



編者按:
DPU芯片,跟之前的GPU、AI芯片最大的不同在於,DPU是集成多種領域加速於一體的集成加速平台。如果說GPU、AI加速芯片,是CPU+xPU單個異構計算的分離趨勢,那么DPU的出現,則預示着,整個計算系統,在從單異構的分離逐漸走向多異構的融合。 當然,DPU僅僅只是开始,更加充分的融合,將在本文詳細分析和介紹。 1 數據中心(相比終端)系統的特點
1.1 軟件業務和硬件平台分離
數據中心軟件有一個非常重要的要求,就是高可用性(High Availability,HA)。比如通過負載均衡器實現後端服務的高可用,負載均衡器本身也是通過集群機制實現自身的高可用。底層的VM通過熱遷移實現高可用,容器則是通過在新的環境自動拉起新實例來實現容器的高可用。
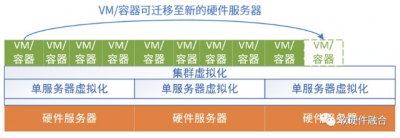
如果我們關注底層軟件和硬件,我們會發現,實際運行的軟件(不考慮虛擬化部分,虛擬化實際上是介於軟件和硬件之間,通過軟硬件協同實現的虛擬化機制)和硬件實際上是完全脫離的: 軟件實體可以在不同的硬件平台上運行,可以實時遷移,上層的軟件以爲軟件實體一直是高可用的,感受不到底層硬件的變化(硬件有可能磁盤故障、死機或者是更新服務器等)。 完整的單個硬件平台通過虛擬化,可以靈活地切分成許多虛擬的硬件平台,可以支持不同的軟件實體運行。
1.2 單服務器的虛擬化、多系統、多租戶,全數據中心多集群系統交叉混合
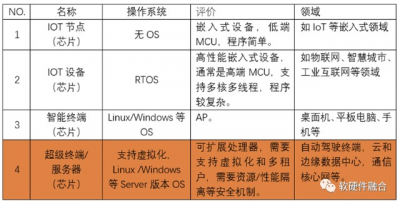
我們之前講過,系統分爲四類,跟智能終端系統相比,雲和邊緣數據中心的系統最大特點是虛擬化和服務化,數據中心服務器和終端設備系統最大的區別在於: 首先,通過虛擬化實現多系統多租戶共存於單個硬件平台。硬件平台需要支持虛擬化和高擴展性,提供多個個性化的虛擬硬件平台。然後需要支持多個不同甚至迥異的軟件系統,運行在各自獨立的虛擬硬件平台上。 另一個,終端系統當做單個系統的話,那么數據中心服務器則是多個系統混合運行。這樣,我們可以把支持虛擬化多系統多租戶運行的服務器運行的系統定義爲宏系統。 單個服務器是多系統多租戶運行的宏系統,那么整個數據中心或多個數據中心連成一體的數以十萬、甚至百萬級服務器組成的超大型集群;其上運行的系統,就完全變成了,不同租戶的多種集群系統混合交叉在一起,並行不悖運行的超大型多宏系統。
1.3 物理硬件的一致性和虛擬“硬件”的多樣性
很多做硬件的同學,不由自主的,會很喜歡搞硬件“創新”。比如: 通過PCIe Switch,連接不同數量不同規格的CPU、GPU以及存儲盤、網卡等I/O設備,組成形態各異的多種類型的硬件服務器; 通過智能網卡、DPU等強大的能力,實現不同規格、不同性能的多計算節點的自由組合; 還有,通過TOR的功能增強,把許多DPU的工作放到TOR交換機,實現Smart TOR或者TOR-DPU的方式,來實現系統能力的增強; 其他各種硬件創新項目。
