




一夜之間,AI大模型熱得發燙。
繼3月中旬,百度最先下場,以“文心一言”搶佔了對標ChatGPT的“國內第一”後,過去一個月,大模型一直是市場的焦點。尤其是在過去一周裏,各界選手紛紛“大幹快上”,密集开“卷”,要么直接卷大模型,要么卷產品卷Demo,要么卷預告卷進展。總之,大模型江湖,徹底火起來了。
百度最先挑起战事,$阿裏巴巴-SW(HK|09988)$、$商湯-W(HK|00020)$跟得最緊、跑得最猛,都已發布類ChatGPT產品。
不止如此,$科大訊飛(SZ002230)$等中大廠的大模型也已經在發布的路上。而適配到具體場景的應用和產品,比如360的“360智腦”已經進行過現場演示,有贊也帶來了由大模型驅動的首個AI產品“加我智能”。就連飛書,也悄悄上线了關於智能助手“My AI”的Demo視頻。
就在去年,AI還因爲商業化困局而被外界詬病。去年年底,OpenAI的ChatGPT問世,成爲了攪動AI大模型江湖的鮎魚,一時間,各類選手紛紛湧了進來。
被視爲是移動互聯網時代第一場大战的“千團大战”,至今仍令人記憶猶新,那時,從業者們的信念是,所有的行業都值得用互聯網再做一遍。時至今日,阿裏巴巴集團董事會主席兼CEO張勇在4月11日已經喊出“所有產品都值得用大模型重做一遍”的口號。盡管當下還處於大模型混战的早期階段,各家的能力更新,都還沒有正式對外开放,對於大廠的大模型能力,還沒有一套成熟的評估體系,但是,AI大模型時代的變革,已經开始酝釀。
市場各種信號都昭示着,“百模大战”的帷幕已經拉开。曾經,硝煙彌漫的“千團大战”,結局是一地雞毛,數千家公司同台競技,只有美團最終跑了出來,無數公司淪爲炮灰。現如今,AI時代的“百模大战”,“入場券”更貴,對於資源、技術、人才的要求更高,也更需要耐心和時間。新選手燒錢燒時間,結果也可能只是巨頭的陪跑。這場持久战,才剛剛开始。

百“模”大战,一觸即發
大模型江湖混战,愈演愈烈,下場的選手越來越多。競爭最激烈也最受關注的,便是在大模型領域有所積累的互聯網巨頭選手們。
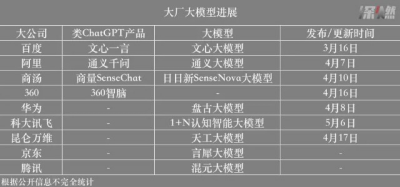
這波混战源起ChatGPT。巨頭選手們的類ChatGPT產品以及最新的AI大語言模型首先受到關注。其中,百度3月16日發布了“文心一言”;阿裏的“通義千問”已從4月7日开始企業內測;商湯科技在4月10日的技術交流會上帶來了“商量SenseChat”,目前還未對外开放;360在3月29日現場演示了“360智腦”後,也將於4月16日开啓企業內測。
這些類ChatGPT產品,主打的都是對話問答、文本及代碼等生成能力,外界常常會把多輪對話、數學能力、編碼能力作爲測評的標准。
業界的共識是,國內這些產品相較ChatGPT,還有一定的差距。但是這些產品,究竟孰強孰弱、孰優孰劣,還難下定論,因爲尚處於內測或演示階段。
不過,各家的產品形態有一定差別。比如,盡管文心一言的生成圖片能力遭到吐槽,但已經實現了多模態交互;通義千問增加了“百寶袋”,把寫提綱、SWOT分析等能力單獨列成板塊以供使用;360則是直接和搜索引擎場景進行了結合。
與類ChatGPT產品共同進入我們視野的,則是各家的大模型體系。
其中,360的大模型,此前市場關注度並不算高。不過,360稱,其人工智能研究院從2020年开始,一直在對包括類ChatGPT在內的大模型通用人工智能技術持續投入。
其余三家中,百度“文心一言”和阿裏的“通義千問”,背後分別是此前已經發布過的文心大模型體系和通義大模型體系;商湯“商量SenseChat”背後是最新問世的“日日新SenseNova”大模型體系。三家本質都是在統一AI底座的基礎上,在通用模型層覆蓋NLP、視覺等領域,再進行行業模型和場景模型的孵化。
深燃制圖
文心大模型除了有文心一言、AI作畫應用文心一格外,還和工業、能源、金融等多個行業客戶共同打造了11個行業大模型。商湯基於大模型體系,還發布了AI內容創作社區平台“秒畫”、AI數字人視頻生成平台“如影”、3D內容生成平台“瓊宇”、“格物”。
接下來,預計最快亮相的選手,當屬科大訊飛。其計劃於5月6日發布“1+N認知智能大模型”,“1”是底座平台,“N”則是應用於多個行業領域的專用大模型版本,同時,“N”個場景的示範性應用產品也將隨之呈現。但是否會有類ChatGPT產品,還不確定。
備受市場期待的選手,還有華爲、騰訊、京東、字節跳動,這幾家雖然沒有大張旗鼓發布基於大語言模型的新產品,但也找機會對外重新梳理大模型體系或透露新進展。
其中,華爲雲首席科學家田奇在4月8日的一場公开活動上表示,華爲盤古大模型在2022年發布NLP大模型、CV大模型和科學計算三個基礎大模型之後,又陸續發布行業大模型系列,包括盤古氣象大模型、藥物分子大模型等等,華爲大模型還是堅定走To B的路线。其內部專家此前就曾指出,“華爲很少在新的趨勢出現後,立馬追上”。
騰訊曾於2022年發布混元大模型體系,據透露,目前也在研發類ChatGPT產品;京東4月對外宣稱,計劃在今年發布新一代產業大模型“言犀”;字節跳動根據公开報道正分別在語言和圖像兩種模態上發力。
當然,市場上也不乏蹭熱點的選手。昆侖萬維的大語言模型“天工”3.5,也將於4月17日开啓內測。4月11日,深交所向昆侖萬維下發關注函,再次提醒不得利用市場熱點題材,進行“蹭熱點”等違法違規行爲。
除了這些大公司之外,根據民生證券相關研報統計,目前國內至少已經有30多家大模型亮相,其中不乏參數規模甚至超過ChatGPT規模的大模型。廠商涵蓋了互聯網巨頭、AI上市公司、服務器龍頭企業、科研院所與一級市場創業公司。
大模型應接不暇,新產品層出不窮,ChatGPT風口上的諸神混战才剛剛开始。

