




三年來,Tachyum 一直在吹捧其 Prodigy 通用處理器 ,並承諾它會比 AMD、英特爾和 Nvidia 等公司的 CPU 和 GPU 更好。然而,盡管該芯片最初預計將於 2021 年全面量產,但它仍未投入生產。現在看來該公司正在展望未來並宣傳其基於 Prodigy 2 的超級計算機設計 ,該設計承諾在 2025 年至 2026 年達到 20 ExaFLOPS 的性能。
該公司表示, Tachyum 的 超級計算機設計旨在 2025 年在 60MW 的功率目標內提供 20 FP64 矢量 ExaFLOPS 和 10 AI(INT8 或 FP8)ZetaFLOPS 性能,佔地面積爲 6,000 平方英尺。該機器將使用 64 個基於 Prodigy 2 的機櫃和 16 個存儲架,但 Tachyum 確定了它需要多少 Prodigy 2 處理器才能提供如此高的性能。
Tachyum 還表示,它可以構建一台超級計算機,提供 24.9 FP64 矢量 ExaFLOPS 和 13.27 AI ZettaFLOPS 消耗 73.8MW。爲了說明這個數字,即將推出的由 AMD 的 Instinct MI300 數據中心 APU 提供支持的 El Capitan 超級計算機將提供大約 2 FP64 ExaFLOPS。
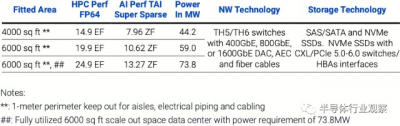
去年,美國能源部表示有興趣在 2025 年前採購一台功耗爲 20MW-60MW 的 20 ExaFLOPS 超級計算機。Tachyum 表示已提交了在 2025 年前構建這樣一個系統的提案 ,但沒有詳細說明細節。由於該公司最初的 Prodigy 沒有達到 Tachyum 的性能目標(這就是它起訴 Cadence 的原因),因此有理由假設該公司將在機器上使用其第二代 Prodigy(該公司之前曾討論過)。
Tachyum 本周公布的這款超級計算機設計基本上符合美國能源部的要求,但該公司並未透露其 Prodigy 2 的預期性能水平。
Tachyum 表示其 Prodigy 處理器是有史以來第一款可以處理各種要求苛刻的計算工作負載的通用處理器。原始的 Prodigy 處理器包含 128 個專有的 64 位 VLIW 內核,每個內核具有兩個 1024 位矢量單元和一個 4096 位矩陣單元。旗艦 Prodigy T16128-AIX 處理器預計將爲高性能計算 (HPC) 提供最多 90 FP64 teraflops,並爲 AI 推理和訓練提供最多 12 個“AI petaflops”(具有 INT8 或 FP8 精度)。此外,每個芯片的功耗預計高達 950W,並採用液體冷卻。
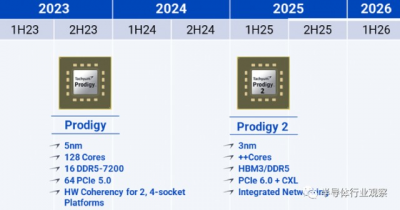
Tachyum 的 Prodigy 2 有望增加核心數量,並增加 HBM3、PCIe 6.0 + CXL 和集成網絡功能。
“Tachyum 提供從硅到完整系統的領先解決方案,以滿足對 HPC 和 AI 不斷增長的需求,”Tachyum 創始人兼首席執行官 Radoslav Danilak 說。“Tachyum 設計的超級計算機將 HPC 性能推向前沿,同時跨越人工智能的 zetta 級壁壘,將數據中心轉變爲通用計算中心。”
一個號稱“萬能”的CPU架構
爲數衆多的半導體初創公司希望打入市場,它們要么擁有一些大型 AI 訓練芯片,要么擁有一些超快速的小型推理設備,或者可能是針對一個特定問題的 HPC 專注設計。一些公司資金充裕,其中不乏融資超過1億美元的公司,還有一些資金支持超過10億美元。在本文中,我們着眼於 Tachyum,這是一家美國/歐盟芯片初創公司,它於2018 年首次出現在我們的視野中,其高性能、高頻率的處理器設計令人驚嘆,涵蓋了諸多細分市場。在 2022 年的今天,他們已經修改了早期的設計,總而言之,它看起來更像是一個可以真正打破常規的計算架構。
