






一文讀懂大廠大模型。
來源 | 定 焦 作者 | 溫 故 出品 | 投資人說(touzirenshuo)

今年以來,整個科技圈最熱鬧的事情,是發布大模型。
從3月百度率先發布文心一言以來,阿裏、科大訊飛、360、騰訊紛紛跟上。
7月,華爲、京東、攜程也召开發布會,雖遲但到。
科技公司又卷起來了。
以至於某頭部互聯網大廠的技術負責人,在一場發布會开場就強調:
“今天不會發布預訓練多模態大模型,今天也不會蹭大模型的熱點。”
7月17日下午,在攜程發布旅遊行業垂直大模型後,除了極個別藏着掖着的互聯網大廠,大廠大模型基本集結完畢。
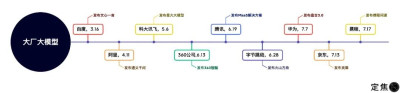 中國大廠大模型發布時間线 制圖 / 定焦
中國大廠大模型發布時間线 制圖 / 定焦
大模型越來越多,雖出自大廠,但真假難辨。
大家的招數也不同,有的迷戀“作詩”,有的埋頭“做事”,還有的“講故事”。
根據資源能力、布局深度、出招套路,大廠的大模型可以分爲不同的流派。
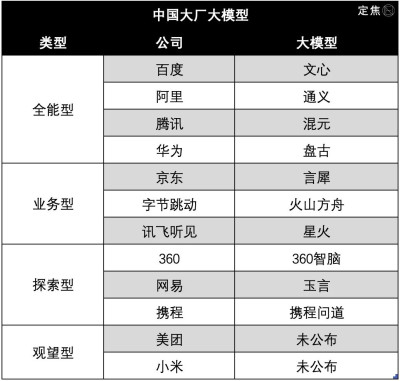
我們將它們總結爲四大類型:
全能型:百度、阿裏、騰訊、華爲
業務型:京東、字節跳動、科大訊飛
探索型:360、網易、攜程
觀望型:美團、小米
業界普遍認爲,第一梯隊當屬百度、阿裏、騰訊、華爲四家,它們的綜合實力最強。
京東、字節跳動、科大訊飛位列第二梯隊,業務屬性較重;
360、攜程、網易還在探索階段;
美團、小米還沒有發布大模型。
當然,這個分類是動態的。
行業變化太快,大廠的進展也是一日千裏,格局隨時可能改寫。
接下來,我們就帶大家探討一下,大廠的大模型都長啥樣,哪家的大模型最強,以及,大廠大模型,拼什么?
01
兩條路线,三個層級在討論大廠大模型之前,我們先做一個背景科普。
首先,大模型不是新鮮事物。
它不是突然蹦出來的,只是被ChatGPT帶火了。
在去年11月底ChatGPT問世之前,百度、阿裏、騰訊、華爲等大廠就有自己的大模型,而且經常在一些國際測評類榜單中刷榜。
具體到大模型的類別,有兩條大的路线,一是通用,二是垂直。
所謂“通用”,可以簡單理解爲大模型啥都會;
“垂直”,是在某個特定領域做的特別好。
這其中的差別,就像一個高中生畢業了,基本的能力素養都有,但沒啥專業性;
另一個是職高畢業,綜合能力差點,但可能工地搬磚有一手,或修車修的好。
ChatGPT,以及百度文心一言、阿裏通義千問,都是通用大模型,能聊天、寫詩、作畫,看起來比較全能。
但你要讓它去做專業的在线問診、物流規劃,可能做得很一般。
與之對應,像華爲推出的礦山大模型、實時預測全球海浪的大模型,以及京東金融行業大模型,主打的就是“做事”和“專業”。
這兩條路线,是我們理解大模型的基礎,也決定了大廠在布局大模型賽道時的战略方向。
那么,不論是通用大模型還是垂直大模型,企業具體能做什么?