搶發大模型,大廠不能錯過的一战
大廠混战大模型之際,各家的大模型能力究竟幾何,才是最令外界好奇的。以往,大廠選手們做大模型,總是粗暴地拼參數量,業內大模型的參數從百億進化到了千億甚至萬億。
現如今,參數量早已不能當作衡量大模型能力的唯一標准。AI領域從業者章容對深燃表示,大模型的能力或許有學術層面的評估,但依然缺乏較爲成熟的評估標准和體系。
文心一言發布後,百度創始人李彥宏在3月下旬曾對外表示,文心一言不如最新的ChatGPT版本,但是差距不是很大,可能就是一兩個月的差別。就連剛剛下場成立AI公司“百川智能”的搜狗創始人王小川也對外表示,正在研發大模型產品,今年內可能就能追上ChatGPT3.5的水平,至於趕上GPT-4或者GPT-5,可能需要3年左右的時間。
現如今,業界衡量大模型能力最直接的標准,似乎變成了和ChatGPT相比差距有多大,多久能追上,但也只能是模糊對比。
雖然如何評價大模型的實力還沒有統一標准。但是,大廠們已經开始展望大模型進入到業務應用層能帶來的變革。從目前選手們的參與思路來看,百度、阿裏都已經宣布未來主流業務,將與最新的大語言模型深度結合。
在文心一言發布前,李彥宏在內部信中就曾介紹,百度計劃將搜索、智能雲、自動駕駛多項主力業務與文心一言整合。4月11日的阿裏雲峰會上,張勇也表示,阿裏巴巴所有產品,包括天貓、釘釘、高德地圖、淘寶、優酷、盒馬等,未來都將接入“通義千問”大模型進行改造。目前釘釘和天貓精靈已經接入測試,新功能將在評估之後發布。
大廠主流業務的改造正在酝釀或進行。而大廠掌握着更多的場景和數據,也能反哺大模型的發展。
在雲計算領域,2022年,以天翼雲爲代表的運營商雲加速崛起,而以阿裏、騰訊爲代表的互聯網大廠雲計算業務增速放緩,大廠雲需要找到新的增長驅動力,張勇甚至下場擔任阿裏雲事業部的一把手。

顯然,大模型正在扮演這樣的角色。百度、阿裏、華爲,都是雲事業部來做大模型to B、to G的對外服務,雲計算市場頭部四朵雲已經集齊三朵。在大模型時代,正如李彥宏所言,雲計算市場的遊戲規則正在發生根本性變化。
企業協同辦公市場中,疫情以來,釘釘、飛書、企業微信三足鼎立的格局基本形成。而釘釘在4月11日展示了接入“通義千問”的Demo之後,飛書在當天下午也緊急發布了智能助手“My AI”的Demo視頻。就如同微軟Office 365的Copilot產品,釘釘和飛書的Demo,都或將幫助職場人在工作效率方面實現大幅提升。現在,壓力給到了企業微信。
在搜索領域佔市場六成份額的百度,要讓文心一言改造搜索體驗。佔據搜索市場三成份額的360緊隨其後演示360智腦,被外界認爲是,开啓了搜索市場爭奪战。
同樣,商湯、科大訊飛這些曾經的AI大廠,見證了從機器學習到AI大模型時代的變遷,現如今,更是不愿錯過大模型的風口。
擁抱大模型,就是擁抱下一個時代。大模型內卷之際,結合場景,基於大模型的產品依然在層出不窮。比如有贊接入GPT-4,上线了“加我智能”。同花順的AI產品將在4月14日上线,但是否會在其i問財產品的基礎上有所創新,還未可知。

