大模型,其底層邏輯是什么,有哪些玩家,市場空間有多大,我們來一探究竟。
一、什么是AI大模型 $拓維信息(SZ002261)$$鴻博股份(SZ002229)$$科大訊飛(SZ002230)$
近半年AI大模型持續推出,從ChatGPT、文心一言在多場景廣泛深入地應用,標志着AI大模型時代已來臨。
那么什么是AI大模型?大到什么程度才能稱之爲大模型?AI大模型是指一個龐大復雜的神經網絡,需要通過存儲更多的參數來增加模型的深度和寬度,從而提高模型的表現能力,參數從百億起步,對大量數據進行訓練並產生高質量的預測結果。最著名的AI大模型是OpenAI的GPT-3模型參數規模達1750億,PaLM-E的參數規模更是達到了5620億。
相比傳統AI模型,大模型的優勢體現在於:
(1)解決AI過於碎片化和多樣化的問題。大模型採用“預訓練 下遊任務微調”的方式,首先從大量標記或者未標記的數據中捕獲信息,將信息存儲到大量的參數中,再進行微調,極大提高模型的泛用性。
(2)具備自監督學習功能,降低訓練研發成本。可以將自監督學習功能表觀理解爲降低對數據標注的依賴,大量無標記數據能夠被直接應用。這樣一來,一方面降低人工成本,另一方面,使得小樣本訓練成爲可能。
(3)擺脫結構變革桎梏,提高模型精度上限。隨着神經網絡結構設計技術逐漸成熟並开始趨同,想要通過優化神經網絡結構從而打破精度局限變得困難。而研究證明,更大的數據規模確實提高了模型的精度上限。
二、我國主要大模型盤點
目前中美之間圍繞大模型的研發和落地展开競爭。國內大模型廠商主要包括百度、騰訊、阿裏、商湯、華爲等企業,也有智源研究院、中科院自動化所等研究機構,同時英偉達等芯片廠商也紛紛入局。
數據、算法、算力是AI發展的驅動力,其中數據是AI發展的基石,中國數據規模增速或排名全球第一。據IDC統計,中國數據規模將從2021年的18.51ZB增長至2026年的56.16ZB,年均增長速度CAGR爲24.9%,增速位居全球第一。
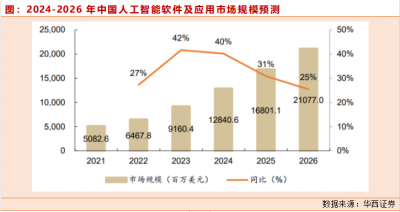
1、百度:文心一言大模型,AI應用場景全覆蓋
2023年3月16日,百度官方發布“文心一言”。“文心一言”是百度研發的知識增強大語言模型,擁有文學創作、商業文案創作、數理邏輯推理、中文理解和多模態生成五大能力。文心一言在百度ERNIE及PLATO系列模型基礎上研發而成,關鍵技術包括監督精調、人類反饋的強化學習、提示、知識增強、檢索增強以及對話增強。其中,百度在知識增強、檢索增強和對話增強方面實現技術創新,使得文心一言在性能上實現重大進步。

百度經過11年積累了全棧人工智能技術,從芯片層、框架層、模型層到應用層。這四層之間形成層到層反饋、端到端優化,尤其是模型層的文心大模型和框架層的飛槳(產業級开源开放平台),在开發文心一言的過程中,它們的協同優化起到了至關重要的作用。模型層的文心大模型包括NLP大模型、CV大模型和跨模態大模型,在此基礎上开發了大模型的开發工具、輕量化工具和大規模部署工具,而且支持零門檻的 AI 开發平台以及全功能AI开發平台。
百度大模型相關標的:漢得信息、東軟集團、宇信科技、致遠互聯、軟通動力、銀之傑、風語築、掌閱科技、藍色光標等。
2、騰訊:混元AI大模型,加速大模型應用落地
騰訊2022年底發布國內首個低成本、可落地的NLP萬億大模型:混元AI大模型。HunYuan協同騰訊預訓練研發力量,旨在打造業界領先的AI預訓練大模型和解決方案,以統一的平台,實現技術復用和業務降本,支持更多的場景和應用。
