





·聚焦:人工智能、芯片等行業
歡迎各位客官關注、轉發
前言:
2022年的WAIC,和大模型相關的論壇寥寥無幾,而今年,不聊大模型的論壇屈指可數,參展的大模型高達30余個。
2023世界人工智能大會,大模型當之無愧成爲[頂流]。
作者 | 方文三 圖片來源 | 網 絡 
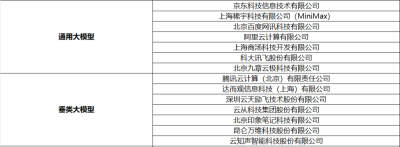
大模型的[國家隊]集結
WACI 2023大會上,由國家標准委指導的國家人工智能標准化總體宣布:
我國首個大模型標准化專題組組長由上海人工智能實驗室與百度、華爲、阿裏等企業聯合擔任。
新組建的專題小組將承擔大模型的標准化制訂工作,目的是推動大模型和標准化的實踐結合,促進人工智能產業的健康發展。
一方面,美國政府又升級制裁,將限制中國企業使用美國廠商的雲計算服務,堵住中國人工智能公司可能通過使用雲服務繞過當前芯片出口管制規則的漏洞。
另一方面,這場世界人工智能大會,也給全球展現出了中國AI產業、大模型技術發展的蓬勃動力。

急待彌合新技術和場景的鴻溝
或許對自研大模型的廠商而言,商業化的事還可以拖一拖,底層技術創新是第一要務。
但對To B AI應用廠商來說,一邊是新技術對現有技術路线帶來的潛在顛覆效應,另一邊是新需求誕生創造出的市場增長想象空間。
如何彌合新技術和需求場景之間的鴻溝,似乎是更加急迫的事情。
大模型之战逐漸步入後半場,更多人开始關注大模型與實體產業的結合,企業也接連展示其產品的應用場景。
也因此,國內頭部科技企業的發力點從通用人工智能大模型,轉向行業大模型。
比如騰訊在6月中旬發布了一站式行業大模型精選商店騰訊雲Maas;
而華爲也在WAIC舉辦期間推出了賦能千行百業的盤古大模型3.0;
而京東也重磅推出了自研產業大模型言犀。
很顯然,通用大模型與產業大模型,已引起了國內頭部科技公司AI战略的分野。
雖然兩者並不是對立關系,但不同的路线與方向會令其駛向不同的遠方。
 商湯:熱門行業終端落地應用
商湯:熱門行業終端落地應用 今年4月,商湯發布了[日日新]大模型體系,包括千億級參數的語言大模型[商量]、文生圖創作平台[秒畫]、AI數字人視頻生成平台[如影]、3D內容生成平台[瓊宇]和[格物],這些都在展台對觀衆开放體驗。
同時,宣布了[商湯日日新SenseNova]大模型體系的多方位全面升級,以及在該體系下的一系列大模型產品更新和落地成果。
此外,商湯也着重介紹並展示了其大模型技術自正式發布以來與產業各方的應用實踐。
包括商湯絕影最新打造的智能座艙產品和車路雲協同交通體系等;
以及在金融、醫療、電商、移動終端、產業園區等行業生產實踐中的落地應用。
 華爲:全面布局行業大模型
華爲:全面布局行業大模型 華爲也正式發布了AI大模型華爲雲盤古大模型3.0。
目前,華爲雲盤古大模型3.0已在煤礦、鐵路、氣象、金融、代碼开發、數字內容生成等領域發揮作用,提升生產效率、降低研發成本。
盤古大模型3.0是一個面向行業的大模型系列,有基礎大模型、行業大模型、專用大模型三層架構。
包括[5+N+X]三層架構,L0層包括自然語言、視覺、多模態、預測、科學計算五個基礎大模型。
華爲可能不想寫詩,但大模型ToB(企業級服務)的錢,卻很想賺到。

