




Nvidia不久前發布了下一代GPU架構,架構名字爲“Hopper”(爲了紀念計算機科學領域的先驅之一Grace Hopper)。根據Nvidia發布的具體GPU規格,我們認爲Nvidia對於Hopper的主要定位是進一步加強對於人工智能方面的算力,而其算力升級依靠的不僅僅是硬件部分,還有不少算法和軟件協同設計部分,本文將爲讀者做詳細分析。我們認爲,在Nvidia更下一代的GPU中,我們有望看到芯粒技術成爲新的亮點來突破其瓶頸。
Hopper的性能有多強
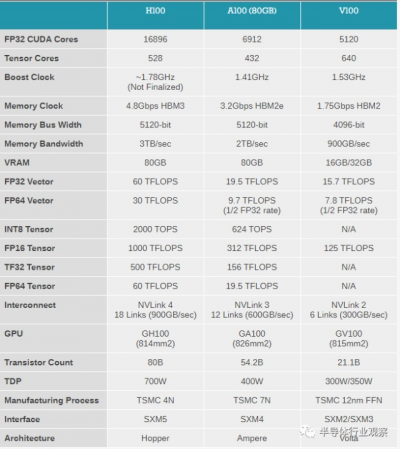
根據Nvidia公布的數據,基於Hopper架構的GPU(H100)使用TSMC的4nm工藝設計,將會是Ampere架構(使用TSMC 7nm工藝)之後的又一次重大升級,其16位浮點數峰值算力(FP16)將會由之前的312 TFLOPS增加到1000 TFLOPS,INT8峰值算力則由之前的624TOPS增加到2000TOPS。由此可見FP16(常用於人工智能訓練)和INT8(常用於人工智能推理)的峰值算力基本上都是翻了三倍,這個H100相對A100峰值算力提升的比例基本符合A100和再上一代GPU V100的提升數字。
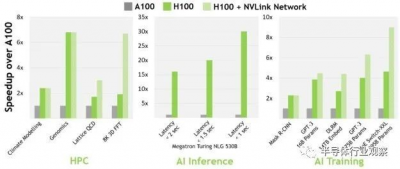
而根據Nvidia官方公布的具體任務性能提升,我們也可以看到大多數人工智能相關任務的性能提升基本在2-4倍之間(尤其是使用transformer類模型的性能提升較爲突出,接近4倍),初看也和峰值算力提升三倍基本吻合。但是如果我們仔細分析Nvidia H100具體芯片指標,我們認爲在人工智能任務中,H100的提升不僅僅是來自於一些硬件指標(例如核心數量,DRAM帶寬,片上存儲器)的提升,更是來自於Nvidia做了算法硬件協同設計。例如,Nvidia在Hopper架構中引入了爲Transformer系列模型專門設計的八位浮點數(FP8)計算支持,並且還加入了專門的Transformer engine硬件模塊來確保transformer模型的運行效率。因此,我們看到在Nvidia公布的人工智能任務性能提升中,使用transformer的任務(如GPT-3)的性能提升要高於傳統的基於CNN(如Mask R-CNN)的性能提升。
存儲方面提升相對較小
在人工智能等高性能計算中,存儲(包括DRAM接口帶寬和片上存儲容量)和計算單元一樣重要,在很多時候存儲甚至會成爲整體性能的瓶頸,例如峰值算力無法持續,導致平均計算能力遠低於峰值算力。在Hopper架構中,我們看到了峰值算力提升大約是Ampere的三倍,然而在DRAM帶寬和片上存儲方面,Hopper相對於Ampere的提升較小,只有1.5倍和1.25倍。
在DRAM帶寬方面,我們看到H100有兩個版本,其中使用最新一代HBM3的版本的內存帶寬是3TB/s,相比於A100(2TB/s)的提升爲1.5倍,相比峰值算力的三倍提升相對較小。反觀A100相對更上一代V100的內存帶寬提升爲2.2倍,因此我們認爲H100的HBM3內存帶寬提升幅度確實相對上一代來說較小。我們認爲,HBM3帶寬提升較小可能和功耗有關。
仔細分析Hopper發布的GPU,我們發現Hopper架構的GPU目前有兩個品類,一個是使用HBM3內存的版本,而另一個是仍然使用HBM2e的版本。HBM3版本的H100相對於使用HBM2e版本的H100在其他芯片架構上(包括計算單元)的差距不過10%(HBM3版本的計算單元較多),但是在功耗(TDP)上面,HBM3版本的H100的TDP比HBM2e版本H100整整高出兩倍(700W vs. 350W)。即使是相對於上一代使用7nm的Ampere架構,其功耗也提高了近兩倍,因此能效比方面提升並不多,或者說即使更先進的芯片工藝也沒法解決HBM3的功耗問題。因此,我們認爲H100 HBM3版本DRAM內存帶寬增加可能是受限於整體功耗。而當DRAM帶寬提升較小時,如何確保DRAM帶寬不成爲性能瓶頸就是一個重要的問題,因此Nvidia會提出FP4和Transformer Engine等算法-硬件協同設計的解決方案,來確保在執行下遊任務的時候仍然效率不會受限。