但我個人一直的觀點是:硬件需要盡可能的簡單,通過軟件去實現各種復雜多樣性。比如,數據中心不宜有不同層次不同規格的服務器和網絡設備,而是極致簡單清晰的就計算節點和網絡核心設備兩種物理設備類型: 計算節點,即服務器,核心功能是計算和各類數據的處理,其網絡功能,盡可能只體現在輸入輸出時的高性能網絡。 交換機,作爲高效的網絡核心設備,專注網絡的相關處理,盡可能少地參與到用戶的計算,保持對用戶計算的透明。 在AWS的官網中介紹Nitro系統優勢的時候,首先提到的就是“更快的創新”: Nitro System 將各種各樣的構建基塊集合,且可按照不同方式進行組合,從而讓我們能夠通過不斷擴展的計算、存儲、內存和網絡選項,靈活設計並快速交付 EC2 雲服務器實例類型。 這項創新還促成了裸機實例,客戶可以在這些實例中使用自己的管理程序或不需要使用任何管理程序。 這句話的意思,我再給大家進一步解釋一下:AWS首先通過Nitro系統可以完全抵消虛擬化的各種軟件开銷,完全實現了虛擬化的硬件加速。然後可以非常方便的把一台服務器的CPU資源、加速器資源、內存資源、I/O資源以及其他各種資源完全的虛擬化,然後就可以隨意的重新組合,然後可以快速而高效的給用戶提供形態各異的虛擬機實例,實例類型如計算優化型、內存優化型、存儲優化型、網絡優化型、GPU/FPGA/DSA加速優化型等。 總結一下,站在雲計算公司的視角,CSP希望的是盡可能簡單的並且自己可以掌控一切的數據中心網絡架構,希望的是盡可能簡單的、一致的服務器硬件規格(這樣,運維才最簡單並且系統的穩定性才最高),然後通過(軟件的)虛擬化機制,實現多種多樣的(軟件)虛擬硬件平台,來支撐VM和容器的運行。
2 數據中心處理器:從合到分,再從分到合
2.1 再來學習一下馮諾依曼架構
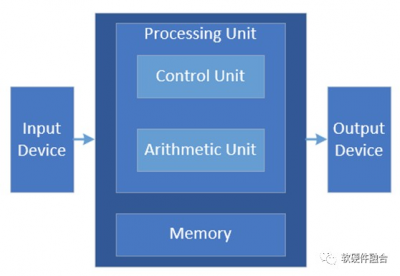
馮諾依曼架構是經典的計算架構,從此架構我們可以得到計算的三個主要的部件:計算單元、存儲單元,以及輸入輸出單元。
2.2 第一階段:CPU單一計算平台
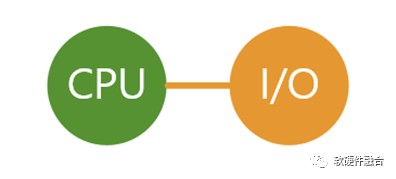
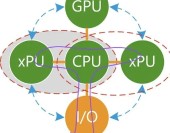
如上圖所示,綠色代表計算單元+存儲單元,這裏的計算單元是CPU。爲了簡化系統分析,我們把存儲單元略去,默認是跟隨計算單元。
2.3 第二階段:從合到分,CPU+其他計算芯片的異構計算平台
基於CPU的摩爾定律失效,CPU的性能提升很慢,每年只有不到3%,要想性能翻倍,需要20年以上。然而,對性能的需求,依然在不斷上升,因此,CPU+xPU的異構計算逐漸走向舞台的中央。
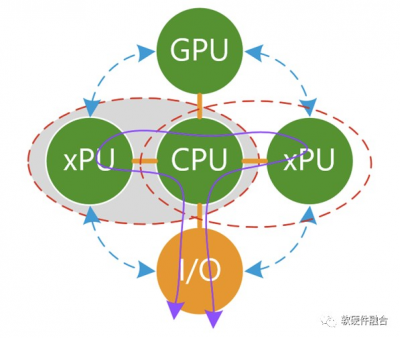
