





AIGC是否會取代人類?
”
作者|Chengxi 編輯|蔓蔓周
過去18個月,AI內容生成(AIGC)是無疑是硅谷科技創投圈內最火爆、最熱門的話題。
DALL-E(2021年1月推出)Midjourney(2022年7月推出)Stable Diffusion(2022年8月推出)這類2D生成式工具,能夠在短短幾秒內將文本提示(prompt)生成藝術風格的圖片。隨着這類2D AIGC工具的演化和進步,藝術家、設計師和遊戲工作室的創作工作流正在被迅速顛覆革新。AIGC的下一個突破口在哪?不少投資者和領域資深人士都給出了預測—3D數據生成。我們注意到3D AIGC正在經歷着2D AIGC曾經發展過的階段。這篇文章中,我們將更深入地討論AIGC在3D數據領域的新突破,以及展望生成式AI工具如何提高3D數據生成的效率和創新。
01 回顧2D AIGC的高速發展 2D AIGC的發展可以簡單概括爲以下三個發展階段: 第一階段:智能圖像編輯 早在2014年,隨着生成對抗網絡(GAN,典型後續工作StyleGAN)和變分自編碼器(VAE,典型後續工作VQVAE,alignDRAW)的提出,AI模型便开始被廣泛運用到2D圖片的智能生成與編輯中。早期的AI模型主要被用於學習一些相對簡單的圖像分布或者進行一些圖像編輯,常見的應用包括:人臉生成、圖像風格遷移、圖像超分辨率、圖像補全和可控圖像編輯。
但早期的圖像生成/編輯網絡與文本的多模態交互非常有限。此外,GAN網絡通常較難訓練,常遇到模式坍塌(mode collapse)和不穩定等問題,生成的數據通常多樣性較差,模型容量也決定了可利用數據規模的上限;VAE則常遇到生成的圖像模糊等問題。 第二階段:文生圖模型的飛躍 隨着擴散生成(diffusion)技術的突破、大規模多模態數據集(如LAION數據集)和多模態表徵模型(如OpenAI發布的CLIP模型)的出現與發展,2D圖像生成領域在2021年前後取得重要進展。圖像生成模型开始與文本進行深入的交互,大規模文生圖模型驚豔登場。
當OpenAI在2021年初發布DALL-E時,AIGC技術开始真正顯現出巨大的商業潛力。DALL-E可以從任意的文本提示中生成真實和復雜的圖像,並且成功率大大提高。一年之內,大量文生圖模型迅速跟進,包括DALL-E 2(於2022年4月升級)和Imagen(谷歌於2022年5月發布)。雖然這些技術當時還無法高效幫助藝術創作者產出能夠直接投入生產的內容,但它們已經吸引了公衆的注意,激發了藝術家、設計師和遊戲工作室的創造力和生產潛力。 第三階段:從驚豔到生產力 隨着技術細節上的完善和工程優化上的迭代,2D AIGC得到迅猛發展。到2022年下半年,Midjourney、Stable Diffusion等模型已成爲了廣受歡迎的AIGC工具。他們通過大規模的訓練數據集的驅動,使得AIGC技術在現實世界應用中的性能已經讓媒體、廣告和遊戲行業的早期採用者受益。此外,大模型微調技術的出現與發展(如ControlNet和LoRA)也使得人們能夠根據自己的實際需求和少量訓練數據來“自定義”調整、擴展AI大模型,更好地適應不同的具體應用(如二次元風格化、logo生成、二維碼生成等)。
現在,使用AIGC工具進行創意和原型設計很多情況下只需幾小時甚至更短,而不是過去需要的幾天或幾周。雖然大多數專業的圖形設計師仍然會修改或重新創建AI生成的草圖,但個人博客或廣告直接使用AI生成的圖像的情況越來越普遍。  alignDRAW, DALL-E 2, 和Midjourney 文本轉圖像的不同效果。
alignDRAW, DALL-E 2, 和Midjourney 文本轉圖像的不同效果。
除了文本轉圖像,2D AIGC持續有更多的最新發展。例如,Midjourney和其他創業公司如Runway和Phenaki正在开發文本到視頻的功能。此外,Zero-1-to-3已經提出了一種從物體的單一2D圖像生成其在不同視角下對應圖片的方法。
由於遊戲和機器人產業對3D數據的需求不斷增長,目前關於AIGC的前沿研究正在逐漸向3D數據生成轉移。我們預計3D AIGC會有類似的發展模式。