“讓子彈先飛半年”
“大廠們都是先來佔位!”章容稱,“因爲大模型的能力還遠未成熟落地,現在互聯網大廠更像是在秀肌肉”。
一位即將進行AIGC創業的AI從業者告訴深燃,大模型就像是AI時代的操作系統,大廠搶先佔位,不排除是爲了搶客戶、搶人才。畢竟,大佬們下場官宣創業,往往伴隨着招人。
但更值得注意的是,大模型的能力越強,API可以實現的應用端場景就越豐富,相當於大廠都在爭AI時代的“App Store”。
大模型並非一朝一夕就能夠煉造的,現如今大廠選手大模型動態層出不窮,本質還是過去幾年技術積累的產物。
做大模型,必然伴隨着重投入。在國外,微軟投資OpenAI,先後投資了超100億美元,而OpenAI對於GPT-3的訓練費用已經超過1200萬美元。這一點,從國內大廠的研發投入也可窺一斑。
財報顯示,2022年百度的核心研發費用爲214.16億元,佔百度核心收入比例達到22.4%。過去10年,百度研發投入超1000億元。根據商湯財報,過去四年,商湯總營收爲149.8億元,而研發开支則達到了114.3億元,營收佔比達到76.3%。

或許也是因爲如此重的投入,對於大模型領域內卷加劇,業界出現一種討論,國外已經跑出了GPT-4,面對如此大的差距,國內新選手現在殺入战場做大模型,意義大不大,會不會造成人才和資源的浪費。
2023年以來,多位大佬宣布下場進行大模型創業,但是一部分人的思路已經开始調整。出門問問創始人李志飛最近多次對外表示,做大模型不能過於樂觀,貿然進入難度很大,而且競爭激烈。他的思路已經從开始的做通用型大模型,轉向更注重結合自身業務場景,做垂直整合大模型。
他認爲,國內在1-2年之後,將會有50家以上的公司擁有自己的大模型。包括互聯網大廠自研、中型互聯網公司基於开源大模型微調、一些AI公司及垂直領域的甲方,都會有大模型,市場大模型的供給一定不會太少。
也有很多業界人士認爲,未來大模型的發展,將會是頭部幾家寡頭之間的競爭。
但是,中國必須做自己的大模型,已是共識。出現分歧,本質上還是因爲,大模型的鏖战才剛剛开始。
民生證券相關研報指出,目前表面上大模型百花齊放,不再稀缺,是因爲开源基礎以及大公司本身的算力儲備與資金實力,單純發布一個大模型門檻,沒有市場想象那么高。但是能夠擁有高質量數據場景,才能持續迭代,性能逐步逼近ChatGPT的大模型,預計最終仍是“鳳毛麟角”。市場會逐步凝結共識:得數據者得天下,數據成爲大模型差異化競爭的關鍵。
算力、算法、數據是AI大模型研發的三大要素。大廠雲們在算力上擁有一定優勢。AI領域從業者貝科對深燃表示,華爲布局昇騰芯片、昇騰生態已經多年,而且在各地也投資了算力中心,現如今也已經有了一定量的算力儲備。阿裏整個集團在GPU算力上也有一定儲備。但這並不意味着大模型能力一定能持續攀升。
章容認爲,大模型將帶來生產力的變革,已經是毋庸置疑的事實,但是,即便是國外跑得最快的OpenAI以及微軟,目前在商業化落地上已經有所進展,但也依然不能說成熟穩定。至於國內大廠的大模型,目前更是還處於非常早期的階段。
一方面,生成式人工智能的信息安全問題已經顯現。4月11日,國家互聯網信息辦公室發布了《生成式人工智能服務管理辦法(徵求意見稿)》,強調了生成內容的真實性,並且提出了相應的容錯率和懲罰措施。
另一方面,當前國內市場上最新的大模型產品,無論是面向C端的體驗產品,還是面向企業的接口,基本都處於內測階段,還沒有真正放开。
按照目前的形勢,章容認爲,當前大模型從發布走向到企業端,摸索如何真正提升生產力,至少需要半年的時間。#全球AI監管潮來襲,行情將如何演繹?#
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:“百模大战”,來了
地址:https://www.breakthing.com/post/52725.html