所有的xPU,包括GPU、AI-DSA等加速器無法單獨存在,需要有Host CPU,形成CPU+xPU的異構計算的方式來實現完整的計算。 單個CPU+xPU異構計算本身存在的問題: 可加速部分佔整個系統的比例有限,例如加速佔比爲80%,則加速最高不超過5倍; 數據在CPU和加速器之間來回搬運的影響,加速比率打了折扣,有些場景綜合加速效果不明顯; 異構加速顯式的引入新的實體,計算變成兩個或多個實體顯式的協作完成,增加了整個系統的復雜度; 雖然GPU相比CPU性能提升不少,但是相比DSA/ASIC的性能,還是有顯著的差距;而DSA/ASIC的問題則在於,無法適應復雜場景對業務靈活性的要求,導致大規模應用成爲巨大的門檻; CPU+xPU架構,是以CPU爲中心,整個IO路徑很長,IO成爲性能的瓶頸。 如果把基於CPU+xPU的多個異構計算整合起來,那會存在新的問題: 本質上,每一個CPU+xPU是一個個的孤島,不同xPU之間的通信會非常的麻煩,都需要CPU的參與,非常低效率低性能; 在服務器的物理空間裏,通常只能加載一種類型的加速卡。不存在這么多的空間,可以加載如此多類型和數量的加速卡。站在服務器功耗約束的角度,這么多加速卡也不允許。 以CPU爲中心的架構,所有的xPU交互需要CPU的參與(P2P方式可以減輕一些CPU的壓力,但至少跨越2條總线交互依然是低效的,本質問題沒有解決)。CPU是整個系統的重中之重,隨着CPU的性能提升緩慢,CPU成爲整個系統的瓶頸,拖累了整個系統整體性能的顯著提升。
2.4 第三階段:從分到合的起點:DPU+其他計算芯片的異構計算平台
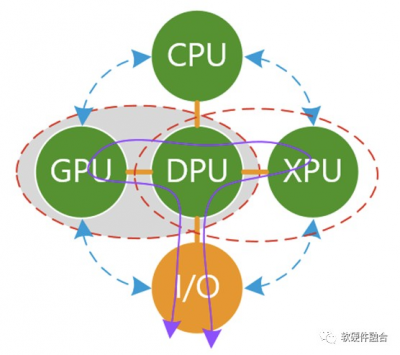
我們再來看看以DPU爲中心的架構。 需要澄清一下:以CPU計算爲中心的架構,本質上是以控制爲中心;以DPU爲中心的架構,也不天然就等同於以數據爲中心;如果DPU的架構實現依然是傳統SOC,那么DPU本質上仍然是以控制爲中心。要想真正實現以數據爲中心,整個系統架構需要做大範圍調整。 我們來看看在以DPU爲中心的多個異構計算的混合狀態下,具體解決了哪些問題?
有一種說法,DPU是一個Switch,它不做具體的功能,只是連接了衆多的PU。那這樣的話,DPU實際上什么事情也沒幹,這樣的DPU沒有意義。 大家對DPU形成共識的看法,DPU需要支持虛擬化、網絡、存儲和安全的加速處理。這樣的話,DPU本身完成了大量I/O數據的計算任務,減輕了CPU的負擔並且顯著的提升了整個系統的性能。 系統“分分合合”,DPU的出現,代表了計算在從分離逐漸走向合並,即把多個CPU+xPU的異構加速逐漸整合成單個處理芯片,實現異構計算的逐步整合。預示着服務器大芯片系統的發展,逐步從單CPU到CPU+xPU異構計算的逐漸分解的階段,走向了把多個CPU+xPU持續整合到一起的逐漸合並的新階段。 DPU沒有解決哪些問題? 計算任務,不僅僅包括I/O類任務處理,還可以是其他系統層,甚至可以是應用層的計算任務。如果把DPU當做綜合性的計算加速平台,DPU可以繼續集成更多的加速功能。 DPU代替CPU,成爲中心節點,“屠龍少年變成了惡龍”,CPU、GPU、其他xPU之間的通信依然很麻煩,依然是一個個孤島。 如果不更新整個系統的底層架構,以DPU爲中心的架構,本質上仍然是以控制爲中心的計算,而不是以數據爲中心的計算,依然無法達到整個數據量和計算量的數量級提升。 依然存在物理空間約束的問題,服務器空間有限,特別是2U或1U的服務器,也需要足夠強勁的算力。而且隨着綠色數據中心的流行,對單台服務器的功耗約束勢必越來越大。這個時候,各自獨立的CPU、GPU以及各類獨立加速器的問題就是亟待解決的。 從以CPU爲中心架構,改成以DPU爲中心的架構。會使得DPU成爲重中之重,成爲系統的關鍵“瓶頸”,成爲系統的不可承受之重。