我們所要討論的是擁有 128 核、每核 21024 位向量、5.7 GHz、1 TB/秒的 DRAM的龐然大物。有人說我們的數據中心的熱余量用完了,這顯然是錯誤的,Tachyum 證明了這一點。在本文中,我們將介紹新設計與舊設計的比較,以及我們可以從 Tachyum 的披露中收集到哪些信息。
Tachyum Prodigy 2022
今天,Tachyum 仍然稱他們的架構爲“Prodigy”。但他們已經根據客戶的反饋對其進行了徹底改革。VLIW 捆綁包被更傳統的 ISA 取代, 硬件調度功能更強大,提高了每個時鐘的性能。緩存層次結構也發生了重大變化。2022 Prodigy 的變化足夠廣泛,以至於對 2018 年 Prodigy 所做的大部分分析都不再適用。
在高層次上,2022 Prodigy 仍然是一個非常廣泛的架構,具有巨大的向量單元:
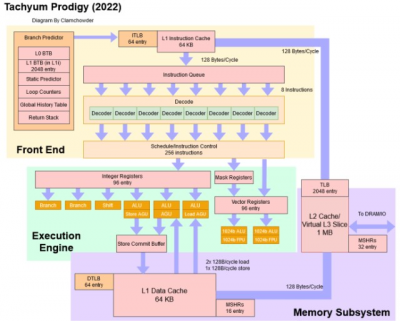
與 2018 Prodigy 一樣,2022 Prodigy 的目標是極高的時鐘速度和高內核數。事實上,這些目標已經被提高了,時鐘速度從 4 GHz 提高到 5.7 GHz,內核數從 64 增加到 128。本文中我們將更深入地了解細節。
再見捆綁包,你好 Sane ISA
Tachyum 最初試圖通過將指令集與底層硬件實現緊密聯系來簡化 CPU 設計。VLIW 包允許非常簡單的解碼和映射邏輯。編譯器協助調度,它會設置“停止位”來標記可以並行發布的指令組。這種方案表面上類似於 Nvidia 在 Kepler 和後來的 GPU 架構中使用靜態調度,並讓內核跳過硬件中的依賴檢查。
但是將 ISA 綁定到硬件會產生前向兼容性問題。例如,如果新架構具有不同的指令延遲,則必須設置不同的停止位。Tachyum 的潛在客戶不會接受產品世代之間的 ISA 更改。在實踐中,像將 ARM 支持添加到復雜的軟件項目這樣“簡單”的事情可能需要 18 個月以上的時間。支持新的 ISA 必須是一次性投資,而不是每次 CPU 升級都會重復的投資。
最新的 Prodigy 架構通過放棄原來的 VLIW 方案轉而採用更傳統的 ISA 來解決這個問題。指令有四個或八個字節長。編碼不再包含“停止位”,這意味着現在Prodigy 在硬件中進行依賴性檢查,而不是依賴硬件來標記獨立指令組。
前端和分支預測
盡管放棄了 VLIW 設置,Prodigy 仍然可以維持每個周期 8 條指令——對於目標爲 5.7 GHz 的 CPU 來說,這是一項了不起的成就。根據 Rado所說,這個內核寬度對於在 AI 和 HPC 負載中實現最大性能是必要的。在整數工作負載中,4 寬的內核就足夠了,而增加到 8 寬的內核只會將性能提高 7-8%。但是,AI 或 HPC 程序中的一次循環迭代可能會執行兩條向量指令、兩次加載、遞增循環計數器並有條件地分支。將內核寬度提高到 8 寬將使 Prodigy 在每個周期完成一個循環迭代。
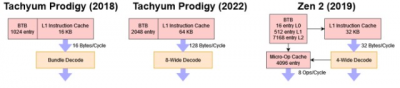
爲了保持這種量,Prodigy 可以從 L1 指令高速緩存中提取每個周期128 字節。考慮到 64 個字節足以包含 8 條指令,這絕對是大材小用。Tachyum 可能選擇了更多的獲取帶寬,以在所佔用的分支周圍保持高量。Prodigy 沒有大的 L0 BTB,因此與 Zen 3 和 Golden Cove 相比,它可能會在所採用的分支周圍遇到更多的指令獲取停頓問題。通過一次獲取 128B 字節,前端可以在 BTB 延遲丟失一個周期後“趕上”。