百度創始人兼CEO李彥宏曾給過創業公司一個建議:
沒有必要再重新做基礎大模型,創業者的機會是在應用層,將出現“全新的、十倍於現在微信和抖音的創業機遇”。
先拋开這個觀點的立場,這裏提到了“基礎大模型”和“應用層”。
這就涉及到大模型的三個層級。
中國大模型的創業生態,玩家都在不同層級進行站位——架構層、模型層、應用層。
架構層的進入門檻最高,功能有點類似基礎設施,能參與進來的主要是各大雲計算廠商,比如阿裏、騰訊、百度、華爲這四巨頭。
模型層的一大重點是基礎大模型,對算力、算法、數據、人才的要求非常高,一般的創業公司做不了。
有一些公司選擇在基礎大模型之上做一些微調,針對性推出行業大模型。
應用層是基於前兩類大模型,調用API开發應用,就像手機行業基於安卓和iOS开發APP,這是大部分創業公司能做的事情。
大衆熟知的ChatGPT,其實是OpenAI對GPT-3模型微調後开發出來的對話機器人應用。 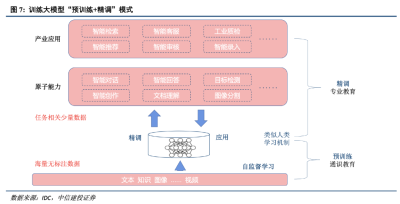
中國的科技公司在布局時,尤其是BAT這樣的超級巨頭,往往會交叉覆蓋三大層級。
基礎打法是先發布通用大模型或者行業大模型底座,其他公司再基於這些基礎模型,結合自身擁有的行業數據,微調出自己的大模型應用。
因爲ChatGPT的火爆,很多人將大模型理解爲一個應用或一款產品,是不太准確的。
大模型正在形成一個生態,這其中有修高速公路的,有蓋房子的,還有搞精裝修的。
有野心的頭部大廠想拿下壁壘最高、賽道最寬闊的架構層和模型層,但難度和風險系數極大,很可能投入之後看不到成果。
中部大廠更多選擇在一些垂直行業深耕,先在具體場景落地,看到效果之後再加大投入。
更多的大廠其實還在探索階段,一邊觀望一邊行進,摸着石頭過河。
02
大廠的招式與武功隨着互聯網大廠陸續發布大模型,大廠們的布局逐漸清晰起來。
我們將百度、阿裏、騰訊、華爲歸入一梯隊。
一是因爲他們在大模型上起步早,布局深;
二是因爲能力全面。
百度是國內第一個推出聊天機器人產品,开放內測,硬剛ChatGPT的公司。
再把時間往前推四年,百度在2019年3月就對標谷歌BERT模型,推出了文心大模型ERNIE 1.0,中文效果超越BERT。
這個模型在2021年12月參數達千億,跨入“智能湧現”門檻。
ERNIE 3.0 Zeus也是國內首個开放API調用的千億大模型。
阿裏在今年4月11日發布對標ChatGPT的大語言模型通義千問,快速接入釘釘、天貓精靈,然後在3個月內推出了聚焦音頻的大模型應用通義聽悟,以及AI繪畫大模型通義萬相,通義大模型家族日漸成型。
如此快節奏,是因爲阿裏把准備工作做到位了。
阿裏很早就發布了語言大模型Plug和多模態大模型M6,M6在2021年10月參數規模達10萬億,是當時全球最大的AI預訓練模型。
這兩個模型在去年9月合並,發展爲今天的通義大模型。
騰訊直到今年6月下旬才召开發布會,是大廠中相對較晚的一個,而且它沒有像百度、阿裏一樣發布通用大模型,而是面向B端客戶發布了行業大模型解決方案。
華爲也是一樣,它在7月7日發布面向行業的盤古大模型3.0,沒有發布聊天機器人。
騰訊和華爲的硬實力都很強。
騰訊在去年4月發布了混元大模型,這是一個集計算機視覺和自然語言處理於一體的多模態大模型,已經在騰訊各大業務模塊中應用。
華爲的盤古大模型早在2021年4月就發布了,還落地了一些具體的場景。
這波AI2.0浪潮,很多能力都是建立在雲平台之上。
不論是算力、模型,還是工具鏈,都是通過雲平台對外輸出。
在此基礎上,大公司建設大模型生態,支撐更多應用生長,是一套比較高級的打法,目前能玩轉的也就這四家大廠。
二梯隊的京東、字節跳動、科大訊飛,我們將之歸入“業務型”選手,因爲他們的能力側重模型層,更看中跟業務結合。
比如京東,7月13日京東推出AI大模型“言犀”,這是一個面向產業的垂直大模型,側重解決真實場景的實際問題。
過去這些年京東除了在電商賣貨,物流、金融、健康等業務也發展起來了,所以“言犀”大模型一开始主要面向零售、金融、城市、健康和物流領域。
早期自用爲主,後期向外部客戶开放。
再比如科大訊飛。