02 3D AIGC的“DALL-E”時刻 近期在3D領域的種種技術突破告訴我們,3D AIGC的“DALL-E”時刻正在到來! 從2021年末的DreamFields到2022年下半年的DreamFusion和Magic3D,再到今年五月的ProlificDreamer,得益於多模態領域和文生圖模型的發展,學術界文生3D模型也得到了不少突破。不少方法都能夠從輸入文本生成高質量的3D模型。
然而這些早期探索大多數需要在生成每一個3D模型時,都從頭優化一個3D表示,從而使得3D表示對應的各個2D視角都符合輸入和先驗模型的期待。由於這樣的優化通常需要成千上萬次迭代,因此通常非常耗時。例如,在Magic3D中生成單個3D網格模型可能需要長達40分鐘,ProlificDreamer則需要數小時。此外,3D生成的一個巨大挑战便是3D模型必須具備從不同角度看物體形狀的一致性。現有的3D AIGC方法常遇到雅努斯問題(Janus Problem),即AI生成的3D對象有多個頭或者多個面。  由於ProlificDreamer缺乏3D形狀一致性而出現的雅努斯問題。左邊是一只看似正常的藍鳥的正面視圖。右邊是一幅令人困惑的圖像,描繪了一只有雙面的鳥。 但另外一方面,一些團隊正在嘗試突破現有的基於優化的生成範式,通過單次前向預測的技術路线來生成3D模型,這大大提高了3D生成速度和准確度。這些方法包括Point-E和Shap-E(分別於2022年和2023年由OpenAI發布)和One-2–3–45(2023年由加州大學聖地亞哥分校發布)。特別值得注意的是,最近一個月發布的One-2–3–45能夠在僅45秒的時間內從2D圖像生成高質量和具備一致性的3D網格!
由於ProlificDreamer缺乏3D形狀一致性而出現的雅努斯問題。左邊是一只看似正常的藍鳥的正面視圖。右邊是一幅令人困惑的圖像,描繪了一只有雙面的鳥。 但另外一方面,一些團隊正在嘗試突破現有的基於優化的生成範式,通過單次前向預測的技術路线來生成3D模型,這大大提高了3D生成速度和准確度。這些方法包括Point-E和Shap-E(分別於2022年和2023年由OpenAI發布)和One-2–3–45(2023年由加州大學聖地亞哥分校發布)。特別值得注意的是,最近一個月發布的One-2–3–45能夠在僅45秒的時間內從2D圖像生成高質量和具備一致性的3D網格!

這些3D AIGC領域最新的技術突破,不僅大大提高了生成速度和質量,同時讓用戶的輸入也變得更加靈活。用戶既可以通過文本提示進行輸入,也可以通過信息量更加豐富的單張2D圖像來生成想要的3D模型。這大大擴展了3D AIGC在商業應用方面的可能性。
03 AI革新3D生產過程 首先,讓我們了解一下傳統3D設計師創建3D模型,所需要經歷的工作流程: 1.概念草圖:概念藝術設計師根據客戶輸入和視覺參考進行頭腦風暴和構思所需的模型。 2.3D原型制作:模型設計師使用專業軟件創建模型的基本形狀,並根據客戶反饋進行迭代。 3.模型細化:將細節、顏色、紋理和動畫屬性(如綁定、照明等)添加到粗糙的3D模型中。 4.模型最終定型:設計師使用圖像編輯軟件增強最終的渲染效果,調整顏色,添加效果,或進行元素合成。 這個過程通常需要幾周的時間,如果涉及到動畫,甚至可能需要更長。然而,如果有AI的幫助,上述每個步驟都可能會更快。 1.強大的多視圖圖像生成器(例如,基於Stable Diffusion和Midjourney的Zero-1–to–3)有助於進行創意頭腦風暴,並生成多視圖圖像草圖。 2.文本到3D或圖像到3D技術(例如,One-2–3–45或Shap-E)可以在幾分鐘內生成多個3D原型,爲設計師提供了廣泛的選擇空間。 3.利用3D模型優化(例如,Magic 3D或ProlificDreamer),選定的原型可以在幾小時內自動進行精煉。 4.一旦精煉的模型准備好,3D設計師就可以進一步設計並完成高保真模型。 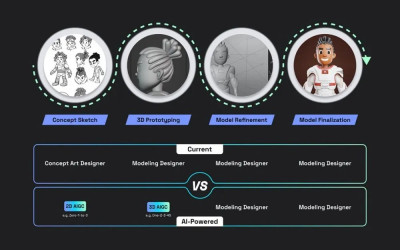 傳統與AI驅動的3D生產工作流程對比
傳統與AI驅動的3D生產工作流程對比
04 3D AIGC是否會取代人類?