Prodigy 的分支預測器也得到了改進。BTB容量翻倍至2048條,預測算法是2018 Prodigy中gshare one的改進版。但總的來說,Prodigy 的預測器與最新的 AMD、ARM 和 Intel 高性能內核中的預測器不同。AMD 的 Zen 3 有一個 6656 入口的主 BTB。ARM 的 Neoverse V1 擁有 8192 個 BTB 入口,而英特爾的 Golden Cove 擁有令人難以置信的 12K 入口 BTB。BTB 容量並不是唯一的缺點。Prodigy 繼續使用綁定到指令緩存的 BTB。這簡化了設計,因爲無需進行單獨的 BTB 查找——L1i 查找爲您提供指令字節和分支目標。AMD 的 Athlon 也做了類似的事情,ARM 在 2010 年代中期使用了這個方案。但是來自 AMD、ARM 和 Intel 的現代內核已經轉移到解耦 BTB,允許它們在代碼佔用量超過 L1i 容量時保持高指令帶寬。對於耦合的 BTB,L1i 未命中意味着 BTB 未命中。並且不知道下一個分支將去哪裏,這大大降低了在指令緩存未命中後您可以有效預取的距離。但是 Tachyum 正在使用標准單元庫,並以非常高的時鐘速度爲目標,而使用這些標准單元庫的解耦 BTB 被認爲過於昂貴。
爲了解決這個問題,Tachyum 將 L1i 容量增加到 64 KB,是 2018 年 Prodigy 的四倍,以確保 L1i 失誤減少。Rado 指出,specint2017 中的 64 KB L1i 未命中率低於 0.5%。我們對 Ampere Altra 的 64 KB L1i 的觀察大致一致。更大的 L1i 還有助於提高電源效率,並最大限度地減少與 L2 帶寬上的數據端的爭用。
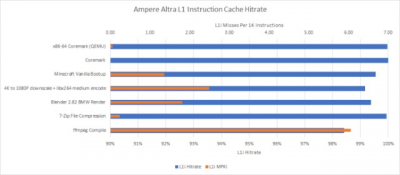
ARM 採用了更大的 64 KB L1i 高速緩存,效果極佳,並且 L1i 未命中率低。
2022 Prodigy 還繼續依賴於相當過時和基本的 gshare 預測算法,而現代 CPU則使用更復雜的技術,可以在給定的存儲預算下實現更好的預測精度。Tachyum 考慮構建更高級的分支預測器,但同樣,標准單元庫意味着實現 TAGE 預測器會過多地降低時鐘速度。由於高時鐘速度要求,除了感知器預測器 - 您可以想象在一個時鐘周期內匯總一批權重需要做很多事情。包含本地歷史的方案也不可行,因爲高獲取帶寬意味着每個周期必須執行多個預測。具有本地歷史的多個預測將需要每個周期進行多次歷史表查找。因此,Tachyum 堅持使用基於全局歷史的預測器,並且每塊 8 條指令進行預測。這使分支預測器保持簡單,同時讓它跟上 Prodigy 內核寬度所需的預測帶寬。

英特爾的 Rocket Lake 內核,帶有分支預測器存儲和其他前端緩存標記。圖片來自 Fritzchens Fritz,Clam 注釋
Rado 提到 Prodigy 的未來版本可以使用自定義單元,這將讓他們考慮更高級的分支預測器,同時仍然以非常高的時鐘速度爲目標。相比之下,英特爾似乎在分支預測器中使用了在內核其他地方看不到的自定義 SRAM 單元。AMD 採用了不同的方法,將相同的 SRAM 單元用於分支預測器存儲、L1 指令緩存和微操作緩存。

AMD 的 Zen 3 內核,帶有分支預測器存儲和其他標記的前端緩存。圖片來自 Fritzchens Fritz,Clam 注釋
Zen 3 展示了可以使用標准單元構建最先進的分支預測器,盡管可能不是 Prodigy 的目標 5.7 GHz 速度。
後端:巨大的向量單元和完整的 OoO?