“星火認知大模型”在5月6日發布,同時發布的還有其在教育、辦公、汽車、數字員工方向的落地應用,還將接入學習機、錄音轉寫工具“訊飛聽見”等產品。
字節跳動的玩法比較特別,它在6月28日發布了“火山方舟”。
注意,這不是大模型,官方說法是“企業級大模型服務平台”。
簡言之就是一個大模型超市,字節不生產大模型,只“搬運”大模型。
這三家大廠,在做業務方面都很有一手。
對他們而言,大模型更多是一個工具,先在自己內部跑通,把效率提上來,看到實實在在的效果後,再考慮加大投入推廣。
三梯隊的360、網易、攜程,大模型還在探索階段。
這其中360可能不服氣,自從ChatGPT火了之後,低調了很久的“紅衣教主”周鴻禕突然又活躍起來,頻頻發表言論。
已經包裝成“數字安全公司”的360,在6月13日發布“360智腦大模型”和一款數字人產品。
不過,雖然產品功能豐富,但外界對360大模型的技術水平存疑。
360自稱前期在AIGC技術一直有投入,去年還發起了計劃投資總額2.23億元的項目,半年過去了,募來的錢只投了5%。
攜程和網易在大模型上的布局,目前還不是很系統。
網易聲稱從2021年开始打造“玉知”多模態理解大模型,借助了華爲昇騰AI的力量,在行業裏存在感不強。
攜程發布旅遊行業垂直大模型“攜程問道”,出發點是提升內部各大業務的工作效率。
美團和小米沒有發布大模型,但內部已經啓動相關項目。
美團最新的動態是接盤王慧文的光年之外,這對美團的大模型業務實際有多大幫助,尚待觀察。
03
大廠大模型,拼什么這么多大模型,怎么評估好壞?
上半年的“百模大战”中,中國大廠們在推出自家大模型時,都喜歡拿參數量說事。
ChatGPT已經證明了大模型存在“湧現”現象,大模型的參數量越大,智能程度越高。
這是一個非常粗暴的指標。
阿裏、百度等大廠幾年前就推出過萬億參數的大模型,但參數大和能力強是兩回事。
另外一個常用的評價維度是公开的評測集和榜單打分,中國的大廠非常喜歡參與。
比如騰訊,騰訊的混元大模型去年發布後,參加了很多榜單排名,在MSR-VTT,MSVD,LSMDC,DiDeMo和ActivityNet五大跨模態視頻檢索數據集榜單中,先後取得第一名的成績,實現了跨模態檢索領域的大滿貫,分數更是打破多項紀錄。
百度的文心大模型,過去幾年也經常登頂全球權威的GLUE榜單,甚至超過微軟、谷歌、OpenAI等公司。
最近IDC發布了大模型評估報告,百度文心大模型在7項核心指標上拿下滿分,綜合評分第一。
這個方式的局限性在於,會導致出現一些“應試型選手”,測評分數跟實際表現相差較遠。
國內一家AI創業公司的創始人季定宇對我們說,“大模型是綜合能力的體現,所有的測評都不能體現全部”,“在刷榜這件事上,大廠們就沒有輸過”。
當一個新的風口出現時,創業者和資本一擁而上,導致信息差普遍存在。
尤其是在早期階段,外界缺乏足夠的辨別力,這個時候誰的聲量大,誰就能獲得更高的關注度。
華爲的盤古大模型推出兩年來,普通人知之甚少。
ChatGPT火了之後,盤古大模型迅速升級到3.0版本,並再次重磅向外界發布。
盛景嘉成董事總經理劉迪對我們說:“對於大廠而言,當大家都在發布大模型時,你是不能缺席的。因爲GPT的影響,大廠很被動地將原來可能計劃在2-3年做的事情,壓縮到三個月快速地做出來。”
這就像一場賽跑,大家都在搶跑,顧不上姿勢和動作是否優雅。
對一些大廠而言,把什么產品、哪塊能力拿出來發布,是一道選擇題。
大廠也要迎合熱點、造勢、包裝。
开發布會更多是一個宣傳行爲,真正的功夫是在台下,在幕後。
爲了突出自身優勢,很多大廠會對標GPT,用“在指標前加定語”的方式來作對比,尤其是“中文能力”這項指標。
但目前,從C端用戶反饋來看,用戶量最大、體驗最好的,依然是ChatGPT。
劉迪認爲,從商業模式上,大廠很難將大模型包裝成類似微信這種,大範圍使用的付費C端產品,因爲算力太稀缺。
現在的算力用來做微調和日常的B端業務處理都已經很緊,C端的量一旦上來,大廠支撐不住。
這導致的結果是,賣算力資源的雲廠商,搶先一步喫到了大模型的紅利。
提前囤了超過1萬張英偉達GPU的字節跳動,直到現在也沒有推出自己的大模型。