百度:多層全棧布局完成
自今年3月份發布文心一言大模型後,百度已在芯片(昆侖芯)、框架(飛槳社區)、模型(文心系列)、應用(百度雲合作夥伴)四層完成全棧布局。
訊飛:以不同AI+應用場景切入訊飛展示了[星火]大模型在辦公、教育、醫療、工業、金融、汽車和數字員工的應用場景。
不僅展示了大模型在PC與手機等不同終端中的應用實例。
還以不同行業場景爲切入點,讓公衆直觀了解大模型如何賦能學習機助力教育提質增效,幫助醫療行業搭建個性化診後康復管理平台等行業類創新應用。
京東:根據自身業務打造行業大模型
京東的優勢在於有豐富的零售、物流、金融、健康、政務等垂直場景的數據和行業經驗積累。
因此,言犀大模型的定位就是面向產業,訓練時融合70%的通用數據與30%數智供應鏈原生數據,針對知識密集型、任務型產業場景。
對於有模型訓練需求的客戶,京東將提供言犀大模型开放計算平台、向量數據庫基礎設施能力,以及2個行業數據平台。
京東還將零售、金融、健康、物流等廣泛專業領域的產業數據也融合到基座模型進行訓練。
除了大語言模型,京東也在語音、視覺等多模態模型上進行了研發。

阿裏:开源社區降本增效
會上,阿裏雲發布了AI繪畫創作大模型通義萬相,並开啓定向邀測。
不過,更多被提到的是MaaS(模型即服務)理念。
在开發者生態層,阿裏發起的大模型开源社區[魔搭],目前集聚了180多萬AI开發者和900多個優質AI模型。
用戶通過輸入指令,可以一鍵調用其他的AI模型,用多個模型協同完成復雜任務,這也是降低大模型使用門檻的方式。
用阿裏雲CTO周靖人的話來說:[把促進中國大模型生態的繁榮作爲首要目標。]

騰訊:避开擁擠切入行業大模型
騰訊選擇從MaaS切入產業大模型領域。
通過技術中間層向外部企業提供預訓練、精調和應用开發等解決方案。
騰訊作爲一家雲服務提供商,擁有龐大的技術資源和豐富的行業經驗,可以爲企業提供強大的計算和存儲能力,支持大規模的產業大模型訓練和優化。
在騰訊看來,各家通用大模型水平最多也就在 GPT-3.5 水平附近,說自己超越ChatGPT往往會言過其實,[多騰訊一個不多,少騰訊一個不少]。
那樣還不如主打行業大模型概念,爭取在行業大模型上成爲第一。
而且,對行業大模型來說,其不需要像通用大模型一樣耗費巨資訓練通用數據,而更側重行業本身的數據。
各垂直領域的行業大模型早已被多家企業先後推出。騰訊不做通用的、聊天式的大模型,也是揚長避短。
 凡是投入,都會有限度
凡是投入,都會有限度 如果是做模型是烹飪,數據好比是食材,大模型對高質量的[食材]需求更高。
但在公开互聯網中,中文的高質量數據本就偏少,大模型廠商其實很難建立起數據壁壘。
在國內廠商尚在追趕GPT-3.5的情況下,沒有誰能顯著拉开差距。
本質上,AI大模型訓練仍然昂貴,即便是大廠,也不可能不求回報地一直投入。
這意味着,國內廠商剛开始做大模型,就面臨着更殘酷的生存考驗。
搶着在行業落地,也是希望能盡快商業化,再投入到AI模型的开發和訓練中。
不過造輪子不等於沒意義,而是在發展初期必需要做的積累和儲備。
如果把大模型產業類比學數學,現階段各家廠商都在做的洗數據、堆參數、調代碼,就好比每天都要背九九乘法表的。
等到有了足夠的積累才有可能去學线性代數、微積分這些更高級的知識,跳出造輪子的階段去做創新。
 結尾:
結尾: 當一種新技術熱潮顯現,往往有兩種演進路徑:
一是新技術兌現了價值,成爲基礎設施的一部分,不再被關注,比如互聯網、推薦算法。
另一個是新技術短期內無法兌現價值,然後被新的熱潮搶走資源與風頭。
各大廠商的战略配方是,去大模型糟粕,取其精華;或者[借力打力]。
部分資料參考:數字時氪:《大模型無法一步到位?還得是「熟悉的配方」》,TE智庫:《現階段廠商比客戶更需要大模型》,DoNews:《[舊趨勢]退場,大模型稱王》,智能湧現:《30個大模型,搶着落地》,商業秀:《2023WAIC,重新審視AI大模型時代》,國際金融報:《AI大模型,开啓[战國]時代!》,零態LT:《30家企業爭鳴WAIC:大模型進入高維战》,億歐智庫:《大模型進入战國時代,從WAIC看誰是七雄》
本公衆號所刊發稿件及圖片來源於網絡,僅用於交流使用,如有侵權請聯系回復,我們收到信息後會在24小時內處理。
END
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:產業丨WAIC上的大模型時代战國七雄
地址:https://www.breakthing.com/post/80022.html