如果你不能有效使用它,那么建立一個巨大的內核並沒有多大意義。爲此,Tachyum 放棄了他們 2018 年的設計,並在硬件中實現了深度重新排序功能。2022 Prodigy 可以跟蹤多達 256 條正在運行的指令,其中整數寄存器有 96 個重命名,向量寄存器也有同樣多的重命名。它可以重新排序過去的各種依賴項。根據 Tachyum 的描述,Prodigy 可以像 AMD、ARM 和 Intel 的內核一樣完全亂序執行。但不是使用更傳統的無序引擎,而是使用檢查點方案。對於可能導致異常的指令,例如未命中緩存的加載,Prodigy 會保存帶有寄存器狀態的檢查點。如果該指令確實導致異常,則該檢查點用於提供精確的異常處理。2022 Prodigy 可以保存多個檢查點,而2018 Prodigy只能保存一個檢查點。這是一個重大改進,就執行單元而言,Tachyum 爲 2022 Prodigy 配備了兩個巨大的 1024 位向量單元,並增加了向量寄存器寬度以匹配。因此,2022 Prodigy 的矢量寬度是 2018 Prodigy 的兩倍,並且矢量量比當今任何通用 CPU 都要高。甚至英特爾的 Golden Cove 也只有兩個 512 位向量單元。
緩存子系統
在重新設計 Prodigy 架構以在硬件中進行更多重新排序,從而使其能夠爲 AI/HPC 應用程序保證更多帶寬後,Tachyum 面臨着保持這些內核輸入的挑战,同時,提供以高速時鐘運行的 1024 位向量單元也是一項艱巨的挑战。首先,L1D 數據路徑的寬度增加了一倍,以匹配向量長度的增加。在 5.7 GHz 時,Tachyum 內核可以從其 L1D 以接近 1.5 TB/s 的速度加載數據。L2 可以在每個周期向 L1D 提供完整的 128B 高速緩存行,帶寬約爲 730 GB/s。相比之下,英特爾的 L1D 和 L2 緩存的每周期負載帶寬是 Prodigy 的一半,AMD 則更落後。Zen 2 和 Zen 3 在 L1 和 L2 的每周期帶寬是英特爾的一半。當然,Prodigy 的時鐘頻率高於 Intel 或 AMD 當前的 CPU,因此具有巨大的緩存帶寬優勢。
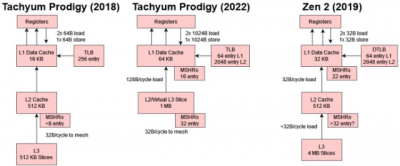
Zen 2 似乎能夠通過在未記錄的性能計數器上使用計數屏蔽來跟蹤至少 32 個未決的 L2 未命中。
爲了維持高帶寬和隱藏延遲,2022 Prodigy 改進了內存級並行性 (MLP)。具體來說:

這是對 2018 版本的重大改進,在 2018 版本中,可實現的 L3 帶寬和內存將受到其低 MLP 的限制。它與 Zen 3 和 Golden Cove 位於同一個塊,但從絕對意義上來說可能會稍遜一籌。
2022 Prodigy 還增加了緩存容量,以更好地處理具有大內存佔用的負載。L1 數據緩存的容量翻了兩番,從 16 KB 增加到 64 KB。與 2018 Prodigy 相比,每核 L2 和 L3 緩存容量沒有增加,但 2022 Prodigy 放棄了單獨的 L2 和 L3 布局,轉而採用虛擬 L3 設置。空闲內核將允許活動內核將其 L2 用作虛擬 L3,從而提高低线程負載的緩存命中率。當一個內核從它的 L2 驅逐一條线時,它會檢查周圍的內核,看看它們的 L2 是否可以接受被驅逐的线,只有屬於非活動內核的 L2 緩存才會接受這些請求。
對我們來說,這個設置一點也不簡單,並且圍繞這個虛擬 L3 的實現方式會有很多調整。聽起來一個物理內存地址可以緩存在多個虛擬 L3 切片中,具體取決於哪些對應的內核處於空闲狀態,更多的切片檢查意味着更多的互連流量。Tachyum 還希望將數據盡可能靠近所佔用的內核,而可能的位置越少意味着這方面的靈活性越低。與 Intel、AMD 和 ARM 使用的更簡單的方案相比,正確設置這個虛擬 L3 聽起來像是多維優化問題。