除了DRAM帶寬之外,另一個值得注意的點是Hopper GPU的片上存儲增長僅僅是從A100的40MB增長到了H100的50MB;相對來說,A100的片上存儲相對於更上一代V100則是增加了6倍。我們目前尚不清楚H100上片上存儲增長這么少的主要原因,究竟是因爲Nvidia認爲40-50MB對於絕大部分任務已經夠用,還是因爲工藝良率的原因導致再加SRAM會大大提升成本。
但是,無論如何,隨着人工智能模型越來越復雜, 對於片上存儲的需求越來越高,片上存儲容量較小就會需要有更好的人工智能模型編譯器和底層軟件庫來確保模型執行過程中能有最高的效率(例如,確保能把模型數據更好地劃分以盡量在片上存儲中執行,而盡可能少地使用DRAM)。Nvidia在這一點上確實已經有了很深厚的積累,各種高性能相關的軟件庫已經有很好的成熟度。
我們估計Nvidia有強大的軟件生態作爲後盾也是它有能力在設計中放較少片上存儲(以及較小的DRAM帶寬)的重要原因。這一點結合之前Nvidia在Hopper引入的新模型-芯片結合設計技術,例如能大大降低內存需求的FP4技術,以及爲了Transformer模型專門設計的Transformer Engine,這些其實從正反兩面論證了我們的觀點,即Hopper架構很多的性能提升事實上是來自於軟硬件結合設計,而並非僅僅是芯片/硬件性能提升。
Nvidia下一步突破點在哪裏?
如前所述,Nvidia的Hopper架構GPU的芯片領域的突破相比上一代Ampere架構並沒有特別大,而是主要由軟硬件結合設計實現性能提升。我們看到在存儲領域(包括DRAM接口和片上存儲容量)的提升尤其小,而這可能也會是Nvidia進一步提升GPU性能的一個重要瓶頸,當然突破了之後也會成爲一個重要的技術壁壘。如前所述,HBM3的功耗可能是一個尚未解決的問題,而如何在芯片上放入更多的片上存儲器則將會被良率和成本所限制。
在存儲成爲瓶頸的時候,芯片粒(chiplet)將會成爲突破瓶頸的重要技術。正如之前所討論的,當片上存儲容量更大時,GPU對於DRAM等片外存儲的需求就會越來越少,而片上存儲的瓶頸則是良率和成本。一般來說,芯片的良率和其芯片面積成負相關,當芯片面積越大時,則芯片良率會相應下降,尤其是在先進工藝中,良率更是一個重要考量。而芯片粒則是可以大大改善這個問題:芯片粒技術並不是簡單地增加芯片的面積(例如更多片上存儲),而是把這些模塊分散在不同的芯片粒中,這樣一來整個芯片粒的芯片面積就會大大下降,從而改善良率。
此外,隨着GPU規模越來越大,爲了能更好地控制整體良率,使用芯片粒技術也是一個自然地選擇。我們認爲,在今天HBM3技術的功耗遇到瓶頸的時候,或者說HBM技術整體從功耗上遇到挑战的時候,下一步的重要方向一定是從簡單地增加DRAM帶寬和在單個芯片上放更多晶體管變到更精細地設計架構和片上存儲,這也就讓芯片粒佔到了舞台中央。
事實上芯片粒和GPU的結合對於業界來說並不陌生。事實上Nvidia最有力地競爭對手AMD已經把芯片粒技術使用在GPU上,此外在片上存儲部分AMD也發布了3D V-Cache,可望成爲下一代繼續增加片上存儲的重要技術。Nvidia在芯片粒方面也有相關布局,這次與Hopper同時間發布的用於芯片粒互聯的UCIe標准也意味着Nvidia在芯片粒領域的投資。我們認爲,在Nvidia未來公布的GPU中,非常有可能可以看到芯片粒技術的大量應用,而這結合Nvidia的軟硬件協同優化技術有可能會成爲下一代Nvidia GPU的最大亮點。
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:Nvidia最新芯片暗示:堆料模式走到盡頭
地址:https://www.breakthing.com/post/8258.html