我們的結論是,暫時不會。人仍然是3D AIGC環節中不可缺失的一環。 盡管以上提到的3D模型生成技術,能在機器人技術、自動駕駛和3D遊戲中有許多應用,然而目前的生產流程仍然不能滿足廣泛的應用。 爲此,硅兔君採訪了來自加州大學聖迭戈分校的蘇昊教授,他是3D深度學習(3D Deep Learning)和具身人工智能(Embodied AI)領域的領軍專家,也是One-2–3–45模型的作者之一。蘇昊教授認爲,目前3D生成模型的主要瓶頸是缺乏大量高質量的3D數據集。目前常用的3D數據集如ShapeNet(約52K 3D網格)或Objaverse(約800K 3D模型)包含的模型數量和細節質量都有待提升。尤其是比起2D領域的大數據集(例如,LAION-5B),它們的數據量仍然遠不夠來訓練3D大模型。
蘇昊教授曾師從幾何計算的先驅、美國三院院士Leonidas Guibas教授,並曾作爲早期貢獻者參與了李飛飛教授領導的ImageNet項目。受到他們的啓發,蘇昊教授強調廣泛的3D數據集在推進技術方面的關鍵作用,爲3D深度學習領域的出現和繁榮做出了奠基性工作。此外,3D模型遠比2D圖像的復雜很多,例如:1.部件結構:遊戲或數字孿生應用需要3D對象的結構化部件(例如,PartNet),而不是單一的3D網格; 2.關節和綁定:與3D對象互動的關鍵屬性;3.紋理和材料:例如反光率、表面摩擦系數、密度分布、楊氏模量等支持交互的關鍵性質; 4.操作和操控:讓設計師能夠對3D模型進行更有效地交互和操縱。而以上幾點,就是人類專業知識能夠繼續發揮重要作用的地方。蘇昊教授認爲,在未來,AI驅動的3D數據生成應具有以下特性:1.支持生成支撐交互性應用的3D模型,這種交互既包括物體與物體的物理交互(如碰撞),也包括人與物體的交互(物理與非物理的交互方式),使得3D數據在遊戲、元宇宙、物理仿真等場景下能夠被廣泛應用; 2.支持AI輔助的3D內容生成,使得建模的生產效率更高; 3.支持Human-in-the-loop的創作過程,利用人類藝術天賦提升生成數據的質量,從而進一步提升建模性能,形成閉環的數據飛輪效應。類似於過去18個月來像DALL-E和ChatGPT這樣的技術所取得的驚人發展,我們堅信在3D AIGC領域即將發生,其創新和應用極有可能會超過我們的預期,硅兔君會持續深入探索和輸出。 文末互動: 你認爲AIGC會對人類產生哪些深遠影響? 評論區留言告訴我們哦~
 別忘了點關注,不迷路啊。
別忘了點關注,不迷路啊。

 食品科技又整新活!連植物都不用,有空氣就能“無中生肉”
食品科技又整新活!連植物都不用,有空氣就能“無中生肉”
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:2D到3D新突破!深度AIGC 技術剖析,一文看懂3D數據生成的歷史及現狀
地址:https://www.breakthing.com/post/82675.html