地址轉換性能也很重要,因此 Tachyum 將最後一級 TLB 大小從 256 增加到 2048 個條目。在條目數方面,它與 Zen 2、Zen 3 和 Golden Cove 相匹配。爲了進一步提高 TLB 覆蓋率,Prodigy 確實以 64 KB 的頁面大小和 32 MB 的大頁面來處理更大粒度的任務。2048 個條目的 L2 TLB 將覆蓋 128 MB 和 64 KB 頁面。ARM 和 x86 主要使用 4 KB 頁面以及 2 MB 大頁面用於客戶端應用程序。較大的頁面大小往往會浪費更多的內存,但這對於通常具有數百 GB DRAM 的服務器來說並不是什么大問題。
內存帶寬
對於不適合緩存的工作負載,DRAM 帶寬可能是個問題。正如我們之前提到的,Prodigy 的計算與內存帶寬比高於當前的 CPU 和 GPU。起初,Tachyum 試圖通過實現封裝 HBM 來解決這個問題。但 HBM 的容量非常低,這意味着如果 Tachyum 想要佔領服務器市場,它並不是一個可行的選擇。HBM 解決方案對於 HPC 和 AI 應用程序來說是可以接受的,但 Rado 指出,Nvidia 已經擁有該市場的大部分份額,而與服務器市場相比,剩下的市場很小。保留兩種內存選項是不可行的,因爲芯片上沒有足夠的邊緣空間來容納 DDR 和 HBM 控制器。
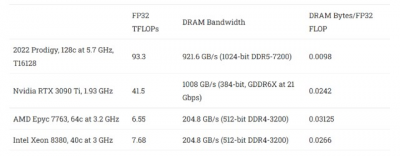
因此,Tachyum 選擇了一個非常強大的 DDR5-7200 設置,帶有 16 個控制器,總內存總线寬度爲 1024 位。這使它的帶寬與 Nvidia 的 RTX 3090 GPU 差不多。DDR5-7200 今天還不存在,但 Tachyum 預計只有 AI 和 HPC 客戶才需要性能最高的內存設置。這些客戶通常會購买整個系統而不是組件,從而允許集成商對可達到 7200 MT/s 的內存模塊進行封裝。服務器應用程序通常不受帶寬限制,並且可以使用速度較慢的 DDR5。
但即使使用 DDR5-7200,Prodigy 的海量矢量單元和高時鐘意味着它比其他 CPU 和 GPU 具有更低的帶寬與計算比。Tachyum 希望通過使用內存壓縮來縮小這一差距,這有點像 GPU 如何進行增量顏色壓縮以降低帶寬需求。但與 GPU 不同的是,Tachyum 正在爲 AI 和 HPC 應用程序調整內存壓縮算法。最後,Tachyum 以更大的粒度進行 ECC,允許內存控制器使用一些 ECC 线路來代替傳輸數據。
提高仿真性能
Tachyum 的 Prodigy 引入了新的 ISA,因此不會像 x86 和 ARM 那樣享有強大的軟件生態系統。這是一個嚴重的問題,因爲如果世界上最好的芯片不能運行用戶需要的軟件,它就完全一文不值。爲了解決這個問題,Tachyum 正在尋找 QEMU,它可以模擬另一種架構並允許 x86 和 ARM 二進制文件在 Prodigy 上執行。但僅 QEMU 是不夠的,因爲仿真性能通常很差。例如,我們在 Ampere Altra 上運行 QEMU 下爲 x86-64 編譯的 CoreMark。
爲了提高 x86 二進制文件的仿真性能,Prodigy 可以切換到“嚴格”內存排序模式。Tachyum 也在 QEMU 中完成了軟件工作以提高性能。就絕對值而言,30-40% 的性能損失仍然很嚴重。但是運行所需的軟件比絕對性能更重要,如果芯片不能運行所需的軟件,那么世界上所有的性能都是無關緊要的,因此 Tachyum 已經在 QEMU 中投入了大量精力,以確保硬件至少在發布時可用。
評估架構
Tachyum 對 Prodigy 進行了大量修改,因此2018 和 2022 版本基本上是不同的架構。總結主要的管道變化如下:
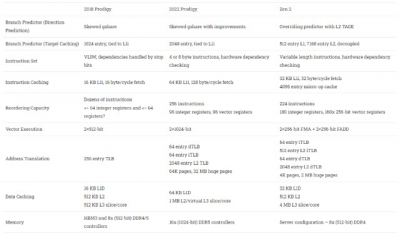
2022 Prodigy 的變化使其成爲比 2018 Hot Chips 上展示的版本更具競爭力的架構。Prodigy 不再嚴重依賴編譯器,採用傳統的 ISA,並具有不錯的硬件重新排序功能,這些是我們對 2018 版本最大的擔憂,我們很高興看到它們得到解決。2018 版本中的其他弱點,如微小的 L1 緩存,也得到了糾正。這給我們留下了一個帶有巨大矢量單元的寬內核,以針對高內核數芯片的前所未聞的時鐘。
對於 HPC 和 AI,我預計 Prodigy 將極具競爭力。它具有足夠的重新排序深度和內存級別的並行能力,可以充分利用內存帶寬。雖然它的內存帶寬與計算比率低於競爭解決方案,但 Prodigy 確實有很多技巧可以緩解這種情況。即使沒有這些技巧,Prodigy 仍然擁有比 AMD 的Milan 或者 Genoa更強大的 DRAM 子系統。富士通的 A64FX 確實具有相當的 DRAM 帶寬,但它使用 HBM,這極大地限制了它的內存容量。
服務器市場是一個更難的問題。Prodigy 擁有不錯的大型 L1 緩存、不錯的重新排序能力、非常高的時鐘速度和高核心數。但是它的分支預測器遠遠不是最先進的,每個核心的最後一級緩存容量很低(尤其是與 AMD 相比)。更糟糕的是,過渡到新的 ISA 對任何大公司來說都是一件頭疼的事情。不過,我認爲 Prodigy 有一個不錯的機會,因爲它的時鐘速度優勢是如此之大,不僅可以掩蓋它的缺點,更可以讓它在核心數量和單核性能方面都比其他所有人的服務器產品都具有優勢。Tachyum 可以說服人們使用他們的新 ISA 和羽翼未豐的軟件生態系統,以便利用 Prodigy 的高性能。
如果 Prodigy 快要實現其雄心勃勃的(高速)時鐘目標,它確實很有可能成爲“通用處理器”,至少在紙面上是這樣。它將類似於 GPU 的矢量量與 CPU 的單线程性能相結合。代價是極高的功耗。128 核 Prodigy 在加載矢量單元的情況下可以達到近 950W 的功率。即使是 32 核、3.2 GHz 低功耗 SKU 也被指定爲 180W——並不比基於 Zen 2 的 Epyc 7502P 好,後者盡管使用了小芯片設置和較差的工藝節點,但它以類似的 180W TDP 提升到 3.35 GHz。在服務器中,整型計算不太可能使 Prodigy 消耗 TDP 數據所顯示的那么多功率。但是高 TDP 等級仍然是一個問題,因爲冷卻系統必須針對最壞的情況進行設計。
關於 5.7 GHz
就個人而言,我懷疑 Prodigy 能否實現其 5.7 GHz 時鐘目標。Tachyum 正在採用一些策略來幫助在高時鐘下控制功率和面積。我們目前無法確切透露那是什么,但我認爲這還不夠。將兩個 1024 位向量單元推送到這些時鐘將是一項令人難以置信的壯舉。流水线長度看起來太短了。在2018年, Prodigy 有一個從取指令到執行指令的 9 階段整型流水线。在2022年 Prodigy 增加了一個用於硬件依賴檢查的階段,使整型流水线達到 10 個階段。對於以 5.7 GHz 爲目標的設計來說,這非常短。作爲比較,Agner Fog 指出,在英特爾的 Golden Cove 上,錯誤預測懲罰(對應於流水线長度)超過 20 個周期。AMD 的優化手冊稱 Zen 3 的誤判懲罰範圍爲 11-18 個周期,常見情況爲 13 個周期。流水线長度與 Prodigy 相似的 CPU 無法達到 5 GHz。Neoverse N1 有 11 級流水线,運行頻率不高於 3.3 GHz。AMD 的 Phenom 有 12 個周期的錯誤預測懲罰,運行頻率爲 3.7 GHz。