2.5 第四階段:從分到合:更高效的融合計算平台
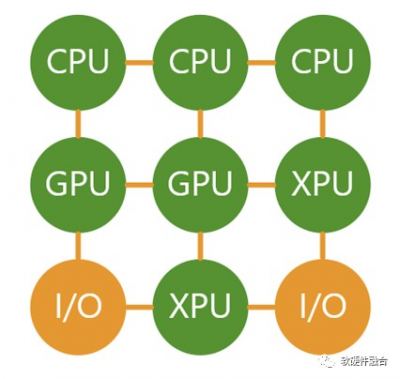
在新的階段裏,沒有所謂的核心節點,把CPU、GPU、DPU(DPU可以看做Multi-XPU的集合),集成到單芯片。這個衆多功能融合的芯片,就是我們一直提到的超異構計算芯片(HPU,Hyper-heterogeneous Processing Unit)。 超異構計算芯片HPU可以認爲是CPU+GPU+DPU的融合型芯片,但不能簡單的看做三者的集成。HPU需要解耦CPU、GPU和DPU的功能,重構整個系統,並且形成以數據爲中心、數據流驅動計算的新型架構。 需要強調的是,超異構融合芯片不能跟超融合的概念混爲一談,超異構芯片不等於雲計算裏經常講的超融合: 超融合是爲了把雲計算IaaS服務的大集群再整合到小規模集群,這樣方便在私有雲和企業雲部署。 而超異構融合芯片則強調系統棧的整體優化,是把服務器上運行的系統整體優化到多種引擎混合的高效高性能的單芯片裏。超異構融合芯片既可以支持超融合,也可以支持不融合(即極致解構並超多用戶超多系統共存)。 我們可以簡單的把系統分爲兩個平面: 控制和管理平面:仍然是運行在CPU的軟件; 計算和數據平面:此刻,CPU、GPU、其他各類xPU,甚至包括I/O都可以看做是平等的各類計算引擎,他們完成各自擅長的工作,並且充分交互,形成一個更加高效更加高性能的的一個整體的系統。
3 大芯片融合的背景條件
3.1 條件1:90%以上的服務器系統相對輕量,單芯片可以容納
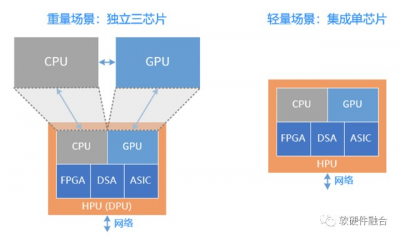
重量級場景,需要獨立的CPU、GPU和DPU三芯片,而輕量級場景則可以有獨立的單芯片融合方案,實現比傳統CPU芯片同等面積下,性能數量級提升的可能,可以覆蓋輕量級系統所需的算力和復雜度。 而輕量級場景所佔的所有服務器的規模也能夠達到90%左右: 邊緣服務器。數據中心包括雲數據中心和邊緣數據中心,據有關數據分析,未來,邊緣計算會佔到整個數據中心規模的80%。 企業級服務器。企業雲場景,需要支持虛擬化,但一般來說不需要支持多租戶。服務器對算力的需求沒有雲那么高。也屬於輕量級場景。 雲數據中心服務器大體分爲兩類,一類是重量級的業務服務器,一類是輕量級的存儲、其他各類資源池化服務器。這些資源池化服務的輕量級場景,都可以由超異構單芯片覆蓋。 此外,獨立的超異構融合芯片,也可以作爲DPU的角色,和CPU、GPU配合來使用。
3.2 條件2:Chiplet技術成熟,使得單芯片可以覆蓋重量級場景