當前HunYuan完整覆蓋NLP大模型、CV大模型、多模態大模型、文生圖大模型及衆多行業、領域任務模型,自2022年4月,先後在MSR-VTT、MSVD等五大權威數據集榜單中登頂,實現跨模態領域的大滿貫;2022年5月,於CLUE(中文語言理解評測集合)三個榜單同時登頂,一舉打破三項紀錄。基於騰訊強大的底層算力和低成本高速網絡基礎設施,HunYuan 依托騰訊領先的太極機器學習平台,推出了HunYuan-NLP1T大模型並登頂國內權威的自然語言理解任務榜單CLUE。
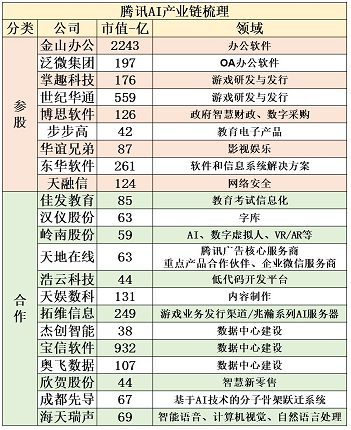
騰訊大模型相關標的:博思軟件、世紀華通、掌趣科技、常山北明、四維圖新、泛微網絡、長亮科技等。
3、阿裏:通義大模型,开源釋放大模型應用潛力
阿裏達摩院一直以來深耕多模態預訓練,並率先探索通用統一大模型。阿裏達摩院於2021年發布使用512卡V100GPU實現全球最大規模10萬億參數多模態大模型M6,並於2022年發布最新通義大模型系列。通義大模型注重开源开放,首次通過“統一範式”實現多模態、多任務、多結構的運行,並通過模塊化設計實現高效率高性能。
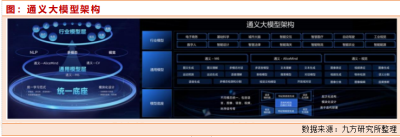
通義大模型整體架構中,最底層爲統一模型底座,通義統一底座中借鑑了人腦模塊化設計,以場景爲導向靈活拆拔功能模塊,實現高效率和高性能。中間基於底座的通用模型層覆蓋了通義-M6、通義-AliceMind 和通義-視覺,專業模型層深入電商、醫療、娛樂、設計、金融等行業。
阿裏大模型相關標的:恆生電子、千方科技、石基信息、衆信旅遊、衛寧健康、金橋信息等。
4、華爲:盤古大模型,打造全棧使能體系
2021年4月25日,在華爲开發者大會(Cloud)上,華爲雲發布了盤古系列超大規模預訓練模型。自“盤古大模型”發布以來,已經發展出L0、L1、L2三大階段的成熟體系持續進化。
L0爲基礎模型,這類模型無法直接應用到行業場景中,需要與行業數據結合,混合訓練得到行業大模型。其中包括 NLP大模型、CV大模型、多模態大模型、科學計算大模型等基礎大模型;
L1爲行業模型,行業模型可以直接在具體細分場景進行部署,由此也就得到了細分場景模型,比如氣象、礦山、電力等行業大模型;
L2爲細分場景模型,比如電力行業的無人機巡檢、金融違約風險識別模型等。

華爲大模型相關標的:拓維信息、特發信息、潤和軟件、神州數碼、寶蘭德、創意信息、科藍軟件、軟通動力、賽意信息等。
三、總結
我們認爲,各大巨頭目前在大模型技術上基本同源,且都具有資金、算力、人才、數據等發展條件,未來有望成爲我國大模型的第一梯隊。
各家在應用場景上各有所長:百度具有搜索、小度智能音箱等應用場景;騰訊具有微信、QQ、遊戲等應用場景;阿裏具有電商、釘釘等應用場景;華爲在2B應用方面獨具優勢。
未來各家將結合自身優勢,發力大模型研發及應用落地,我國的大模型產業將迎來快速發展階段。
風險提示:本文中提及的相關個股基於公开數據整理,僅供參考!投資者應獨立決策並承擔投資風險。
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:國內AI大模型盤點!誰更有潛力?
地址:https://www.breakthing.com/post/75385.html