如果我們就 Tachyum 的芯片圖而言,假設它佔據 500 mm2,單個 Prodigy 內核的空間遠低於 3 mm2,從而引發熱點問題。
發熱問題也須考慮。AMD 的 Zen 3 的時鐘頻率可以超過 5 GHz,但在低线程負載下面臨冷卻挑战,因爲它們的低核心面積意味着非常高的熱密度。Tachyum 預計 Prodigy 將佔據不到 500 平方毫米的空間。Tachyum 發布的模具平面圖效果圖表明,每個核心的尺寸小於 3 mm2。Zen 3 核心的面積約爲 3.78 平方毫米,包括 L2。Prodigy 核心在某些領域可能不那么復雜,例如分支預測器,但在其他領域(例如向量單元)也更復雜。我認爲當核心被推到 5.7 GHz 時很可能會出現熱點問題。
最後一點,考慮策略實用性的一種方法是查看其他公司採用相同策略的頻率。如果對於一家小型初創公司來說,採用 5 GHz 以上的 1024 位矢量單元的 8 位寬內核是可以實現的,那么 AMD、ARM 和英特爾在過去十年中肯定一直在偷懶。哦,把 Nvidia 也算上——他們的 Kepler、Maxwell 和 Pascal 架構有 32 位寬的 FP32 ALU,基本上是 1024 位。或者,要讓一個廣泛的架構達到如此高的時鐘頻率真的很難,而且小型初創公司不太可能做到這一點。我並不是說 Prodigy 不可能達到 5.7 GHz,因爲 AMD 的 Zen 4 顯然達到了 5.85 GHz。也許台積電的 5nm 工藝就是這么神奇。但是通過巨大的矢量單元、高核心數和相對較短的流水线來實現這種時鐘速度看起來像是一座太遠的橋梁。因此,讓我們看看如果 Prodigy 未能達到其時鐘目標,它的競爭力將如何。
HPC and AI
即使沒有高時鐘,Prodigy 也有大量的量,這要歸功於巨大的矢量單元。即使在 3 GHz 下,它的浮點數處理能力也穩居 GPU 領域。與之競爭的 CPU 甚至不在同一個層次。
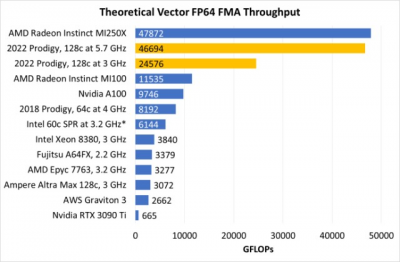
*假設 Golden Cove 在 Sapphire Rapids 中有 2512 位向量單元
有趣的是,以較低的時鐘運行還爲 Prodigy 提供了更平衡的計算量與內存帶寬的比率。在 5.7 GHz 時,Prodigy 需要一些技巧來減少內存帶寬瓶頸。在 3 GHz 時,相對於其內存帶寬,它的計算量仍然很大。但比例不那么不平衡。
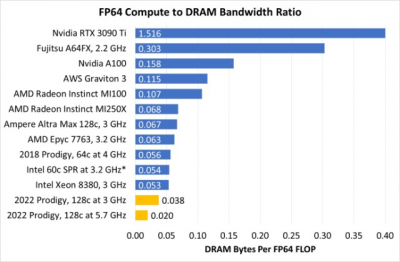
*假設 SPR 使用 DDR5-5200
其他 CPU 每個 FLOP 的帶寬更高,但這主要是因爲它們的量要低得多。GPU(和 A64FX)將其有利的帶寬與計算比率歸功於容量有限的緊密集成的內存子系統。與其他服務器芯片一樣,Prodigy 可以配備數百 GB 的 DRAM。GPU 通常不能。
因此,Prodigy 很有可能成爲具有競爭力的 HPC 或 AI 芯片,即使它實現不了它的時鐘目標。除非出現重大缺陷,否則受量限制的 HPC 和 AI 應用程序可以從 Prodigy 的矢量單元中受益。Prodigy 最大的弱點,比如軟件生態系統就顯得不那么重要,因爲研究人員和 AI 人員通常开發專門的系統。HPC 和 AI 代碼也應該足夠規則,以至於 Prodigy 較弱的分支預測器不會阻止它。
Server
服務器工作負載更復雜。與競爭服務器芯片相比,Prodigy 具有較弱的分支預測器和較低的緩存緩存容量。如果沒有高時鐘,Prodigy 的單核性能可能難以與之競爭。這不一定是一個大問題——ARM 進入服務器領域表明,即使每核性能沒有競爭力,高核數芯片仍有空間(當然它必須足夠好用才行)。