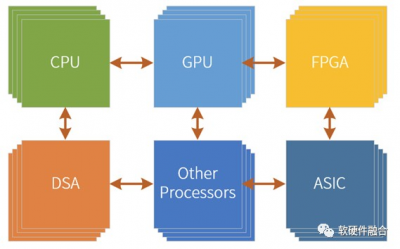 Chiplet技術提供了使系統規模立竿見影快速提升的可能,這樣,我們可以提供一個更大規模的超異構融合芯片,來覆蓋各類重量級計算場景,用在典型的雲計算業務計算服務器和異構計算服務器場景。 從而,使得超異構計算單芯片(單DIE芯片和多DIE組成的Chiplet芯片),可覆蓋雲網邊端融合的所有復雜計算場景(復雜計算的顯著標志爲:虛擬化和服務化)。
Chiplet技術提供了使系統規模立竿見影快速提升的可能,這樣,我們可以提供一個更大規模的超異構融合芯片,來覆蓋各類重量級計算場景,用在典型的雲計算業務計算服務器和異構計算服務器場景。 從而,使得超異構計算單芯片(單DIE芯片和多DIE組成的Chiplet芯片),可覆蓋雲網邊端融合的所有復雜計算場景(復雜計算的顯著標志爲:虛擬化和服務化)。
4 融合,大芯片的發展趨勢
4.1 案例:NVIDIA Bluefield DPU集成GPU
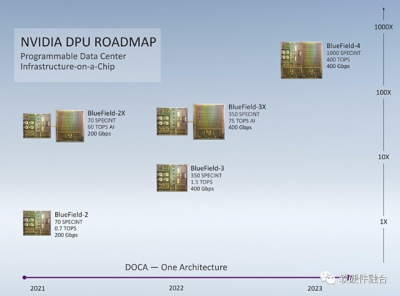
NVIDIA DPU roadmapNVIDIA DPU的Roadmap,NVIDIA計劃從Bluefield第四代开始,把DPU和GPU兩者集成一個單芯片。 NVIDIA DPU和GPU集成了,也已經有了獨立的Grace CPU。那么,在Chiplet技術已經成熟的情況下,再把CPU集成進來,構成CPU+GPU+DPU的超異構芯片,還會遠嗎?(不遠,因爲在自動駕駛端已經有了。)
4.2 案例2:NVIDIA自動駕駛Atlan超異構融合芯片
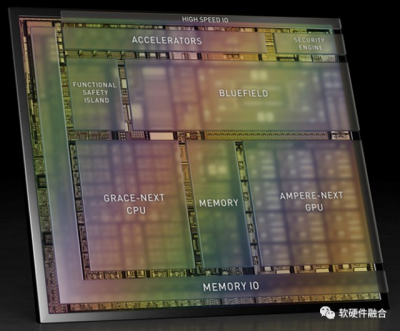
圖 NVIDIA計劃2024年推出的自動駕駛芯片Atlan NVIDIA在自動駕駛領域的芯片發展,也基本上是2年一代產品。2024年要發布的Atlan芯片,則完全變成了集成ARM Neoverse系列的Grace CPU(NVIDIA數據中心CPU)、有可能是Hopper架構的GPU(NVIDIA數據中心GPU)以及Bluefield DPU(NVIDIA數據中心DPU),可以單芯片達到1000 TOPS。 這樣,我們可以看到,在自動駕駛領域,已經實現了多種處理引擎混合的完全的超異構融合芯片,Atlan使用的是數據中心相同的處理引擎架構,可以無縫實現雲邊端協同甚至融合。 從量變到質變,Atlan隨着集成單元的增多,隨着性能需求的上升,隨着系統復雜度的上升而對芯片的通用靈活可編程能力要求上升,都需要全新的架構,全新的整合重構。
*免責聲明:本文由作者原創。文章內容系作者個人觀點,半導體行業觀察轉載僅爲了傳達一種不同的觀點,不代表半導體行業觀察對該觀點贊同或支持,如果有任何異議,歡迎聯系半導體行業觀察。
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:從DPU看大芯片的發展趨勢
地址:https://www.breakthing.com/post/14005.html