在大廠發布大模型最熱鬧的4月,它旗下的算力平台火山引擎,推出了自研DPU等系列雲產品(DPU是一種定制化的加速硬件),支持萬卡級大模型訓練。
字節跳動選擇爲其他大模型公司提供算力服務,雙方的關系就像微軟和OpenAI、亞馬遜和Bedrock。
火山引擎總裁譚待稱,國內大模型領域的數十家企業,超過七成已經在火山引擎雲上。
綜合來看,大模型賽道還處在早期階段,大廠們雖然發布了產品,但搶跑的意味很濃。
因爲賽道夠長,一時的搶跑無法形成長期優勢。
而且,行業變化迭代太快,技術、產品都可能隨時重新洗牌。
短暫的聲量之爭過後,才會進入比拼硬實力的階段。
04
誰最有可能勝出從年初至今,大家對大模型的認識在逐漸發生變化。
年初,行業裏的共識是,通用大模型是未來。
大家覺得,通用大模型在各個場景都有很好表現,可以解決一切問題。
大廠中,已經發布類ChatGPT產品的有百度、阿裏、科大訊飛、360。
後來,大家發現這些產品更像是玩具。
它們擅長坐而論道,你跟它們聊天沒問題,但要讓它們幹具體的活,可能不太靠譜。
大廠迅速捕捉到了市場的變化。
百度就發現,文心一言發布後,一开始來交流的企業都是CEO級別的人出面,後來大多是技術負責人或業務負責人。
字節跳動發現,來找火山引擎的企業,四五月份都是模型廠商,需求是訓練模型,現在是一些行業客戶,希望在營銷、客服等場景落地。
於是下半年,風向變了。
行業迅速達成新的共識:行業大模型更靠譜,要從通用面向產業。
大廠對外講故事的口徑也隨之變化,紛紛开始發布行業大模型。
騰訊在6月下旬推出行業“精選模型商店”時,騰訊雲與智慧產業事業群CEO湯道生說,“聊天機器人不是唯一的大模型服務方式,也不一定是滿足行業需求的最優解。”
華爲7月上旬發布的盤古大模型3.0是面向行業,華爲常務董事、華爲雲CEO張平安稱,華爲的盤古大模型不寫詩,要扎根於行業,爲各個行業帶來價值。
京東的“言犀”大模型定位直接就是面向產業。
京東雲事業部總裁曹鵬說,對話類的通用大模型不應該是大模型的全部,大模型不應該只是拿來聊天寫詩作畫的玩具。
在diss通用大模型的同時,這三家大廠开始在“產業”上大做文章,凸顯自己的優勢。
他們的產品,均主要面向To B行業市場。
劉迪認爲,對於大廠而言,大模型有兩個價值:
一是內部做節流,把優化的效率轉化成利潤;
二是對外拓客,讓其他客戶賺到錢,大廠從中拿走合理的利潤。最終一定要商業化。
“拋开技術指標,評價一個模型好不好用,就看用的人多不多。一看收費客戶數量,二看創造的收入金額。”
MaaS模式(Models as a Service,模型即服務)开始被更多大廠搬到台面上。
去年的雲棲大會,以及今年的百度文心一言發布會,都提到了這一概念。
騰訊則公布了MaaS能力全景圖。
就像當年的雲計算市場一樣,底層算力和平台能力可以構建壁壘,市場需要算力強悍、模型全面的服務商。
那些在算力、平台、模型、應用方面都有布局的大廠,對企業客戶具備更強吸引力。
百度、阿裏、華爲,除了自研大模型產品,還完成了從芯片到應用的布局。
百度是“昆侖芯+飛槳平台+文心大模型”,阿裏是“含光800芯片+M6-OFA底座+通義大模型”,華爲是“昇騰芯片+MindSpore框架+盤古大模型”,這是其他公司在短期內很難追上的優勢。
季定宇認爲,在中國做通用大模型的公司,最終只能跑出一家,做個好的比早做出來更有價值。
“我最看好字節跳動和騰訊,一個是團隊符合,一個是場景符合。”
劉迪更看好三家大廠——美團、字節跳動、華爲。
他對我們分析:美團是基於場景去找業務,基於C端用戶高頻的交易數據,能快速迭代模型;
華爲主打生態圈,在G端資源強大,具備極強的拿行業數據的能力;
字節跳動之前已經將很多AI技術應用到自家產品中,迭代能力極強。
不過,這都是基於現階段的理論分析,行業格局具體會如何演變,還要看大廠們接下來如何出招接招。
畢竟,大模型的賽道才剛剛鋪开。
· END ·
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:大廠混战大模型:四大流派,沒有贏家
地址:https://www.breakthing.com/post/81329.html