但ARM在服務器市場立足的背後還有其他因素。ARM 的內核以低功耗和高密度爲目標。與英特爾和 AMD 不同,它們不會嘗試涵蓋廣泛的功率和性能目標。這種專業化讓 ARM 創建了適合雲應用程序的更高核心數的芯片,同時保持在可接受的功率和成本目標範圍內。該專業化通過犧牲矢量量和峰值性能,從而使用較小的矢量單元和密集設計那些沒有那么高時鐘速度的單元。Prodigy 具有比任何 x86 芯片更大的矢量單元和更高的時鐘,因此它很有可能不會像 ARM 內核那樣縮減到低功耗。
如果 Prodigy 沒有達到如此高的時鐘,我認爲他們沒有明確的方法來搶佔服務器市場的一部分。他們不太可能在高密度市場上超越 ARM。如果沒有巨大的時鐘速度優勢,它們不太可能在低线程工作負載中擊敗 x86 內核。並且當 Tachyum 致力於讓 Prodigy 被流片出來時,沒有人會坐以待斃。AMD 正在准備發布基於 Zen 4 的 Genoa 和 Bergamo。後者將擁有 128 個 Zen 4 核心,並減少緩存設置,與 Prodigy 的核心數量相匹配。Ampere Computing 正在开發 Altra 的繼任者,它可能具有超過 128 個內核。Prodigy 當然會保留矢量量優勢,但矢量量並不是服務器市場的決定性因素,就像 HPC 和 AI 一樣。
結論
技術趨勢通常是循環的。幾十年前,服務器、客戶端系統和超級計算機慢慢融合以使用類似的硬件。例如,在 2000 年代後期,AMD 的六核 K10 芯片在客戶端系統中作爲 Phenom X6 提供服務,在服務器和超級計算機中作爲 Opteron 2435 提供服務。但在過去十年中,這種趨勢一直在緩慢逆轉。超級計算機通常使用 GPU 加速來提高量,而針對 HPC 的 GPU 架構和針對客戶端平台的架構之間的差異越來越大。Ampere 和亞馬遜已經爲雲計算優化了專門的服務器芯片。英特爾和 AMD 在所有三個類別中仍然使用相同的架構,但即使這樣,它們也在定制芯片以適應不同的市場。例如,服務器形式的 Skylake 將額外的 L2 和矢量單元附加到核心上,並使用網狀互連。AMD 計劃以第二種形式發布 Zen 4,名爲 Zen 4c,它以緩存容量換取核心數量,應該更適合雲計算。
Tachyum 的 Prodigy 代表了逆勢而上的勇敢嘗試。它將 GPU 的矢量量與 CPU 的單线程性能相結合,但代價是高功耗。然而,我們仍然懷疑 Tachyum 如何在面臨所有障礙的情況下實現這一切。我們確實向 Tachyum 詢問了他們是如何實現 500mm2 的 CPU 的,雖然我們無法透露他們告訴我們的內容,但我們仍然對他們在 N5 上實現這一點持懷疑態度,因爲他們不僅擁有大量矢量單元,還由於芯片上有大量的 DDR5 和 PCIe 5的 PHY,導致的大規模模擬電路的數量。
即使 Prodigy 按計劃進入市場,它也將面臨激烈的競爭老牌玩家及其專業產品。使用單一架構服務於不同的細分市場將使 Tachyum 能夠利用其有限的工程資源擴大其業務範圍。但是,除了專注於工程工作之外,該策略並沒有太多優勢。你不能僅僅因爲兩者都使用相同的芯片,就讓服務器充當 HPC 節點的雙重職責。超級計算集群具有極高速的網絡和分布式存儲,因此節點可以一起解決同一個問題。數據中心不會有同樣的高速網絡,因爲響應互聯網請求不需要幾乎一樣多的帶寬。最後,Tachyum將面臨一場艱苦的战鬥,以建立圍繞其ISA的軟件生態系統,同時在途中遭受二進制翻譯處罰。對於一家小型初創公司來說,要處理很多事情,我們祝他們好運。
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:叫板Intel、AMD和Nvidia的最通用CPU,延期了!但是……
地址:https://www.breakthing.com/post/53030.html